关注公众号不迷路:DumpStack
扫码加关注

目录
调度是一个庞大的模块,涉及的知识点很多,下面我们来简单梳理一下
X、调度器
调度器决定了将哪个进程放到CPU上执行,以及执行多长时间。操作系统进行合理的进程调度,使得资源得到最大化的利用。调度器需要合理的分配CPU时间给运行的进程,创造一种所有进程并行运行的错觉,这就对调度器提出了要求:
-
调度器分配给task的时间不能太长,否则会导致其他的程序响应延迟,难以保证公平性
-
调度器分配给task的时间也不能太短,因为每次调度会导致上下文切换,这种切换开销也很大,即频繁的上下文切换导致调度器的吞吐量下降
X、进程与线程
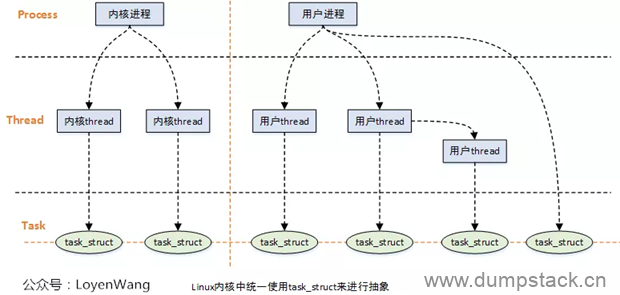
从教科书上,我们都能知道:
-
进程是资源分配的最小单位,而线程是CPU调度的的最小单位
-
进程不仅包括可执行程序的代码段,还包括一系列的资源,比如:打开的文件、内存、CPU时间、信号量、多个执行线程流等等。而线程可以共享进程内的资源空间
-
在Linux内核中,进程和线程都使用struct task_struct结构来进行抽象描述
-
进程的虚拟地址空间分为用户虚拟地址空间和内核虚拟地址空间,所有进程共享内核虚拟地址空间,没有用户虚拟地址空间的进程称为内核线程
X、I/O消耗型和CPU消耗型(IO bound和CPU bound)
如果进程大部分时间都在请求I/O请求,则这个进程称之为I/O消耗型,比如键盘,这种类型的进程经常处于可以运行的状态,但是都只是运行一点点时间,绝大多数的时间都在处于阻塞(睡眠)的状态
如果进程的绝大多数都在使用CPU做运算的话,那么这种进程称之为CPU消耗型,比如开启Matlab做一个大型的运算,没有太多的I/O需求,从系统响应的角度上来讲,调度器不应该经常让他们运行。对于处理器消耗型的进程,调度策略往往是降低他们的执行频率,延长运行时间。
Linux系统为了提升响应的速度,倾向于优先调度I/O消耗型。
X、进程的状态
1.1 状态说明
1.1.1 R (task_running) : 可执行状态
只有在该状态的进程才可能在CPU上运行。而同一时刻可能有多个进程处于可执行状态,这些进程的task_struct结构(进程控制块)被挂在对应CPU的可执行链表上,一个进程最多只能出现在一个CPU的可执行链表上。调度器的任务就是从各个CPU的可执行链表上选择一个进程在该CPU上运行。
很多操作系统教科书将正在CPU上执行的进程定义为RUNNING状态,而将可执行但是尚未被调度执行的进程定义为READY状态,这两种状态在linux下统一为TASK_RUNNING状态。
1.1.2 S (task_interruptible) : 可中断的睡眠状态
处于这个状态的进程因为等待某事件的发生(比如等待socket连接、等待信号量)而被挂起,这些进程的task_struct结构被放入对应事件的等待队列中,当要等待的事件发生时,对应的等待队列中的一个或多个进程将被唤醒。
通过ps命令我们会看到,一般情况下,进程列表中的绝大多数进程都处于task_interruptible状态(除非机器的负载很高)。毕竟CPU就这么一两个,进程动辄几十上百个,如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来。
1.1.3 D (task_uninterruptible) : 不可中断的睡眠状态
与task_interruptible状态类似,进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,并不是说CPU不响应外部硬件的中断,而是指进程不响应异步信号。
绝大多数情况下,进程处在睡眠状态时,总是应该能够响应异步信号的,但是uninterruptible sleep状态的进程不接受外来的任何信号,因此无法用kill杀掉这些处于D状态的进程,这种情况下,一个可选的方法就是reboot。
处于uninterruptible sleep状态的进程通常是在等待IO,比如磁盘IO,网络IO,其他外设IO,如果进程正在等待的IO在较长的时间内都没有响应,那么就被ps看到了,同时也就意味着很有可能有IO出了问题,可能是外设本身出了故障,也可能是比如挂载的远程文件系统已经不可访问了
而task_uninterruptible状态存在的意义就在于:内核的某些处理流程是不能被打断的,如果响应异步信号,那么程序的执行流程中就会被插入一段用于处理异步信号的流程(这个插入的流程可能只存在于内核态,也可能延伸到用户态),于是原有的流程就被中断了。
1.1.4 Z (task_dead - exit_zombie) : 退出状态,进程成为僵尸进程
在Linux进程的状态中,僵尸进程是非常特殊的一种,它是已经结束了的进程,但是没有从进程表中删除。太多了会导致进程表里面条目满了,进而导致系统崩溃,但是不占用其他系统资源。
它已经放弃了几乎所有内存空间,没有任何可执行代码,也不能被调度,仅仅在进程列表中保留一个位置,记载该进程的退出状态等信息供其他进程收集,除此之外,僵尸进程不再占有任何内存空间。
进程在退出的过程中,处于TASK_DEAD状态,在这个退出过程中,进程占有的所有资源将被回收,除了task_struct结构(以及少数资源)以外。于是进程就只剩下task_struct这么个空壳,故称为僵尸。
之所以保留task_struct,是因为task_struct里面保存了进程的退出码、以及一些统计信息,而其父进程很可能会关心这些信息。比如在shell中,$?变量就保存了最后一个退出的前台进程的退出码,而这个退出码往往被作为if语句的判断条件。
子进程在退出的过程中,内核会给其父进程发送一个信号,通知父进程来"收尸"。父进程可以通过wait系列的系统调用(如wait4、waitid)来等待某个或某些子进程的退出,并获取它的退出信息。然后wait系列的系统调用会顺便将子进程的尸体(task_struct)也释放掉。
这个信号默认是SIGCHLD,在通过clone系统调用创建子进程时,可以设置这个信号,如果他的父进程没安装SIGCHLD信号处理函数调用wait或waitpid等待子进程结束,又没有显式忽略该信号,那么它就一直保持僵尸状态,子进程的尸体(task_struct)也就无法释放掉。
如果这时父进程结束了,那么init进程自动会接手这个子进程,为它收尸,它还是能被清除的。但是如果如果父进程是一个循环,不会结束,那么子进程就会一直保持僵尸状态,这就是为什么系统中有时会有很多的僵尸进程。
当进程退出的时候,会将它的所有子进程都托管给别的进程(使之成为别的进程的子进程)。托管的进程可能是退出进程所在进程组的下一个进程(如果存在的话),或者是1号进程。所以每个进程、每时每刻都有父进程存在,除非它是1号进程。
1号进程,即pid为1的进程,又称init进程。linux系统启动后,第一个被创建的用户态进程就是init进程,它有两项使命:
-
执行系统初始化脚本,创建一系列的进程(它们都是init进程的子孙);
-
在一个死循环中等待其子进程的退出事件,并调用waitid系统调用来完成"收尸"工作;
init进程不会被暂停、也不会被杀死(这是由内核来保证的),它在等待子进程退出的过程中处于task_interruptible状态,"收尸"过程中则处于task_running状态。
1.1.5 X (task_dead - exit_dead) : 退出状态,进程即将被销毁
进程在退出过程中也可能不会保留它的task_struct,比如这个进程是多线程程序中被detach过的进程,或者父进程通过设置sigchld信号的handler为sig_ign,显式的忽略了sigchld信号,(这是posix的规定,尽管子进程的退出信号可以被设置为sigchld以外的其他信号。)
此时,进程将被置于exit_dead退出状态,这意味着接下来的代码立即就会将该进程彻底释放。所以exit_dead状态是非常短暂的,几乎不可能通过ps命令捕捉到。
1.2 进程状态变化说明
1.6.1 进程的初始状态
用户空间可以通过fork系列的系统调用(fork、clone、vfork)来创建的进程,内核中也可以通过kernel_thread函数创建内核进程。这些创建子进程的函数本质上都完成了相同的功能——将调用进程复制一份,得到子进程。(可以通过选项参数来决定各种资源是共享、还是私有)。
那么既然调用进程处于task_running状态(否则,它若不是正在运行,又怎么进行调用?),则子进程默认也处于task_running状态。
另外,在系统调用调用clone和内核函数kernel_thread也接受clone_stopped选项,从而将子进程的初始状态置为task_stopped。
