关注公众号不迷路:DumpStack
扫码加关注

目录
- X、sched_class - 调度类
- X、task_struct - 描述一个线程
- X、sched_entity - cfs进程对应的调度实体
- X、sched_rt_entity - rt进程对应的调度实体
- X、sched_dl_entity - dl进程对应的调度实体
- X、thread_info - 平台相关,用于记录任务的信息
- X、rq - 运行队列
- X、cfs_rq - cfs调度类的就绪队列
- X、rt_rq - rt调度类的就绪队列
- X、dl_rq - dl调度类的就绪队列
- X、task_group - 描述一个任务组
- X、cfs_bandwidth - cfs带宽控制
- X、rt_bandwidth - rt带宽控制
- 关注公众号不迷路:DumpStack
X、sched_class - 调度类
|
struct sched_class { //系统中所有的调度类通过该成员链接起来,排在链表前面的优先级最高 const struct sched_class *next;
//向该调度器的runqueue链表上添加/删除一个进程,即入列/出列操作 void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags); void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*yield_task) (struct rq *rq); bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt);
//一个进程被唤醒或者创建的时候,需要检查当前进程是否可以抢占当前cpu上正在运行的进程, //如果可以抢占需要标记TIF_NEED_RESCHED void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
/* * It is the responsibility of the pick_next_task() method that will * return the next task to call put_prev_task() on the @prev task or * something equivalent. * * May return RETRY_TASK when it finds a higher prio class has runnable * tasks. */ //从runqueue中选择一个最适合运行的task,这也是调度器比较核心的一个操作, //依据什么挑选最适合运行的进程是每一个调度器需要关注的问题, //例如实时调度器以优先级为导向,选择优先级最高的进程运行 struct task_struct * (*pick_next_task) (struct rq *rq, struct task_struct *prev, struct pin_cookie cookie);
//将上一次运行的进程p重新放回链表中去 void (*put_prev_task) (struct rq *rq, struct task_struct *p);
#ifdef CONFIG_SMP int (*select_task_rq)(struct task_struct *p, int task_cpu, int sd_flag, int flags); void (*migrate_task_rq)(struct task_struct *p);
void (*task_woken) (struct rq *this_rq, struct task_struct *task);
void (*set_cpus_allowed)(struct task_struct *p, const struct cpumask *newmask);
void (*rq_online)(struct rq *rq); void (*rq_offline)(struct rq *rq); #endif
void (*set_curr_task) (struct rq *rq); void (*task_tick) (struct rq *rq, struct task_struct *p, int queued); void (*task_fork) (struct task_struct *p); void (*task_dead) (struct task_struct *p);
/* * The switched_from() call is allowed to drop rq->lock, therefore we * cannot assume the switched_from/switched_to pair is serliazed by * rq->lock. They are however serialized by p->pi_lock. */ void (*switched_from) (struct rq *this_rq, struct task_struct *task); void (*switched_to) (struct rq *this_rq, struct task_struct *task); void (*prio_changed) (struct rq *this_rq, struct task_struct *task, int oldprio);
unsigned int (*get_rr_interval) (struct rq *rq, struct task_struct *task);
void (*update_curr) (struct rq *rq);
#define TASK_SET_GROUP 0 #define TASK_MOVE_GROUP 1
#ifdef CONFIG_FAIR_GROUP_SCHED void (*task_change_group) (struct task_struct *p, int type); #endif }; |
X、task_struct - 描述一个线程
Linux内核使用task_struct结构来抽象,该结构包含了进程的各类信息及所拥有的资源,比如进程的状态、打开的文件、地址空间信息、信号资源等等。task_struct结构很复杂,下边只针对与调度相关的某些字段进行介绍。
|
struct task_struct { #ifdef CONFIG_THREAD_INFO_IN_TASK /* * For reasons of header soup (see current_thread_info()), this * must be the first element of task_struct. */ //由于历史原因:thread_info结构保存在不同的位置, //旧版本保存在栈空间,新版本保存在task_struct结构中 struct thread_info thread_info; #endif
//进程状态 volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
//栈空间 void *stack; atomic_t usage; unsigned int flags; /* per process flags, defined below */ unsigned int ptrace;
#ifdef CONFIG_SMP struct llist_node wake_entry; //该值可以为0或1,1表示这个task正在cpu上运行 int on_cpu; #ifdef CONFIG_THREAD_INFO_IN_TASK //记录当前进程运行在哪个cpu上 unsigned int cpu; /* current CPU */ #endif
//下面两个是翻转唤醒计数器 //wakee_flips是一个切换唤醒目标计数器,即当前进程作为waker时,每当waker唤醒的目标wakee变化了,wakee_flips就累加 //wakee_flips表示了当前进程作为waker时,翻转(切换)其唤醒目标wakee的次数,比如一个进程P在一段时间的唤醒顺序为:A,A,A,A,那么由于没有翻转,那么他的wakee_flips就始终为1,如果唤醒的顺序为A,B,A,A,那么由于经过两次翻转(A->B,B->A),所以他的wakee_flips的值为2 //另外,wakee_flips有一定的衰减期,如果过了1s(即1HZ的时间),那么wakee_flips就衰减为原来的1/2,这类似于PELT的指数衰减,Ns前的wakee_flips的占比大概是当前这一个窗口的1/2^N //wakee_flip_decay_ts由于记录上一次衰减的时间戳 //该变量的具体实现参见record_wakee unsigned int wakee_flips; unsigned long wakee_flip_decay_ts;
//记录当前进程作为waker,上一次唤醒了哪个进程,也就是记录上一次的wakee struct task_struct *last_wakee;
int wake_cpu; #endif //标记这个task是不是在rq队列上,可取值为: //#define TASK_ON_RQ_QUEUED 1 //#define TASK_ON_RQ_MIGRATING 2 int on_rq;
//进程优先级 //prio: 动态优先级,内核基于静态优先级做调整后的值,调度器基于该变量计算vrtime //static_prio: 静态优先级,内核不会修改,用户空间可以通过修改nice值来修改该变量 //normal_prio // rt_priority: 实时优先级,针对rt进程 int prio, static_prio, normal_prio; unsigned int rt_priority;
//进程所属的调度类 const struct sched_class *sched_class;
//注意:因为进程在不同的时期可能属于不同的调度类,所以有不同的entity struct sched_entity struct sched_rt_entity #ifdef CONFIG_CGROUP_SCHED struct task_group *sched_task_group; #endif struct sched_dl_entity
#ifdef CONFIG_PREEMPT_NOTIFIERS /* list of struct preempt_notifier: */ struct hlist_head preempt_notifiers; #endif
#ifdef CONFIG_BLK_DEV_IO_TRACE unsigned int btrace_seq; #endif
unsigned int policy;
//nr_cpus_allowed标记这个进程运行运行在几个cpu上 //cpus_allowed标记这个进程可以运行在哪几个cpu //在选核的时候,如果p->nr_cpus_allowed大于1,表示这个进程允许在多个cpu上运行 //此时需要调用select_task_rq为这个进程选择一个最合适的CPU //如果p->nr_cpus_allowed小于等于1,表示这个任务只允许在一个cpu上运行 //或者不允许在任何cpu上运行,此时通过cpumask_any选出任意一个cpu int nr_cpus_allowed; cpumask_t cpus_allowed;
#ifdef CONFIG_PREEMPT_RCU int rcu_read_lock_nesting; union rcu_special rcu_read_unlock_special; struct list_head rcu_node_entry; struct rcu_node *rcu_blocked_node; #endif /* #ifdef CONFIG_PREEMPT_RCU */ #ifdef CONFIG_TASKS_RCU unsigned long rcu_tasks_nvcsw; bool rcu_tasks_holdout; struct list_head rcu_tasks_holdout_list; int rcu_tasks_idle_cpu; #endif /* #ifdef CONFIG_TASKS_RCU */
#ifdef CONFIG_SCHED_INFO struct sched_info sched_info; #endif
struct list_head tasks; #ifdef CONFIG_SMP struct plist_node pushable_tasks; struct rb_node pushable_dl_tasks; #endif
struct mm_struct *mm, *active_mm; /* per-thread vma caching */ u32 vmacache_seqnum; struct vm_area_struct *vmacache[VMACACHE_SIZE]; #if defined(SPLIT_RSS_COUNTING) struct task_rss_stat rss_stat; #endif /* task state */ int exit_state; int exit_code, exit_signal; int pdeath_signal; /* The signal sent when the parent dies */ unsigned long jobctl; /* JOBCTL_*, siglock protected */
/* Used for emulating ABI behavior of previous Linux versions */ unsigned int personality;
/* scheduler bits, serialized by scheduler locks */ unsigned sched_reset_on_fork:1; unsigned sched_contributes_to_load:1; unsigned sched_migrated:1; unsigned sched_remote_wakeup:1; unsigned :0; /* force alignment to the next boundary */
/* unserialized, strictly 'current' */ // unsigned in_execve:1; /* bit to tell LSMs we're in execve */
//标记进程是否处于iowait状态 unsigned in_iowait:1; #if !defined(TIF_RESTORE_SIGMASK) unsigned restore_sigmask:1; #endif #ifdef CONFIG_MEMCG unsigned memcg_may_oom:1; #ifndef CONFIG_SLOB unsigned memcg_kmem_skip_account:1; #endif #endif #ifdef CONFIG_COMPAT_BRK unsigned brk_randomized:1; #endif #ifdef CONFIG_CGROUPS /* disallow userland-initiated cgroup migration */ unsigned no_cgroup_migration:1; #endif
unsigned long atomic_flags; /* Flags needing atomic access. */
struct restart_block restart_block;
//线程的pid和所属进程的tgid pid_t pid; pid_t tgid;
#ifdef CONFIG_CC_STACKPROTECTOR /* Canary value for the -fstack-protector gcc feature */ unsigned long stack_canary; #endif
//下面成员表示线程之间的组织关系 /* * pointers to (original) parent process, youngest child, younger sibling, * older sibling, respectively. (p->father can be replaced with * p->real_parent->pid) */ struct task_struct __rcu *real_parent; /* real parent process */ struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */ /* * children/sibling forms the list of my natural children */ struct list_head children; /* list of my children */ struct list_head sibling; /* linkage in my parent's children list */ struct task_struct *group_leader; /* threadgroup leader */
/* * ptraced is the list of tasks this task is using ptrace on. * This includes both natural children and PTRACE_ATTACH targets. * p->ptrace_entry is p's link on the p->parent->ptraced list. */ struct list_head ptraced; struct list_head ptrace_entry;
/* PID/PID hash table linkage. */ //因为一个线程在不同的名空间对应的pid是不一样的,这里需要一个数组来记录 struct pid_link pids[PIDTYPE_MAX]; struct list_head thread_group; struct list_head thread_node;
struct completion *vfork_done; /* for vfork() */ int __user *set_child_tid; /* CLONE_CHILD_SETTID */ int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */
cputime_t utime, stime, utimescaled, stimescaled; cputime_t gtime; struct prev_cputime prev_cputime; #ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN seqcount_t vtime_seqcount; unsigned long long vtime_snap; enum { /* Task is sleeping or running in a CPU with VTIME inactive */ VTIME_INACTIVE = 0, /* Task runs in userspace in a CPU with VTIME active */ VTIME_USER, /* Task runs in kernelspace in a CPU with VTIME active */ VTIME_SYS, } vtime_snap_whence; #endif
#ifdef CONFIG_NO_HZ_FULL atomic_t tick_dep_mask; #endif unsigned long nvcsw, nivcsw; /* context switch counts */ u64 start_time; /* monotonic time in nsec */ u64 real_start_time; /* boot based time in nsec */ /* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */ unsigned long min_flt, maj_flt;
struct task_cputime cputime_expires; struct list_head cpu_timers[3];
/* process credentials */ const struct cred __rcu *ptracer_cred; /* Tracer's credentials at attach */ const struct cred __rcu *real_cred; /* objective and real subjective task * credentials (COW) */ const struct cred __rcu *cred; /* effective (overridable) subjective task * credentials (COW) */