1.6.2 进程状态变迁
进程自创建以后,状态可能发生一系列的变化,直到进程退出。而尽管进程状态有好几种,但是进程状态的变迁却只有两个方向:即从task_running状态变为非task_running状态、或者从非task_running状态变为task_running状态。
也就是说,如果给一个task_interruptible状态的进程发送sigkill信号,这个进程将先被唤醒(即先进入task_running状态),然后再响应sigkill信号而退出(变为task_dead状态)。并不会从task_interruptible状态直接退出。
进程从非task_running状态变为task_running状态,是由别的进程(也可能是中断处理程序)执行唤醒操作来实现的。执行唤醒的进程设置被唤醒进程的状态为task_running,然后将其task_struct结构加入到某个cpu的可执行队列中,于是被唤醒的进程将有机会被调度执行。
而进程从task_running状态变为非task_running状态,则有两种途径:
-
响应信号而进入task_stoped状态、或task_dead状态;
-
执行系统调用主动进入task_interruptible状态(如nanosleep系统调用)、或task_dead状态(如exit系统调用);或由于执行系统调用需要的资源得不到满足,而进入task_interruptible状态或task_uninterruptible状态(如select系统调用)。
显然,这两种情况都只能发生在进程正在cpu上执行的情况下。
1.3 状态机
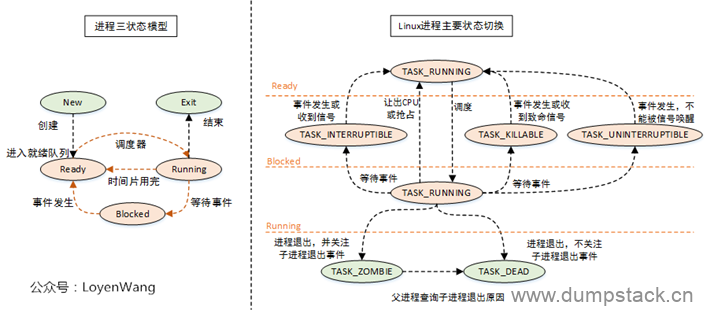
上图中左侧为操作系统中通俗的进程三状态模型,右侧为Linux对应的进程状态切换。
Linux中的就绪态和运行态对应的都是TASK_RUNNING标志位,就绪态表示进程正处在队列中,尚未被调度;运行态则表示进程正在CPU上运行;
内核中主要的状态字段定义如下
|
/* Used in tsk->state: */ #define TASK_RUNNING 0x0000 #define TASK_INTERRUPTIBLE 0x0001 #define TASK_UNINTERRUPTIBLE 0x0002
/* Used in tsk->exit_state: */ #define EXIT_DEAD 0x0010 #define EXIT_ZOMBIE 0x0020 #define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)
/* Used in tsk->state again: */ #define TASK_PARKED 0x0040 #define TASK_DEAD 0x0080 #define TASK_WAKEKILL 0x0100 #define TASK_WAKING 0x0200 #define TASK_NOLOAD 0x0400 #define TASK_NEW 0x0800 #define TASK_STATE_MAX 0x1000
/* Convenience macros for the sake of set_current_state: */ #define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE) #define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED) #define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED)
#define TASK_IDLE (TASK_UNINTERRUPTIBLE | TASK_NOLOAD) |
X、uid|pid|tgid|ppid
x.1 uid - 和pc机中的uid不是同一个概念
注意:安卓中的uid和pc机器上的uid是不一样的
在PC机上,uid用于标记用户,每个用户都有一个uid,是哪个用户启动的程序,这个程序的uid就是哪个用户
但是在Android中,uid用于标识一个应用程序,每个程序都有一个uid,这个uid是在程序安装的时候被分配的,并且在应用存在于手机上期间,都不会改变。一个应用程序只能有一个uid,多个应用可以使用sharedUserId方式共享同一个uid,前提是这些应用的签名要相同。
默认情况下Android会给每个程序分配一个普通级别且互不相同的uid,如果应用之间要互相调用或者共享数据,只能是uid相同才行,这就使得共享数据具有了一定安全性,每个软件之间是不能随意获得数据的。而同一个app只有一个uid,所以app下的Activity之间不存在访问权限的问题。
最后需要注意的是,一个应用只有一个uid,但是可以有多个pid(通过process属性来指定进程)。
uid: android中uid用于标识一个应用程序,uid在应用安装时被分配,并且在应用存在于手机上期间,都不会改变。一个应用程序只能有一个uid,多个应用可以使用sharedUserId方式共享同一个uid,前提是这些应用的签名要相同。
pid: 进程ID,可变的
gid: 对应于linux中用户组的概念,android中gid等于uid
gids:个GIDS相当于一个权限的集合,一个UID可以关联GIDS,表明该UID拥有多种权限
一个进程就是host应用程序的沙箱,里面一般有一个UID和多个GIDS,每个进程只能访问UID的权限范围内的文件和GIDs所允许访问的接口,构成了Android最基本的安全基础。
x.1.1 uid的分配
|
// uid 的分配 // Returns -1 if we could not find an available UserId to assign private int newUserIdLPw(Object obj) { // Let's be stupidly inefficient for now... final int N = mUserIds.size(); //从0开始,找到第一个未使用的ID,此处对应之前有应用被移除的情况,复用之前的ID for (int i = mFirstAvailableUid; i < N; i++) { if (mUserIds.get(i) == null) { mUserIds.set(i, obj); return Process.FIRST_APPLICATION_UID + i; } }
//最多只能安装 9999 个应用 // None left? if (N > (Process.LAST_APPLICATION_UID-Process.FIRST_APPLICATION_UID)) { return -1; }
mUserIds.add(obj); // 可以解释为什么普通应用的UID 都是从 10000开始的 return Process.FIRST_APPLICATION_UID + N; } |
x.1.1 通过uid共享数据实例
假设我们有这样一个需求,A和B是两个应用,现在要求在A中获取B的一张名字为icon_home的图片资源(以Drawable实例的形式呈现),那我们可以考虑将A和B的注册文件的manifest节点添加sharedUserId,并且赋值相同,然后在A中可以用如下方式实现:
|
Context subContext = null; try { //首先根据B应用的包名获取其上下文,注意这个方法是Context的,如果没找到会抛出异常 subContext = createPackageContext("com.geo.plugin", Context.CONTEXT_IGNORE_SECURITY); } catch (NameNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } //然后根据上下文获取资源 Resources res = subContext.getResources(); //然后根据图片的名字获取其id int menuIconId = res.getIdentifier("icon_home", "drawable", "com.geo.plugin"); //最后根据id生产Drawable实例 Drawable drawable = res.getDrawable(menuIconId); |
x.1.1 如何实现两个应用uid共享?