//线程名 char comm[TASK_COMM_LEN]; /* executable name excluding path - access with [gs]et_task_comm (which lock it with task_lock()) - initialized normally by setup_new_exec */ /* file system info */ struct nameidata *nameidata; #ifdef CONFIG_SYSVIPC /* ipc stuff */ struct sysv_sem sysvsem; struct sysv_shm sysvshm; #endif #ifdef CONFIG_DETECT_HUNG_TASK /* hung task detection */ unsigned long last_switch_count; #endif /* filesystem information */ struct fs_struct *fs; /* open file information */ struct files_struct *files; /* namespaces */ struct nsproxy *nsproxy; /* signal handlers */ struct signal_struct *signal; struct sighand_struct *sighand;
sigset_t blocked, real_blocked; sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */ struct sigpending pending;
unsigned long sas_ss_sp; size_t sas_ss_size; unsigned sas_ss_flags;
struct callback_head *task_works;
struct audit_context *audit_context; #ifdef CONFIG_AUDITSYSCALL kuid_t loginuid; unsigned int sessionid; #endif struct seccomp seccomp;
/* Thread group tracking */ u32 parent_exec_id; u32 self_exec_id; /* Protection of (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed, * mempolicy */ spinlock_t alloc_lock;
/* Protection of the PI data structures: */ raw_spinlock_t pi_lock;
struct wake_q_node wake_q;
#ifdef CONFIG_RT_MUTEXES /* PI waiters blocked on a rt_mutex held by this task */ struct rb_root pi_waiters; struct rb_node *pi_waiters_leftmost; /* Deadlock detection and priority inheritance handling */ struct rt_mutex_waiter *pi_blocked_on; #endif
#ifdef CONFIG_DEBUG_MUTEXES /* mutex deadlock detection */ struct mutex_waiter *blocked_on; #endif #ifdef CONFIG_TRACE_IRQFLAGS unsigned int irq_events; unsigned long hardirq_enable_ip; unsigned long hardirq_disable_ip; unsigned int hardirq_enable_event; unsigned int hardirq_disable_event; int hardirqs_enabled; int hardirq_context; unsigned long softirq_disable_ip; unsigned long softirq_enable_ip; unsigned int softirq_disable_event; unsigned int softirq_enable_event; int softirqs_enabled; int softirq_context; #endif #ifdef CONFIG_LOCKDEP # define MAX_LOCK_DEPTH 48UL u64 curr_chain_key; int lockdep_depth; unsigned int lockdep_recursion; struct held_lock held_locks[MAX_LOCK_DEPTH]; gfp_t lockdep_reclaim_gfp; #endif #ifdef CONFIG_UBSAN unsigned int in_ubsan; #endif
/* journalling filesystem info */ void *journal_info;
/* stacked block device info */ struct bio_list *bio_list;
#ifdef CONFIG_BLOCK /* stack plugging */ struct blk_plug *plug; #endif
/* VM state */ struct reclaim_state *reclaim_state;
struct backing_dev_info *backing_dev_info;
struct io_context *io_context;
unsigned long ptrace_message; siginfo_t *last_siginfo; /* For ptrace use. */ struct task_io_accounting ioac; #if defined(CONFIG_TASK_XACCT) u64 acct_rss_mem1; /* accumulated rss usage */ u64 acct_vm_mem1; /* accumulated virtual memory usage */ cputime_t acct_timexpd; /* stime + utime since last update */ #endif #ifdef CONFIG_CPUSETS nodemask_t mems_allowed; /* Protected by alloc_lock */ seqcount_t mems_allowed_seq; /* Seqence no to catch updates */ int cpuset_mem_spread_rotor; int cpuset_slab_spread_rotor; #endif #ifdef CONFIG_CGROUPS /* Control Group info protected by css_set_lock */ struct css_set __rcu *cgroups; /* cg_list protected by css_set_lock and tsk->alloc_lock */ struct list_head cg_list; #endif #ifdef CONFIG_FUTEX struct robust_list_head __user *robust_list; #ifdef CONFIG_COMPAT struct compat_robust_list_head __user *compat_robust_list; #endif struct list_head pi_state_list; struct futex_pi_state *pi_state_cache; #endif #ifdef CONFIG_PERF_EVENTS struct perf_event_context *perf_event_ctxp[perf_nr_task_contexts]; struct mutex perf_event_mutex; struct list_head perf_event_list; #endif #ifdef CONFIG_DEBUG_PREEMPT unsigned long preempt_disable_ip; #endif #ifdef CONFIG_NUMA struct mempolicy *mempolicy; /* Protected by alloc_lock */ short il_next; short pref_node_fork; #endif #ifdef CONFIG_NUMA_BALANCING int numa_scan_seq; unsigned int numa_scan_period; unsigned int numa_scan_period_max; int numa_preferred_nid; unsigned long numa_migrate_retry; u64 node_stamp; /* migration stamp */ u64 last_task_numa_placement; u64 last_sum_exec_runtime; struct callback_head numa_work;
struct list_head numa_entry; struct numa_group *numa_group;
/* * numa_faults is an array split into four regions: * faults_memory, faults_cpu, faults_memory_buffer, faults_cpu_buffer * in this precise order. * * faults_memory: Exponential decaying average of faults on a per-node * basis. Scheduling placement decisions are made based on these * counts. The values remain static for the duration of a PTE scan. * faults_cpu: Track the nodes the process was running on when a NUMA * hinting fault was incurred. * faults_memory_buffer and faults_cpu_buffer: Record faults per node * during the current scan window. When the scan completes, the counts * in faults_memory and faults_cpu decay and these values are copied. */ unsigned long *numa_faults; unsigned long total_numa_faults;
/* * numa_faults_locality tracks if faults recorded during the last * scan window were remote/local or failed to migrate. The task scan * period is adapted based on the locality of the faults with different * weights depending on whether they were shared or private faults */ unsigned long numa_faults_locality[3];
unsigned long numa_pages_migrated; #endif /* CONFIG_NUMA_BALANCING */
#ifdef CONFIG_ARCH_WANT_BATCHED_UNMAP_TLB_FLUSH struct tlbflush_unmap_batch tlb_ubc; #endif
struct rcu_head rcu;
/* * cache last used pipe for splice */ struct pipe_inode_info *splice_pipe;
struct page_frag task_frag;
#ifdef CONFIG_TASK_DELAY_ACCT struct task_delay_info *delays; #endif #ifdef CONFIG_FAULT_INJECTION int make_it_fail; #endif /* * when (nr_dirtied >= nr_dirtied_pause), it's time to call * balance_dirty_pages() for some dirty throttling pause */ int nr_dirtied; int nr_dirtied_pause; unsigned long dirty_paused_when; /* start of a write-and-pause period */
#ifdef CONFIG_LATENCYTOP int latency_record_count; struct latency_record latency_record[LT_SAVECOUNT]; #endif /* * time slack values; these are used to round up poll() and * select() etc timeout values. These are in nanoseconds. */ u64 timer_slack_ns; u64 default_timer_slack_ns;
#ifdef CONFIG_KASAN unsigned int kasan_depth; #endif #ifdef CONFIG_FUNCTION_GRAPH_TRACER /* Index of current stored address in ret_stack */ int curr_ret_stack; /* Stack of return addresses for return function tracing */ struct ftrace_ret_stack *ret_stack; /* time stamp for last schedule */ unsigned long long ftrace_timestamp; /* * Number of functions that haven't been traced * because of depth overrun. */ atomic_t trace_overrun; /* Pause for the tracing */ atomic_t tracing_graph_pause; #endif #ifdef CONFIG_TRACING /* state flags for use by tracers */ unsigned long trace; /* bitmask and counter of trace recursion */ unsigned long trace_recursion; #endif /* CONFIG_TRACING */ #ifdef CONFIG_KCOV /* Coverage collection mode enabled for this task (0 if disabled). */ enum kcov_mode kcov_mode; /* Size of the kcov_area. */ unsigned kcov_size; /* Buffer for coverage collection. */ void *kcov_area; /* kcov desciptor wired with this task or NULL. */ struct kcov *kcov; #endif #ifdef CONFIG_MEMCG struct mem_cgroup *memcg_in_oom; gfp_t memcg_oom_gfp_mask; int memcg_oom_order;
/* number of pages to reclaim on returning to userland */ unsigned int memcg_nr_pages_over_high; #endif #ifdef CONFIG_UPROBES struct uprobe_task *utask; #endif #if defined(CONFIG_BCACHE) || defined(CONFIG_BCACHE_MODULE) unsigned int sequential_io; unsigned int sequential_io_avg; #endif #ifdef CONFIG_DEBUG_ATOMIC_SLEEP unsigned long task_state_change; #endif int pagefault_disabled; #ifdef CONFIG_MMU struct task_struct *oom_reaper_list; #endif #ifdef CONFIG_VMAP_STACK struct vm_struct *stack_vm_area; #endif #ifdef CONFIG_THREAD_INFO_IN_TASK /* A live task holds one reference. */ atomic_t stack_refcount; #endif /* CPU-specific state of this task */ struct thread_struct thread; /* * WARNING: on x86, 'thread_struct' contains a variable-sized * structure. It *MUST* be at the end of 'task_struct'. * * Do not put anything below here! */ }; |
X、sched_entity - cfs进程对应的调度实体
|
struct sched_entity { //这个进程的负载,进程负载的最大值等于其权重 struct load_weight load; /* for load-balancing */
//用于将entity添加进红黑树 struct rb_node run_node;
//se除了挂在红黑树中,还挂在rq->cfs_tasks链表中, //该链表中挂着这个rq中的所有的cfs进程,主要是为了 //后面的均衡使用的,该链表中只会挂task se struct list_head group_node;
//on_rq标记这个se是否还在cfs_rq队列中,而cfs_rq队列包括下面两部分 // a) cfs_rq对应的红黑树 // b) cfs_rq上当前正在运行的进程cfs_rq->curr //因此cfs_rq->curr虽然已经被移出红黑树,但是其on_rq值依然为1 //另外还有一个需要注意的地方,在pick_next_task_fair操作时,并没有 //调用到dequeue_entity操作,因此被挑选到的se的on_rq值不变,依然为1 unsigned int on_rq;
//这个结构体上一次更新的时间戳, //exec是执行的意思,也就是这个进程在上一次开始运行时的时间戳 u64 exec_start;
//这个进程的整个生命周期中,运行的物理时间总和 u64 sum_exec_runtime;
//这个进程在整个生命周期中,运行的虚拟时间总和 //cfs调度器把该变量当做key,将se加入红黑树 u64 vruntime;
//记录该调度实体在本地刚被pick设置为curr的时候的sum_exec_runtime //sum_exec_runtime - prev_sum_runtime表示这个se在本次运行机会宏 //连续运行了多长时间 u64 prev_sum_exec_runtime;
//负载均衡相关 u64 nr_migrations;
#ifdef CONFIG_SCHEDSTATS //统计信息 struct sched_statistics statistics; #endif
#ifdef CONFIG_FAIR_GROUP_SCHED //任务组的深度,其中根任务组的深度为0,逐级往下增加,每增加一个group,该值加1 int depth;
//se的父节点,一定是一个group se //指向这个task所属的group对应的group se struct sched_entity *parent; /* rq on which this entity is (to be) queued: */
//se所属的cfs_rq //若entity表示group,cfs_rq表示"这个group在第N个cpu // 上的se结构"被挂在哪个cfs_rq队列中, //若entity表示task,cfs_rq表示这个se所属的cfs_rq //详见后面init_tg_cfs_entry实现 struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */ //这个se对应的cfs_rq结构 //若entity表示一个task,则my_q为NULL //若entity表示一个group,则my_q指向这个组对应的task_group // 结构中的cfs_rq[N]成员,N表示cpu编号,用于挂载这个组在这个cpu上所有任务 //entity_is_task就是根据这个变量来判断entity是表示task还是group的 //详见后面init_tg_cfs_entry实现 struct cfs_rq *my_q; #endif