首先需要在两个应用的AndroidManifest.xml中都定义相同的sharedUserId,如:android:sharedUserId="com.test";
定义后可以通过adb shell cat data/system/packages.list(限于eng或userdebug版)进行确认两个应用的uid是否相同了。
输出结果如下,证明uid已经是一样了。
|
com.example.testdatabase 10124 1 /data/data/com.example.testdatabase default none com.example.test_6_3_database 10124 1 /data/data/com.example.test_6_3_database default none |
x.1.2 怎样查看uid
x.1.2.1 方法一:通过PS命令
这个u0_a245就表示:该应用是user0(主用户)下面的应用,id是245,前面说过普通应用程序的uid都是从10000开始的,所以最终计算出的uid就是10245

多用户情况下的uid计算类似:

可以看到工作用户的userID是14,后面是一样的,计算方式是:100000 * 14 + 10106 = 1410106
|
/** * Returns the uid that is composed from the userId and the appId. * @hide */ public static int getUid(@UserIdInt int userId, @AppIdInt int appId) { if (MU_ENABLED) {//是否支持多用户 //PER_USER_RANGE 为 100000 return userId * PER_USER_RANGE + (appId % PER_USER_RANGE); } else { return appId; } } |
x.1.2.2 方法二:通过/proc/[pid]/status接口查看
首先通过ps命令得到进程的pid号,下面第二列就是pid,此处我们以2061为例

然后通过cat /proc/2061/status命令,可以得到uid信息
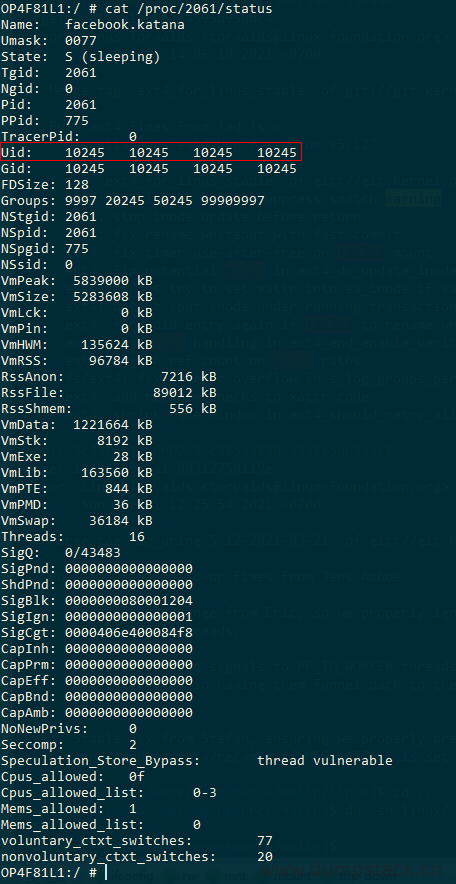
x.1.2.3 方法三:通过/data/system/packages.list文件
如果手机有root权限的话,可以读取/data/system/packages.list文件,里面可以看到所有应用的包名及对应的uid

x.2 gid - 用户所在的组id
用户所在的组的id
可使用id命令查看uid和gid,如下:

x.3 pid - 线程id
PID,即Process Identification,进程标识符,每个进程有唯一的PID编号
x.4 tgid - 标记线程所属的进程
pid用于标记线程,tgid用于标记这个线程所属的进程,一个进程下面所有线程的tgid相同,主进程的pid和tgid是一样的
x.4 ppid - 父进程id
代表当前进程的父进程id
X、进程的优先级
对于cfs进程来说,优先级越低,vruntime时间变化越快,这将导致进程只要运行一点点时间,vruntime就会变化很大,在pick进程的时候就不容易被pick到
3.1 nice值 - 仅针对cfs进程 - [-20, 19]
nice值和动态优先级prio的关系如下:
每个cfs进程都有自己的nice值,(rt进程没有,因为nice是cfs中的概念),它不是进程的优先级,而是一个能影响优先级的数字,nice值的范围是[-20, 19],默认的default值为0;
可以通过ps -el查看系统中进程列表,如下,NI列显示的每个进程的nice值,PRI是进程的优先级。
|
[hupu@HUC ~/data/work/git/code/explore/kernel]$ ps -el F S UID PID PPID C PRI 4 S 0 1 0 0 80 0 - 9619 - ? 00:00:02 systemd 1 S 0 2 0 0 80 0 - 0 - ? 00:00:00 kthreadd 1 S 0 3 2 0 80 0 - 0 - ? 00:00:00 ksoftirqd/0 1 S 0 5 2 0 60 -20 - 0 - ? 00:00:00 kworker/0:0H 1 S 0 7 2 0 80 0 - 0 - ? 00:00:02 rcu_sched 1 S 0 8 2 0 80 0 - 0 - ? 00:00:00 rcu_bh 1 S 0 9 2 0 -40 - - 0 - ? 00:00:00 migration/0 5 S 0 10 2 0 -40 - - 0 - ? 00:00:00 watchdog/0 5 S 0 11 2 0 80 0 - 0 - ? 00:00:00 kdevtmpfs 1 S 0 12 2 0 60 -20 - 0 - ? 00:00:00 netns 1 S 0 13 2 0 60 -20 - 0 - ? 00:00:00 perf 1 S 0 14 2 0 80 0 - 0 - ? 00:00:00 khungtaskd |
目前的内核不再存储nice值,取而代之的是静态优先级static_prio,nice值用户可见,静态优先级则隐藏在内核中,nice值和静态优先级static_prio可通过一定的关系进行转换,所以说nice值只是影响了静态优先级static_prio。而对于普通进程来说,动态优先级prio是基于静态优先级static_prio算出来的。
3.2 静态优先级 - static_prio - 仅针对cfs进程 - [100, 139]
之所以称为静态优先级是因为它不会随着时间而改变,内核不会修改它,只能通过用户空间的nice系统调用去修改。静态优先级用task_struct中的static_prio表示,nice与static_prio之间的关系如下:
|
static_prio = MAX_RT_PRIO + nice + 20
其中: MAX_RT_PRIO值为100 |
内核定义了两个宏用来完成nice值和静态优先级static_prio的转换:
|
/* * Convert user-nice values [ -20 ... 0 ... 19 ] * to static priority [ MAX_RT_PRIO..MAX_PRIO-1 ], * and back. */ #define NICE_TO_PRIO(nice) ((nice) + DEFAULT_PRIO) #define PRIO_TO_NICE(prio) ((prio) - DEFAULT_PRIO) |
3.3 动态优先级(优先级) - prio - [0, 139]
调度器通过增加或减少进程静态优先级的值,来奖励IO消耗型进程或惩罚cpu消耗型进程,调整后的优先级称为动态优先级,在task_struct中用prio表示,通常所说的优先级指的是动态优先级。
动态优先级的取值范围为[0, MAX_PRIO-1],其中MAX_PRIO=140,其中[0, MAX_RT_PRIO-1]属于rt进程范围,[MAX_RT_PRIO, MX_PRIO-1]属于cfs进程(也称普通进程),其中MAX_RT_PRIO=100。
prio数值越大,表示进程优先级越小。
普通进程的优先级通过一个关于静态优先级和进程交互性函数关系计算得到,随实际任务的实际运行情况得到
3.4 实时优先级 - rt_priority - 仅针对rt进程 - [0, 99]
实时优先级只针对rt进程,是可配置的,默认情况下的范围是0~99,即[0, MAX_RT_PRIO-1],实时优先级记录在进程描述符rt_priority中
实时优先级rt_priority和动态优先级prio关系如下,因此与nice值相反,越高的实时优先级数值代表着越高的优先级。与此同时,任何实时进程的优先级都高于普通进程的优先级。
|
prio = MAX_RT_PRIO - 1 – rt_priority
=> rt_priority = MAX_RT_PRIO -1 – prio |
3.5 Linux实时线程优先级问题 - 数值越大优先级越高吗?
今天查看了linux下的实时线程,FIFO和RR策略的调度,遇到一个问题:priority越大优先级越高呢?还是越小越高呢?
回答这个问题要明白一个问题,首先,linux2.6内核将任务优先级进行了一个划分:
|
进程种类 |
优先级范围 |
|
实时进程 |
0 ~ 99 |
|
非实时进程/普通进程 |
100 ~ 139 |
现在,这个划分是起决定作用的,而且一定是数值越小,优先级越高。但是,有时候从网上会看到优先级数值越大,优先级越高!这又是怎么回事?难道有一种说法错了吗?
实际的原因是这样的,对于一个实时进程,他有两个参数来表明优先级:prio和rt_priority
prio才是调度器所用的最终优先级数值,这个值越小,优先级越高;
而rt_priority被称作实时进程优先级,他要经过转化:
|
prio = MAX_RT_PRIO - 1- task_struct->rt_priority |
其中MAX_RT_PRIO = 99,这样意味着rt_priority值越大,prio值越小,优先级越高;
而内核提供的修改优先级的函数,是修改rt_priority的值,所以越大,优先级越高。
所以用户在使用实时进程或线程,在修改优先级时,就会有"优先级值越大,优先级越高的说法",也是对的。
X、current宏 - CPU当前正在运行的进程的task_struct结构
x.1 ARM32 - 保存在thread_info中
W:\opensource\linux-4.19.81\include\asm-generic\current.h
|
#define get_current() (current_thread_info()->task) #define current get_current() |
x.1.1 arm32 - thread_info保存在栈空间
W:\opensource\linux-4.19.81\arch\arm\include\asm\thread_info.h
|
/* * how to get the current stack pointer in C */ //直接获取当前sp寄存器的值 register unsigned long current_stack_pointer asm ("sp");
/* * how to get the thread information struct from C */ static inline struct thread_info *current_thread_info(void) { return (struct thread_info *) (current_stack_pointer & ~(THREAD_SIZE - 1)); }
#define THREAD_SIZE_ORDER 1 #define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER) /* 8K */ #define THREAD_START_SP (THREAD_SIZE - 8) |
x.1.1 arm64 - thread_info保存在task_struct结构中
W:\opensource\linux-4.19.81\include\linux\thread_info.h
|
#ifdef CONFIG_THREAD_INFO_IN_TASK /* * For CONFIG_THREAD_INFO_IN_TASK kernels we need <asm/current.h> for the * definition of current, but for !CONFIG_THREAD_INFO_IN_TASK kernels, * including <asm/current.h> can cause a circular dependency on some platforms. */ #include <asm/current.h> #define current_thread_info() ((struct thread_info *)current) #endif |
x.2 ARM64 - 保存在sp_el0寄存器中
W:\opensource\linux-4.19.81\arch\arm64\include\asm\current.h
|
/* * We don't use read_sysreg() as we want the compiler to cache the value where * possible. */ static __always_inline struct task_struct *get_current(void) { unsigned long sp_el0;
asm ("mrs %0, sp_el0" : "=r" (sp_el0));
return (struct task_struct *)sp_el0; }
#define current get_current() |
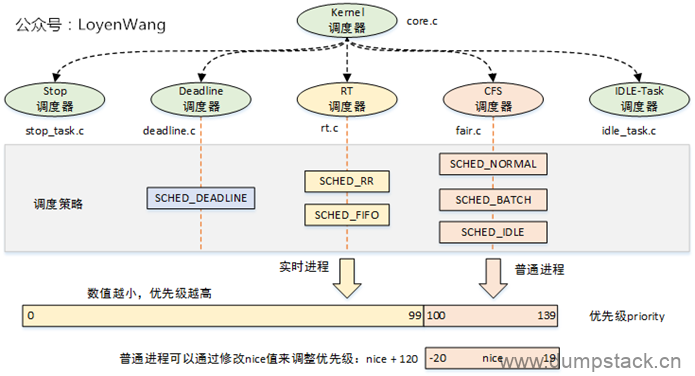
X、调度类
从Linux2.6.23开始,Linux引入调度类的概念,目的是将调度器模块化,也提高了扩展性,这也使得添加一个新的调度器变得简单,Linux将调度器公共的部分抽象,使用sched_class结构体描述一个具体的调度类。
1.2 5种调度类
内核默认提供了5种调度器,具体如下图所示
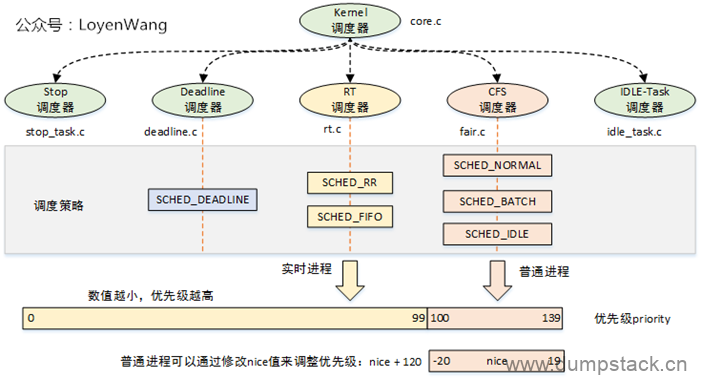
对这5种调度类的描述如下:
|
调度器 |
数据结构 |
描述 |
|
Stop |
stop_sched_class |
优先级最高的调度类,可以抢占其他所有进程,不能被其他进程抢占 |