#ifdef CONFIG_SMP /* * Per entity load average tracking. * * Put into separate cache line so it does not * collide with read-mostly values above. */ //用于调度实体的负载计算(`PELT`) struct sched_avg avg ____cacheline_aligned_in_smp; #endif }; |
X、sched_rt_entity - rt进程对应的调度实体
|
struct sched_rt_entity { //用于将当前任务加入到优先级队列中去 struct list_head run_list;
//设置的时间超时 unsigned long timeout;
//时间戳 unsigned long watchdog_stamp;
//时间片 unsigned int time_slice;
//标记当前se是否在rt_rq队列中,或者是rt_rq->curr //注意:rt_rq->curr已经不在队列中了 unsigned short on_rq; unsigned short on_list;
//临时用于从上往下连接RT调度实体时使用 struct sched_rt_entity *back; #ifdef CONFIG_RT_GROUP_SCHED //组调度时指向他爹 struct sched_rt_entity *parent;
/* rq on which this entity is (to be) queued: */ //se所属的运行队列 //若entity表示group,rt_rq表示"这个group在第N个cpu // 上的se结构"被挂在哪个运行队列中 //若entity表示task,rt_rq表示这个se应该被放入的运行队列 //详见后面的init_tg_rt_entry struct rt_rq *rt_rq;
/* rq "owned" by this entity/group: */ //se对应的rt_rq结构 //若entity表示一个task,则my_q为NULL //若entity表示一个group,则my_q指向这个组对应的task_group // 结构中的rt_rq[N]成员,N表示cpu编号,用于挂载这个组在这个cpu上所有任务 //entity_is_task就是根据这个变量来判断entity是表示task还是group的 //详见后面的init_tg_rt_entry struct rt_rq *my_q; #endif }; |
X、sched_dl_entity - dl进程对应的调度实体
|
struct sched_dl_entity { struct rb_node rb_node;
/* * Original scheduling parameters. Copied here from sched_attr * during sched_setattr(), they will remain the same until * the next sched_setattr(). */ u64 dl_runtime; /* maximum runtime for each instance */ u64 dl_deadline; /* relative deadline of each instance */ u64 dl_period; /* separation of two instances (period) */ u64 dl_bw; /* dl_runtime / dl_deadline */
/* * Actual scheduling parameters. Initialized with the values above, * they are continously updated during task execution. Note that * the remaining runtime could be < 0 in case we are in overrun. */ s64 runtime; /* remaining runtime for this instance */ u64 deadline; /* absolute deadline for this instance */ unsigned int flags; /* specifying the scheduler behaviour */
/* * Some bool flags: * * @dl_throttled tells if we exhausted the runtime. If so, the * task has to wait for a replenishment to be performed at the * next firing of dl_timer. * * @dl_boosted tells if we are boosted due to DI. If so we are * outside bandwidth enforcement mechanism (but only until we * exit the critical section); * * @dl_yielded tells if task gave up the cpu before consuming * all its available runtime during the last job. */ int dl_throttled, dl_boosted, dl_yielded;
/* * Bandwidth enforcement timer. Each -deadline task has its * own bandwidth to be enforced, thus we need one timer per task. */ struct hrtimer dl_timer; }; |
X、thread_info - 平台相关,用于记录任务的信息
该数据结构由平台自己定义和解析
对于每一个进程而言,内核为其单独分配了一个内存区域,这个区域存储的是内核栈和该进程所对应的一个小型进程描述符thread_info结构
之所以将thread_info结构称之为小型的进程描述符,是因为在这个结构中并没有直接包含与进程相关的字段,而是通过task字段指向具体某个进程描述符task_struct。通常这块内存区域的大小是8KB,也就是两个页的大小(有时候也使用一个页来存储,即4KB)。一个进程的内核栈和thread_info结构之间的逻辑关系如下图所示:
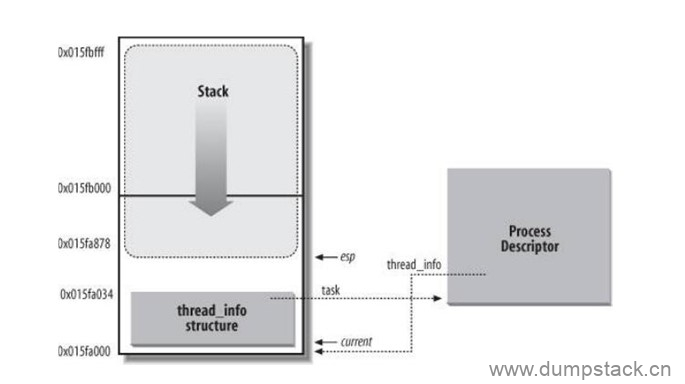
从上图可知,内核栈是从该内存区域的顶层向下(从高地址到低地址)增长的,而thread_info结构则是从该区域的开始处向上(从低地址到高地址)增长。内核栈的栈顶地址存储在esp寄存器中。所以,当进程从用户态切换到内核态后,esp寄存器指向这个区域的末端。从代码的角度来看,内核栈和thread_info结构是被定义在./linux/include/linux/sched.h中的一个联合体当中的:
|
union thread_union { #ifndef CONFIG_ARCH_TASK_STRUCT_ON_STACK struct task_struct task; #endif #ifndef CONFIG_THREAD_INFO_IN_TASK struct thread_info thread_info; #endif unsigned long stack[THREAD_SIZE/sizeof(long)]; }; |
其中,THREAD_SIZE的值取8192时,stack数组的大小为2048;THREAD_SIZE的值取4096时,stack数组的大小为1024
现在我们应该思考,为何要将内核栈和thread_info(其实也就相当于task_struct,只不过使用thread_info结构更节省空间)紧密的放在一起?最主要的原因就是内核可以很容易的通过esp寄存器的值获得当前正在运行进程的thread_info结构的地址,进而获得当前进程描述符task_struct的地址
在函数current_thread_info的实现中,定义current_stack_pointer的这条内联汇编语句会从esp寄存器中获取内核栈顶地址,和~(THREAD_SIZE - 1)做与操作将屏蔽掉低13位(或12位,当THREAD_SIZE为4096时),此时所指的地址就是这片内存区域的起始地址,也就刚好是thread_info结构的地址。但是,thread_info结构的地址并不会对我们直接有用。我们通常可以轻松的通过current宏获得当前进程的task_struct结构,前面已经列出过get_current函数的代码。current宏返回的是thread_info结构task字段,而task正好指向与thread_info结构关联的那个进程描述符。得到current后,我们就可以获得当前正在运行进程的描述符中任何一个字段了,比如我们通常所做的current->pid
x.1 arm64
arm64中对应如下
|
/* * low level task data that entry.S needs immediate access to. * __switch_to() assumes cpu_context follows immediately after cpu_domain. */ struct thread_info { //TIF_NEED_RESCHED标记就是设置在这个flags中 unsigned long flags; /* low level flags */ mm_segment_t addr_limit; /* address limit */
//主进程描述符,即该thread_info对应的task struct task_struct *task; /* main task structure */
//抢占嵌套相关,是否关抢占 int preempt_count; /* 0 => preemptable, <0 => bug */ int cpu; /* cpu */ }; |
x.2 arm32
arm32中定义如下:
|