|
Deadline |
dl_sched_class |
使用红黑树,把进程按照绝对截止期限进行排序,选择最小进程进行调度运行 |
|
RT |
rt_sched_class |
实时调度器,为每个优先级维护一个队列 |
|
CFS |
fair_sched_class |
完全公平调度器,采用完全公平调度算法,引入虚拟运行时间概念 |
|
IDLE |
idle_sched_class |
空闲调度器,每个CPU都会有一个idle线程,当没有其他进程可以调度时,调度运行idle线程 |
1.3 调度类的组织结构
内核中的所有调度类按照优先级的顺序,通过sched_class->next链表连接起来,组织结构如下:
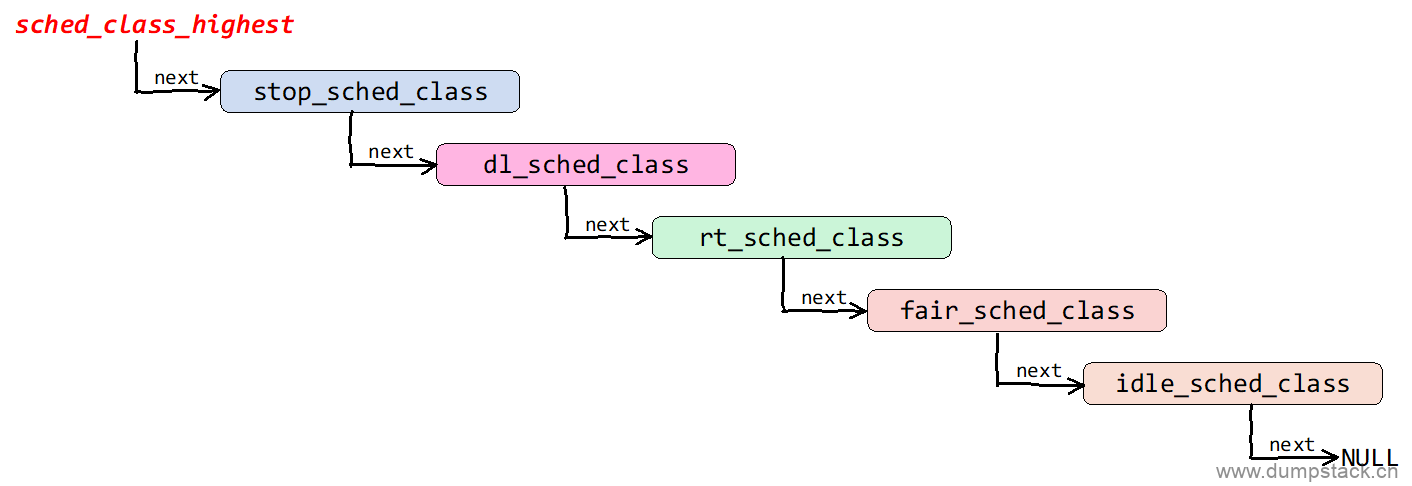
上面的组织结构是在各个sched_class定义的时候确定,具体如下
|
const struct sched_class stop_sched_class = { .next = &dl_sched_class, .enqueue_task = enqueue_task_stop, .dequeue_task = dequeue_task_stop, ... }
const struct sched_class dl_sched_class = { .next = &rt_sched_class, .enqueue_task = enqueue_task_dl, .dequeue_task = dequeue_task_dl, ... }
const struct sched_class rt_sched_class = { .next = &fair_sched_class, .enqueue_task = enqueue_task_rt, .dequeue_task = dequeue_task_rt, ... }
const struct sched_class fair_sched_class = { .next = &idle_sched_class, .enqueue_task = enqueue_task_fair, .dequeue_task = dequeue_task_fair, ... }
const struct sched_class idle_sched_class = { //全局变量没有指定就是NULL /* .next is NULL */ /* no enqueue/yield_task for idle tasks */
/* dequeue is not valid, we print a debug message there: */ .dequeue_task = dequeue_task_idle, ... } |
1.4 for_each_class - 遍历系统中的sched_class
sched_class_highest指向系统中优先级最高的调度类,使用for_each_class宏遍历系统中的所有调度类,实现如下:
|
#define sched_class_highest (&stop_sched_class) #define for_each_class(class) \ for (class = sched_class_highest; class; class = class->next) |
X、调度策略
调度策略记录在task_struct->policy中
1.1 6种调度策略
用户空间的程序通过指定调度策略,达到选择调度类的目的,(除了Stop和IDLE调度器,因为这两个调度器仅供内核使用,用户无法进行选择)。对调度策略的描述如下:
|
调度策略 |
描述 |
|
SCHED_DEADLINE |
deadline,限期进程调度策略,使task选择Deadline调度器来调度运行 |
|
SCHED_RR |
rt,实时进程调度策略,时间片轮转,进程用完时间片后加入优先级对应运行队列的尾部,把CPU让给同优先级的其他进程 |
|
SCHED_FIFO |
rt,实时进程调度策略,先进先出调度没有时间片,没有更高优先级的情况下,只能等待主动让出CPU |
|
SCHED_NORMAL |
cfs,普通进程调度策略,使task选择CFS调度器来调度运行,可抢占其他cfs进程,具体参见check_preempt_wakeup实现 |
|
SCHED_BATCH |
cfs,普通进程调度策略,批量处理,使task选择CFS调度器来调度运行,不可抢占其他cfs进程 |
|
SCHED_IDLE |
cfs,普通进程调度策略,使task以最低优先级选择CFS调度器来调度运行,不可抢占其他cfs进程 |
1.2 调度类和调度策略的对应关系
每一个进程都对应一种调度策略,每一种调度策略又对应一种调度类,但是每一个调度类可以对应多种调度策略。每一个进程在创建之后,总是要选择一种调度策略,针对不同的调度策略,选择的调度器也是不一样的,调度器和调度策略的对应关系如下:
|
调度器 |
调度策略 |
使用范围 |
说明 |
|
Stop |
无 |
最高优先级的进程,优先级比deadline还要高 |
可抢占任何进程 用于负载均衡机制中的进程迁移、softlockup检测、cpu热插拔、RCU等 |
|
Deadline |
SCHED_DEADLINE |
最高优先级的实时进程 优先级为-1 |
用于调度有严格时间要求的进程,例如视频编解码进程 |
|
RT |
SCHED_RR SCHED_FIFO |
普通的实时进程 优先级为0~99 |
用于普通的实时进程,如IRQ线程化 |
|
CFS |
SCHED_NORMAL SCHED_BATCH SCHED_IDLE |
普通进程 优先级为100~139 |
由CFS来调度 |
|
IDLE |
无 |
最低优先级的进程 |
当就绪队列中没有其他进程时,则进入idle调度类,idle调度类会让cpu进入低功耗模式 |
|
注意:为什么SCHED_IDLE是属于CFS调度类的,而不是idle调度类呢?