/* * low level task data that entry.S needs immediate access to. * __switch_to() assumes cpu_context follows immediately after cpu_domain. */ struct thread_info { //TIF_NEED_RESCHED标记就是设置在这个flags中 unsigned long flags; /* low level flags */
//抢占嵌套,是否关抢占 int preempt_count; /* 0 => preemptable, <0 => bug */ mm_segment_t addr_limit; /* address limit */
//主进程描述符,即该thread_info对应的task struct task_struct *task; /* main task structure */ __u32 cpu; /* cpu */ __u32 cpu_domain; /* cpu domain */ struct cpu_context_save __u32 syscall; /* syscall number */ __u8 used_cp[16]; /* thread used copro */ unsigned long tp_value[2]; /* TLS registers */ #ifdef CONFIG_CRUNCH struct crunch_state crunchstate; #endif union fp_state fpstate __attribute__((aligned(8))); union vfp_state vfpstate; #ifdef CONFIG_ARM_THUMBEE unsigned long thumbee_state; /* ThumbEE Handler Base register */ #endif }; |
X、rq - 运行队列
Linux使用struct rq结构体描述就绪队列,它是per-cpu类型,即每个CPU上都会对应着一个就绪队列rq。per-cpu变量的定义和实现如下
|
DECLARE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues); #运行队列时一个percpu变量
#define cpu_rq(cpu) (&per_cpu(runqueues, (cpu))) #获取指定cpu上的运行队列 #define this_rq() this_cpu_ptr(&runqueues) #获取当前cpu上的运行队列 #define task_rq(p) cpu_rq(task_cpu(p)) #已知task,返回这个task所在cpu上的rq #define cpu_curr(cpu) (cpu_rq(cpu)->curr) #返回只是cpu上正在运行的task #define raw_rq() raw_cpu_ptr(&runqueues) #获取当前cpu上的运行队列 |
另外,不同的调度类也有自己的运行队列,例如cfs_rq,rt_rq,dl_rq,他们都集成在rq结构体中,因此,可以将rq看做是各个调度类的就绪队列的集合
rq结构体定义如下:
|
/* * This is the main, per-CPU runqueue data structure. * * Locking rule: those places that want to lock multiple runqueues * (such as the load balancing or the thread migration code), lock * acquire operations must be ordered by ascending &runqueue. */ struct rq { /* runqueue lock: */ raw_spinlock_t lock;
/* * nr_running and cpu_load should be in the same cacheline because * remote CPUs use both these fields when doing load calculation. */ //nr_running和nr_uninterruptible分别放了这个cpu上处于R状态和D状态的进程数量 unsigned int nr_running; #ifdef CONFIG_NUMA_BALANCING unsigned int nr_numa_running; unsigned int nr_preferred_running; #endif #define CPU_LOAD_IDX_MAX 5 unsigned long cpu_load[CPU_LOAD_IDX_MAX]; #ifdef CONFIG_NO_HZ_COMMON #ifdef CONFIG_SMP unsigned long last_load_update_tick; #endif /* CONFIG_SMP */ unsigned long nohz_flags; #endif /* CONFIG_NO_HZ_COMMON */ #ifdef CONFIG_NO_HZ_FULL unsigned long last_sched_tick; #endif /* capture load from *all* tasks on this cpu: */ //这个rq上所有进程的权重之和,一定是进程的权重,不包括se的 struct load_weight load; unsigned long nr_load_updates; u64 nr_switches;
//每个CPU上拥有的就绪队列,实际上rq就是各个调度类的就绪队列的集合 struct cfs_rq cfs; struct rt_rq rt; struct dl_rq dl;
#ifdef CONFIG_FAIR_GROUP_SCHED /* list of leaf cfs_rq on this cpu: */ struct list_head leaf_cfs_rq_list; #endif /* CONFIG_FAIR_GROUP_SCHED */
/* * This is part of a global counter where only the total sum * over all CPUs matters. A task can increase this counter on * one CPU and if it got migrated afterwards it may decrease * it on another CPU. Always updated under the runqueue lock: */ //nr_running和nr_uninterruptible分别放了这个cpu上处于R状态和D状态的进程数量 unsigned long nr_uninterruptible;
//stop指向迁移内核线程,idle指向空闲内核线程 struct task_struct *curr, *idle, *stop; unsigned long next_balance; struct mm_struct *prev_mm;
unsigned int clock_skip_update;
//这个task从开始到现在一共运行了多少个cycle u64 clock; u64 clock_task;
atomic_t nr_iowait;
#ifdef CONFIG_SMP //根组,所有cpu都一样的 struct root_domain *rd;
//这个cpu最底层(SMT层)的sched_domain结构 struct sched_domain *sd;
unsigned long cpu_capacity; unsigned long cpu_capacity_orig;
struct callback_head *balance_callback;
unsigned char idle_balance; /* For active balancing */ int active_balance; int push_cpu; struct cpu_stop_work active_balance_work;
/* cpu of this runqueue: */ //注意这里的cpu成员,是指SMT层级的thread(cpu), //如果不存在SMT层时,表示MC层的core,反正就是指向最后一个层级 //当是指SMT层级时,每个thread(cpu)对于一个rq结构 int cpu; int online;
//cfs进程的se除了挂在红黑树中,还挂在rq->cfs_tasks链表中, //该链表中挂着这个rq中的所有的cfs进程,主要是为了 //后面的均衡使用的,该链表中只会挂task se,不会挂在group se struct list_head cfs_tasks;
u64 rt_avg; u64 age_stamp; u64 idle_stamp; u64 avg_idle;
/* This is used to determine avg_idle's max value */ u64 max_idle_balance_cost; #endif
#ifdef CONFIG_IRQ_TIME_ACCOUNTING u64 prev_irq_time; #endif #ifdef CONFIG_PARAVIRT u64 prev_steal_time; #endif #ifdef CONFIG_PARAVIRT_TIME_ACCOUNTING u64 prev_steal_time_rq; #endif
/* calc_load related fields */ unsigned long calc_load_update; long calc_load_active;
#ifdef CONFIG_SCHED_HRTICK #ifdef CONFIG_SMP int hrtick_csd_pending; struct call_single_data hrtick_csd; #endif struct hrtimer hrtick_timer; #endif
#ifdef CONFIG_SCHEDSTATS /* latency stats */ struct sched_info rq_sched_info; unsigned long long rq_cpu_time; /* could above be rq->cfs_rq.exec_clock + rq->rt_rq.rt_runtime ? */
/* sys_sched_yield() stats */ unsigned int yld_count;
/* schedule() stats */ unsigned int sched_count; unsigned int sched_goidle;
/* try_to_wake_up() stats */ unsigned int ttwu_count; unsigned int ttwu_local; #endif
#ifdef CONFIG_SMP struct llist_head wake_list; #endif
#ifdef CONFIG_CPU_IDLE /* Must be inspected within a rcu lock section */ //记录当前cpu所处的C state,退出idle后将会该指针设置为NULL struct cpuidle_state *idle_state; #endif }; |
X、cfs_rq - cfs调度类的就绪队列
|
/* CFS-related fields in a runqueue */ struct cfs_rq { //该队列上所有se的权重之和 //当se入队时,会将se->load.weight累加进该值 //se出队是,会将se->load.weight从该值中移除 //具体参见account_entity_[enqueue|dequeue] struct load_weight load;
//记录该cfs_rq队列上挂载着多少个进程,这两个在支持组调度的时候含义不同 //nr_running: 只表示当前group中有多少个可运行的进程,不包括子group中的进程 //h_nr_running: 包含子group中的信息 unsigned int nr_running, h_nr_running;
//这个cfs_rq上,所有se的运行时间之和,这是一个物理时间, //单位ns,更新参见update_curr u64 exec_clock;
//记录这个cfs_rq队列上,虚拟运行时间的最小值,该值有下面两个作用 // a) 作为新的enqueue进来的进程的虚拟运行时间的基准 // b) 作为刚wakeup的进程的"奖励"的基准 //注意:cfs_rq队列 = cfs_rq红黑树 + cfs_rq->curr u64 min_vruntime; #ifndef CONFIG_64BIT u64 min_vruntime_copy; #endif
//下面成员用于保存cfs_rq对应的红黑树,并且缓存红黑树中最左侧的节点 //在Linux-4.12.12之后,这里有一个小小的改动,具体可参见bfb068892d30d //这笔提交,下面是笔者加了版本控制的宏 #if (LINUX_VERSION_CODE < KERNEL_VERSION(4, 12, 12)) //笔者注 //红黑树相关,用于挂载这个cfs_rq上的所有task struct rb_root tasks_timeline; //linux-4.9.37中这样定义
//用于缓存这个cfs_rq对应的红黑树中最左侧的节点 struct rb_node *rb_leftmost; #else //在Linux-5.x内核中: //tasks_timeline->rb_root中保存着cfs_rq的红黑树 //tasks_timeline->rb_leftmost中缓存着最左侧的节点 struct rb_root_cached tasks_timeline; //在linux-5.10.61中这样定义 #endif /* * 'curr' points to currently running entity on this cfs_rq. * It is set to NULL otherwise (i.e when none are currently running). */ //curr: 标记当前cfs_rq上正在运行的进程 //next: 有一个很急很急的进程,需要在下一次调度的时候立刻执行, // 可能是一个刚被唤醒的进程wakee,也可能是上一次抢占失败的进程 //last: 记录上一次被抢占的进程,也就是上一次的waker //skip: 在pick任务的时候,会跳过这个任务,主动放弃cpu使用权的进程 struct sched_entity *curr, *next, *last, *skip;
#ifdef CONFIG_SCHED_DEBUG unsigned int nr_spread_over; #endif
#ifdef CONFIG_SMP /* * CFS load tracking */ //当前cfs_rq上所有se的负载之和 struct sched_avg avg; u64 runnable_load_sum;
//这个cfs_rq的运行队列上,所有可运行进程的负载信息值和 unsigned long runnable_load_avg; #ifdef CONFIG_FAIR_GROUP_SCHED //指当前这个grq已经向tg->load_avg贡献的负载。因为tg是一个全局共享变量,多个cpu可能同时访问,为了避免严重的资源抢占,grq负载贡献更新的值并不会立刻加到tg->load_avg上,而是等到负载贡献大于tg_load_avg_contrib一定差值后,再加到tg->load_avg上。例如,2个cpu的系统中,cpu0上的grq初始值tg_load_avg_contrib为0,当grq每次定时器更新负载的时候并不会访问tg变量,而是等到grq的负载grp->avg.load_avg大于tg_load_avg_contrib很多的时候,这个差值达到一个数值(假设是2000),才会更新tg->load_avg为2000。然后,tg_load_avg_contrib的值赋值2000。又经过很多个周期后,grp->avg.load_avg和tg_load_avg_contrib的差值又等于2000,那么再一次更新tg->load_avg的值为4000,这样就避免了频繁访问tg变量 //因此,tg->load_avg为这个group在所有cpu上的grq的grq->tg_load_avg_contrib之和 unsigned long tg_load_avg_contrib; #endif atomic_long_t removed_load_avg, removed_util_avg; #ifndef CONFIG_64BIT u64 load_last_update_time_copy; #endif
#ifdef CONFIG_FAIR_GROUP_SCHED /* * h_load = weight * f(tg) * * Where f(tg) is the recursive weight fraction assigned to * this group. */ unsigned long h_load; u64 last_h_load_update; struct sched_entity *h_load_next; #endif /* CONFIG_FAIR_GROUP_SCHED */ #endif /* CONFIG_SMP */
#ifdef CONFIG_FAIR_GROUP_SCHED //支持组调度时,指向这个cfs_rq所属的rq结构 struct rq *rq; /* cpu runqueue to which this cfs_rq is attached */
/* * leaf cfs_rqs are those that hold tasks (lowest schedulable entity in * a hierarchy). Non-leaf lrqs hold other higher schedulable entities * (like users, containers etc.) * * leaf_cfs_rq_list ties together list of leaf cfs_rq's in a cpu. This * list is used during load balance. */ int on_list; struct list_head leaf_cfs_rq_list;
//CFS运行队列所属的任务组 struct task_group *tg; /* group that "owns" this runqueue */
#ifdef CONFIG_CFS_BANDWIDTH //CFS运行队列中使用CFS带宽控制 //周期计时器使能 int runtime_enabled;
//到期的运行时间 //周期计时器到期时间 u64 runtime_expires;
//剩余的运行时间 s64 runtime_remaining;
//限流时间相关 u64 throttled_clock, throttled_clock_task; u64 throttled_clock_task_time;
//throttled:限流,throttle_count:CFS运行队列限流次数 int throttled, throttle_count;
//运行队列限流链表节点,用于添加到cfs_bandwidth结构中的cfttle_cfs_rq链表中 struct list_head throttled_list; #endif /* CONFIG_CFS_BANDWIDTH */ #endif /* CONFIG_FAIR_GROUP_SCHED */ }; |
X、rt_rq - rt调度类的就绪队列
|
/* Real-Time classes' related field in a runqueue: */ struct rt_rq { //优先级队列,100个优先级的链表,并定义了位图,用于快速查询 struct rt_prio_array active;
//在RT运行队列中所有活动的任务数 unsigned int rt_nr_running; unsigned int rr_nr_running; #if defined CONFIG_SMP || defined CONFIG_RT_GROUP_SCHED struct { //当前RT任务的最高优先级 int curr; /* highest queued rt task prio */ #ifdef CONFIG_SMP //下一个要运行的RT任务的优先级,如果两个任务都有最高优先级,则curr == next int next; /* next highest */ #endif } highest_prio; #endif #ifdef CONFIG_SMP //任务没有绑定在某个CPU上时,这个值会增减,用于任务迁移 unsigned long rt_nr_migratory;
//用于overload检查 unsigned long rt_nr_total;
//RT运行队列过载,则将任务推送到其他CPU int overloaded;
//优先级列表,用于推送过载任务 struct plist_head pushable_tasks; #ifdef HAVE_RT_PUSH_IPI int push_flags; int push_cpu; struct irq_work push_work; raw_spinlock_t push_lock; #endif #endif /* CONFIG_SMP */ //表示RT运行队列已经加入rq队列 int rt_queued;