CFS调度类实际上有三种调度策略:
目前的CFS调度器,SCHED_NORMAL和SCHED_BATCH基本是一样的(仅仅在yield CPU时候处理不同),SCHED_IDLE是很有意思的策略,不过,标准内核并没有真正实现SCHED_IDLE任务的语义,具体的实现逻辑是:
从这个角度看,所有的CFS任务,无论是SCHED_NORMAL、SCHED_BATCH、还是SCHED_IDLE,都是在标准CFS框架下运作的。例如当一个SCHED_NORMAL和SCHED_IDLE放置到一个cpu runqueue的时候,SCHED_NORMAL并不会一直执行,SCHED_IDLE也会占据一定的CPU时间,只不过很短 |
1.3 怎样查看进程的调度策略
怎样查看一个任务使用的调度策略呢?使用下面ps命令,可以打印sched调度策略
|
ps -AT -o pid,tid,sched,ni,cmd,gid | grep 8192 |
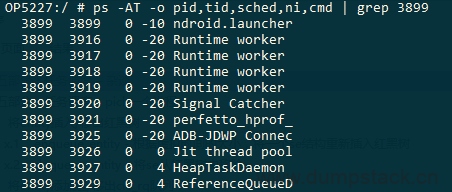
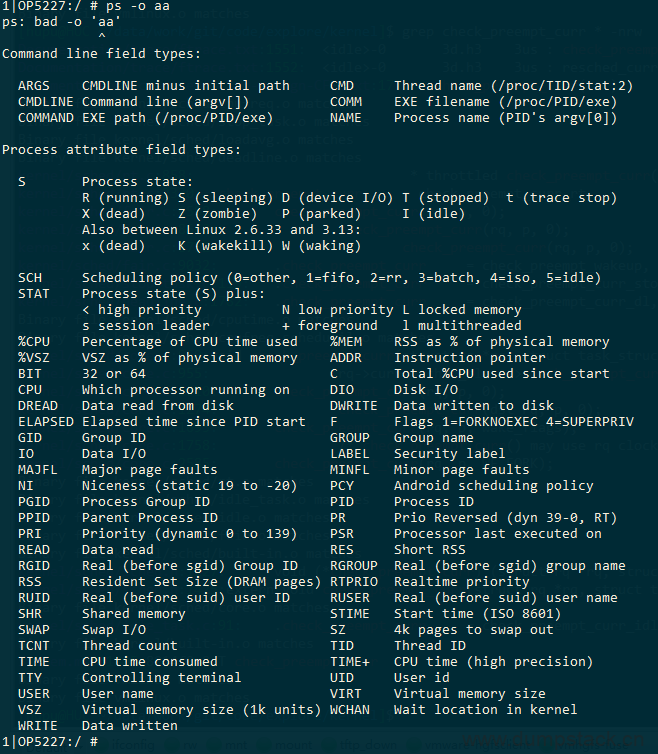
ps -o可接参数如下,随便输入一个错误的参数,便可输出帮助信息
1.4 用户框架安怎样设置调度策略
用户空间通过sched_setscheduler系统调用来设置进程的调度策略,函数原型如下:
|
int sched_setscheduler(pid_t pid, int policy, const struct sched_param *param); int sched_getscheduler(pid_t pid); |
pid用于指定进程,policy指定调度策略,可用如下
|
SCHED_OTHER SCHED_BATCH SCHED_IDLE SCHED_FIFO SCHED_RR |
sched_param定义如下,用于指定优先级,rt为0~99,cfs为100~139
|
struct sched_param { int sched_priority; }; |
使用示例如下,下面示例将进程设置为rt的SCHED_FIFO调度策略的最高优先级运行
|
#include <sched.h>
int main(int argc,char *argv[]) { struct sched_param param; int maxpri;
//获取rt进程的SCHED_FIFO调度策略的最高优先级 maxpri = sched_get_priority_max(SCHED_FIFO); if(maxpri == -1) { perror("sched_get_priority_max() failed"); exit(1); }
//将当前进程的优先级设置为rt的最高优先级运行 param.sched_priority = maxpri; if (sched_setscheduler(getpid(), SCHED_FIFO, ¶m) == -1) { perror("sched_setscheduler() failed"); exit(1); } } |
X、带宽控制
带宽控制,是用于控制用户组的CPU带宽,通过设置每个用户组的限额值,可以调整CPU的调度分配。在给定周期内,当用户组消耗CPU的时间超过了限额值,该用户组内的任务将会受到限制。
x.1 cfs_bandwidth
先看一下/sys/fs/cgroup/cpu下的内容吧:
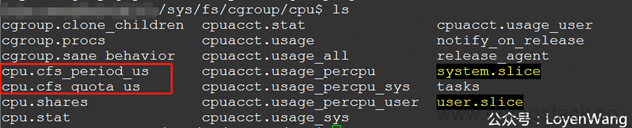
有两个关键的字段:cfs_period_us和cfs_quota_us,这两个与cfs_bandwidth息息相关;
period表示周期,quota表示限额,也就是在period期间内,用户组的CPU限额为quota值,当超过这个值的时候,用户组将会被限制运行(throttle),等到下一个周期开始被解除限制(unthrottle);
来一张图直观理解一下:

在每个周期内限制在quota的配额下,超过了就throttle,下一个周期重新开始;
x.1.1 初始化流程
先看一下初始化的操作,初始化函数init_cfs_bandwidth本身比较简单,完成的工作就是将struct cfs_bandwidth结构体进程初始化。
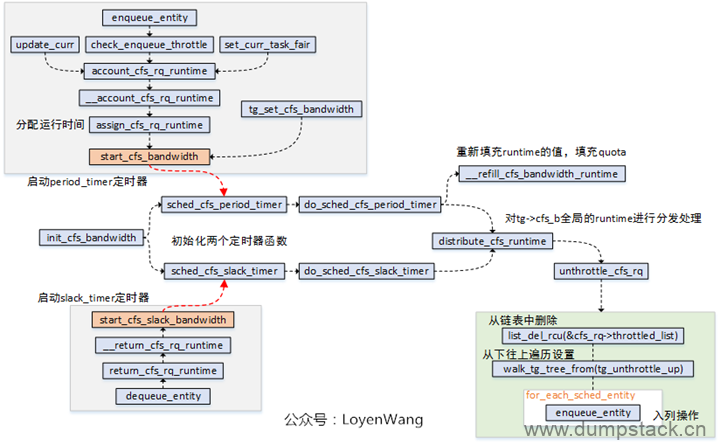
注册两个高精度定时器:period_timer和slack_timer;
period_timer定时器,用于在时间到期时重新填充关联的任务组的限额,并在适当的时候unthrottlecfs运行队列;
slack_timer定时器,slack_period周期默认为5ms,在该定时器函数中也会调用distribute_cfs_runtime从全局运行时间中分配runtime;
start_cfs_bandwidth和start_cfs_slack_bandwidth分别用于启动定时器运行,其中可以看出在dequeue_entity的时候会去利用slack_timer,将运行队列的剩余时间返回给tg->cfs_b这个runtime pool;