//下面和限流相关 //用于限流操作 int rt_throttled;
//累加的运行时,超出了本地rt_runtime时,则进行限制 u64 rt_time;
//分配给本地池的运行时 u64 rt_runtime; /* Nests inside the rq lock: */ raw_spinlock_t rt_runtime_lock;
#ifdef CONFIG_RT_GROUP_SCHED //用于优先级翻转问题解决 unsigned long rt_nr_boosted;
//指向运行队列 struct rq *rq;
//指向任务组 struct task_group *tg; #endif }; |
X、dl_rq - dl调度类的就绪队列
|
/* Deadline class' related fields in a runqueue */ struct dl_rq { /* runqueue is an rbtree, ordered by deadline */ struct rb_root rb_root; struct rb_node *rb_leftmost;
unsigned long dl_nr_running;
#ifdef CONFIG_SMP /* * Deadline values of the currently executing and the * earliest ready task on this rq. Caching these facilitates * the decision wether or not a ready but not running task * should migrate somewhere else. */ struct { u64 curr; u64 next; } earliest_dl;
unsigned long dl_nr_migratory; int overloaded;
/* * Tasks on this rq that can be pushed away. They are kept in * an rb-tree, ordered by tasks' deadlines, with caching * of the leftmost (earliest deadline) element. */ struct rb_root pushable_dl_tasks_root; struct rb_node *pushable_dl_tasks_leftmost; #else struct dl_bw dl_bw; #endif }; |
X、task_group - 描述一个任务组
注意:不管有多少个CPU,一个用户组只对应一个task_group结构,但是这个用户组在不同的cpu上都有一个group se结构
|
/* task group related information */ struct task_group { struct cgroup_subsys_state css;
#ifdef CONFIG_FAIR_GROUP_SCHED //下面是这个group对应的se和rq,需要注意的是,下面是一个数组, //也就是说当系统中存在多个cpu的时候,一个组有多个se结构,并且 //在每个cpu上都有一个rq //为什么要这样设计呢?因为如果只有一个se在不同的cpu上移来移去的话, //也就只有一个cpu上能够调度这个group里面的task,也就是说只有一个 //se实现了组调度策略 //se[N]: 表示这个group在第N个cpu上对应的se结构,挂队列时, // 是将se[N]挂入cpuN的运行队列中去 //csf_rq[N]: 表示这个组在第N个cpu上的运行队列,在cpuN上隶属于 // 这个group的所有cfs进程,(这个group中除了cfs进 // 程之外,还有rt进程),都挂在这个csf_rq[N]下对应的 // 红黑树中,也就是这个组中有哪些进程被分配给cpuN /* schedulable entities of this group on each cpu */ struct sched_entity **se; /* runqueue "owned" by this group on each cpu */ struct cfs_rq **cfs_rq;
//这个组的权重,即当前这个group结构,在所有cpu上的group se的权重之和 //详细见下面分析 unsigned long shares;
#ifdef CONFIG_SMP /* * load_avg can be heavily contended at clock tick time, so put * it in its own cacheline separated from the fields above which * will also be accessed at each tick. */ //整个组的负载总和 //因为group在不同的cpu上都有自己的cfs_rq队列,这里的load_avg //表示这个group在所有的cpu上的cfs_rq的负载之和 //load_avg在tick中可能会被严重竞争,因此将它放在一个单独的cacheline中, //与上面的字段分开,该字段也将在每次滴答时被访问 atomic_long_t load_avg ____cacheline_aligned; #endif #endif
#ifdef CONFIG_RT_GROUP_SCHED //下面是这个group对应的se和rq,需要注意的是,下面是一个数组, //也就是说当系统中存在多个cpu的时候,一个组有多个se结构,并且 //在每个cpu上都有一个rq //为什么要这样设计呢?因为如果只有一个se在不同的cpu上移来移去的话, //也就只有一个cpu上能够调度这个group里面的task,也就是说只有一个 //se实现了组调度策略 //se[N]: 表示这个group在第N个cpu上对应的se结构,挂队列时, // 是将se[N]挂入cpuN的运行队列中去 //rt_rq[N]: 表示这个组在第N个cpu上的运行队列,在cpuN上隶属于 // 这个group的所有rt进程,(这个group中除了rt进程 // 之外,还有cfs进程),都挂在这个rt_rq[N]下对应的红 // 黑树中 struct sched_rt_entity **rt_se; struct rt_rq **rt_rq;
struct rt_bandwidth rt_bandwidth; #endif
struct rcu_head rcu;
//系统中的所有task_group,通过该成员被挂在一个task_groups全局链表上 struct list_head list;
//下面成员用于描述task_group之间的组织关系 struct task_group *parent; struct list_head siblings; struct list_head children;
#ifdef CONFIG_SCHED_AUTOGROUP struct autogroup *autogroup; #endif
struct cfs_bandwidth cfs_bandwidth; }; |
x.1 group se和group rq
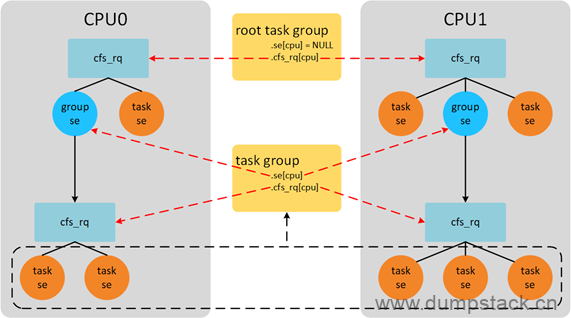
关于task_group中的X_se和X_rq数组的理解,举例如下,例如,从下图中我们可以获取以下信息:
-
系统中一共运行8个进程,CPU0上运行3个进程,CPU1上运行5个进程
-
系统中存在一个用户组,这个用户组共有5个线程,(下图虚线部分),CPU0上分的两个,CPU1上分的3个
-
CPU0上group se获得的CPU时间,会被group se对应的group cfs_rq管理的所有进程瓜分掉
x.3 系统中的所有group的组织关系
另外,系统中的所有task_group,通过该成员被挂在一个task_groups全局链表上
全局变量root_task_group为根组对应的task_group类型的变量,root_task_group.cfs_rq[N]成员表示第N个cpu的最顶层CFS就绪队列cfs_rq
内核中的所有task_group形成树形结构,都挂在以root_task_group为根的"树"下面
|
/* * Default task group. * Every task in system belongs to this group at bootup. */ struct task_group root_task_group; LIST_HEAD(task_groups); |
X、cfs_bandwidth - cfs带宽控制
|
struct cfs_bandwidth { #ifdef CONFIG_CFS_BANDWIDTH raw_spinlock_t lock;
//周期值 ktime_t period;
//quota:限额值 //runtime:记录限额剩余时间,会使用quota值来周期性赋值 u64 quota, runtime;
//层级管理任务组的限额比率 s64 hierarchical_quota;
//每个周期的到期时间 u64 runtime_expires;
//idle:空闲状态,不需要运行时分配; //period_active:周期性计时已经启动; int idle, period_active;
//period_timer:高精度周期性定时器,用于重新填充运行时间消耗; //slack_timer:延迟定时器,在任务出列时,将剩余的运行时间返回到全局池里; struct hrtimer period_timer, slack_timer;
//限流运行队列列表; struct list_head throttled_cfs_rq;
/* statistics */ //下面三个都是统计值 int nr_periods, nr_throttled; u64 throttled_time; #endif }; |
X、rt_bandwidth - rt带宽控制
|
struct rt_bandwidth { /* nests inside the rq lock: */ raw_spinlock_t rt_runtime_lock;
//时间周期 ktime_t rt_period;
//一个时间周期内的运行时间,超过则限流,默认值为0.95ms u64 rt_runtime;
//时间周期定时器 struct hrtimer rt_period_timer; unsigned int rt_period_active; }; |

文章评论