unthrottle_cfs_rq函数,会将throttled_list中的对应cfs_rq删除,并且从下往上遍历任务组,针对每个任务组调用tg_unthrottle_up处理,最后也会根据cfs_rq对应的sched_entity从下往上遍历处理,如果sched_entity不在运行队列上,那就重新enqueue_entity以便参与调度运行,这个也就完成了解除限制的操作;
do_sched_cfs_period_timer函数与do_sched_cfs_slack_timer函数都调用了distrbute_cfs_runtime,该函数用于分发tg->cfs_b的全局运行时间runtime,用于在该task_group中平衡各个CPU上的cfs_rq的运行时间runtime,来一张示意图:
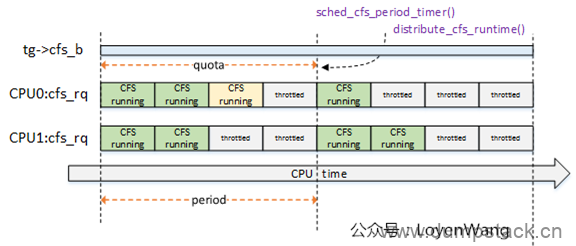
系统中两个CPU,因此task_group针对每个cpu都维护了一个cfs_rq,这些cfs_rq来共享该task_group的限额运行时间;
CPU0上的运行时间,浅黄色模块表示超额了,那么在下一个周期的定时器点上会进行弥补处理;
x.1.2 用户设置流程
用户可以通过操作/sys中的节点来进行设置:
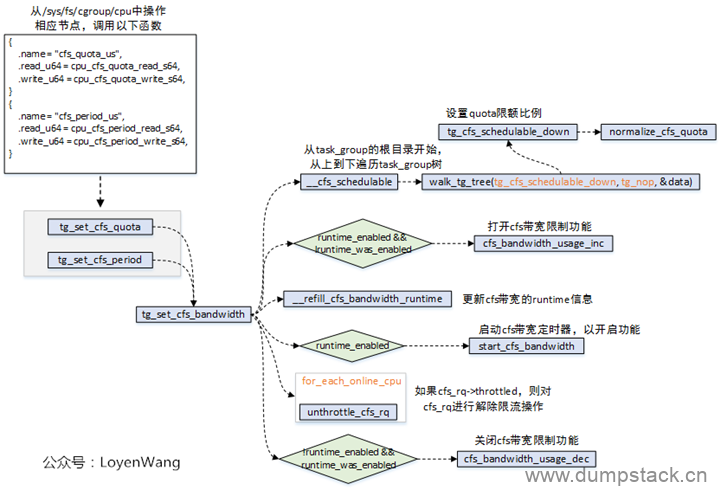
操作/sys/fs/cgroup/cpu/下的cfs_quota_us/cfs_period_us节点,最终会调用到tg_set_cfs_bandwidth函数;
tg_set_cfs_bandwidth会从root_task_group根节点开始,遍历组调度树,并逐个设置限额比率;
更新cfs_bandwidth的runtime信息;
如果使能了cfs_bandwidth功能,则启动带宽定时器;
遍历task_group中的每个cfs_rq队列,设置runtime_remaining值,如果cfs_rq队列限流了,则需要进行解除限流操作;
x.1.3 throttle限流操作
cfs_rq运行队列被限制,是在throttle_cfs_rq函数中实现的,其中调用关系如下图:
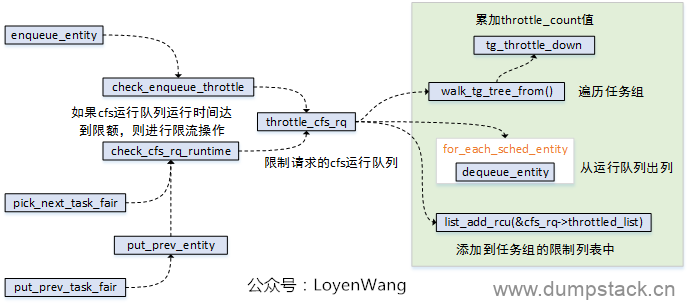
调度实体sched_entity入列时,进行检测是否运行时间已经达到限额,达到则进行限制处理;
pick_next_task_fair/put_prev_task_fair在选择任务调度时,也需要进行检测判断;
x.1.4 总结
总体来说,带宽控制的原理就是通过task_group中的cfs_bandwidth来管理一个全局的时间池,分配给属于这个任务组的运行队列,当超过限额的时候则限制队列的调度。同时,cfs_bandwidth维护两个定时器,一个用于周期性的填充限额并进行时间分发处理,一个用于将未用完的时间再返回到时间池中,大抵如此。
组调度和带宽控制就先分析到此,下篇文章将分析CFS调度器了,敬请期待。
x.2 rt_bandwidth?????待补充
X、不同的调度类中,进程是怎么组织的
x.1 cfs中使用红黑树
CFS维护了一个按照虚拟时间排序的红黑树,所有可运行的调度实体按照p->se.vruntime排序插入红黑树,如下图所示,最左边"已经运行了的虚拟时间"最少,最右边"已经运行了的虚拟时间"最多。
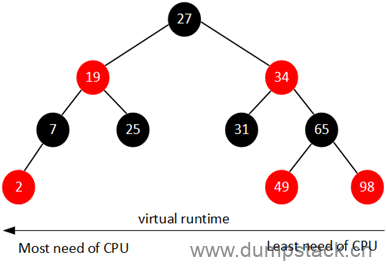
CFS始终选择红黑树最左边的进程运行,随着系统时间的推移,原来左边运行过的进程慢慢的会移动到红黑树的右边,原来右边的进程也会最终跑到最左边,因此红黑树中的每个进程都有机会运行。
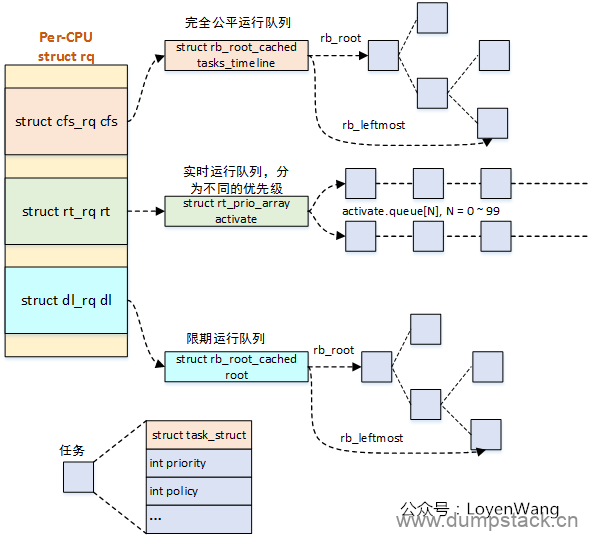
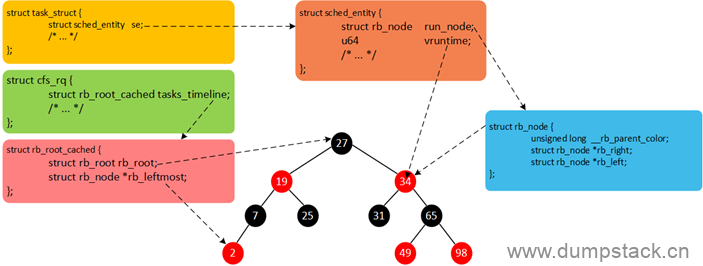
现在我们总结一下,Linux中所有的进程使用task_struct描述,task_struct包含很多进程相关的信息(例如,优先级、进程状态以及调度实体等)。但是,每一个调度类并不是直接管理task_struct,而是引入调度实体的概念,CFS调度器使用sched_entity跟踪调度信息,CFS调度器使用cfs_rq跟踪就绪队列信息以及管理就绪态调度实体,并维护一棵按照虚拟时间排序的红黑树。cfs_rq->tasks_timeline->rb_root是红黑树的根,cfs_rq->tasks_timeline->rb_leftmost指向红黑树中最左边的调度实体,即虚拟时间最小的调度实体(为了更快的选择最适合运行的调度实体,因此rb_leftmost相当于一个缓存)。每个就绪态的调度实体sched_entity包含插入红黑树中使用的节点rb_node,同时vruntime成员记录已经运行的虚拟时间。我们将这几个数据结构简单梳理,如下图所示。
x.2 rt中???????
x.3 dl中????????
X、调度时机???????待补充
x.1 主动调度 - schedule()
schedule函数,是进程调度的核心函数,大体的流程如下图所示。

核心的逻辑:选择另外一个进程来替换掉当前运行的进程。进程的选择是通过进程所使用的调度器中的pick_next_task函数来实现的,不同的调度器实现的方法不一样;进程的替换是通过context_switch()来完成切换的,具体的细节后续的文章再深入分析。
x.2 周期调度 - schedule_tick()
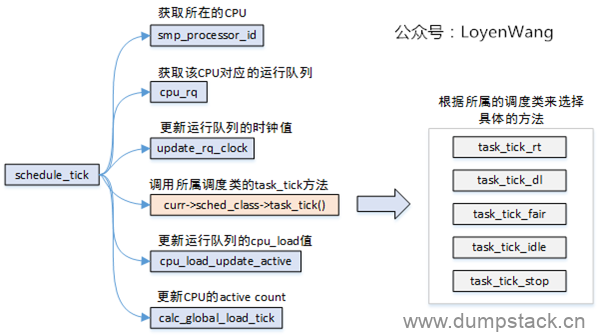
时钟中断处理程序中,调用schedule_tick()函数;
时钟中断是调度器的脉搏,内核依靠周期性的时钟来处理器CPU的控制权;
时钟中断处理程序,检查当前进程的执行时间是否超额,如果超额则设置重新调度标志(_TIF_NEED_RESCHED);
时钟中断处理函数返回时,被中断的进程如果在用户模式下运行,需要检查是否有重新调度标志,设置了则调用schedule()调度;
x.3 高精度时钟调度 - hrtick()
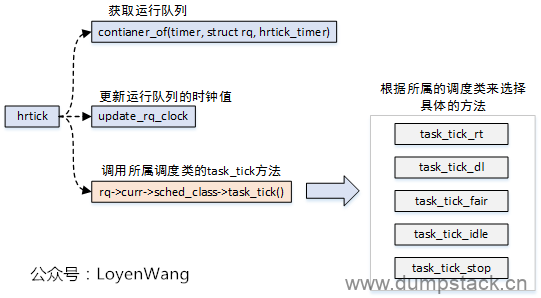
高精度时钟调度,与周期性调度类似,不同点在于周期调度的精度为ms级别,而高精度调度的精度为ns级别;
高精度时钟调度,需要有对应的硬件支持;
x.4 进程唤醒时调度 - wake_up_process()
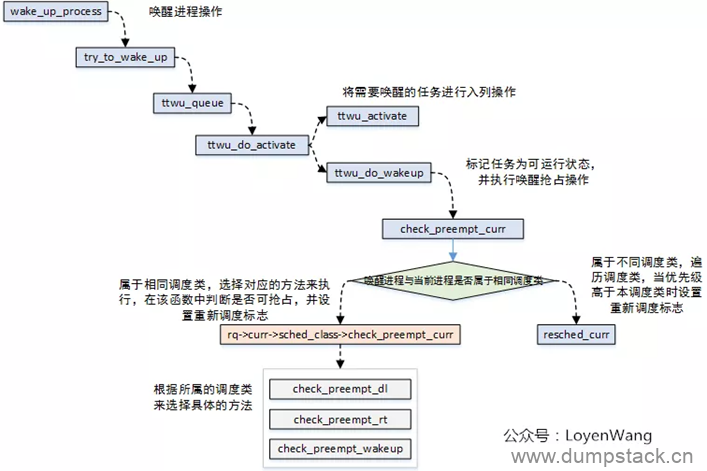
唤醒进程时调用wake_up_process()函数,被唤醒的进程可能抢占当前的进程;
上述讲到的几个函数都是常用于调度时调用。此外,在创建新进程时,或是在内核抢占时,也会出现一些调度点。
本文只是粗略的介绍了一个大概,后续将针对某些模块进行更加深入的分析,敬请期待。
X、上下文切换
进程上下文:包含CPU的所有寄存器值、进程的运行状态、堆栈中的内容等,相当于进程在某一时刻的快照,包含了所有的软硬件信息;
进程切换时,完成的就是上下文的切换,进程上下文的信息会保存在每个struct task_struct结构体中,以便在切换时能完成恢复工作;
进程上下文切换的入口就是__schedule(),分析也围绕这函数展开。
x.1 __schedule
__schedule函数调用分析如下:
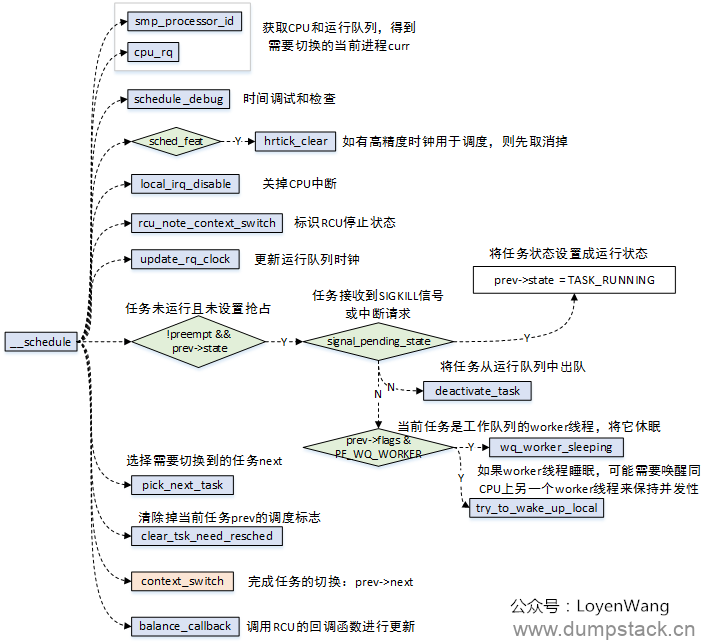
主要的逻辑:
根据CPU获取运行队列,进而得到运行队列当前的task,也就是切换前的prev;
根据prev的状态进行处理,比如pending信号的处理等,如果该任务是一个worker线程还需要将其睡眠,并唤醒同CPU上的另一个worker线程;
根据调度类来选择需要切换过去的下一个task,也就是next;
context_switch完成进程的切换;
x.2 context_switch - 真正的上下文切换
context_switch的调用分析如下:
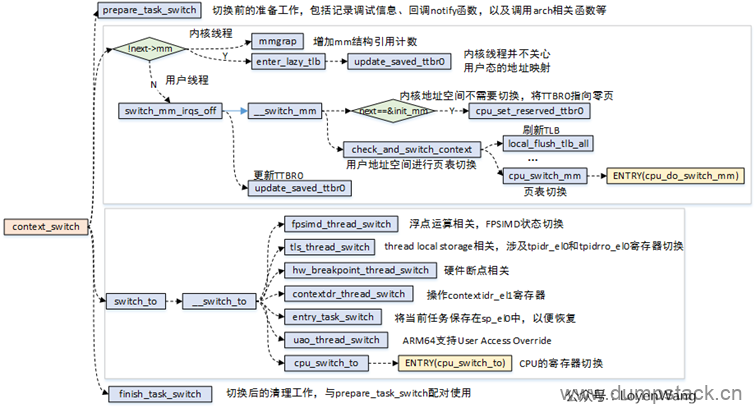
核心的逻辑有两部分:
进程的地址空间切换:切换的时候要判断切入的进程是否为内核线程,1)所有的用户进程都共用一个内核地址空间,而拥有不同的用户地址空间;2)内核线程本身没有用户地址空间。在进程在切换的过程中就需要对这些因素来考虑,涉及到页表的切换,以及cache/tlb的刷新等操作。
寄存器的切换:包括CPU的通用寄存器切换、浮点寄存器切换,以及ARM处理器相关的其他一些寄存器的切换;
进程的切换,带来的开销不仅是页表切换和硬件上下文的切换,还包含了Cache/TLB刷新后带来的miss的开销。在实际的开发中,也需要去评估新增进程带来的调度开销。

文章评论