关注公众号不迷路:DumpStack
扫码加关注

一、知识点梳理
首先列出本文要点:
-
虚拟运行时间计算流程:
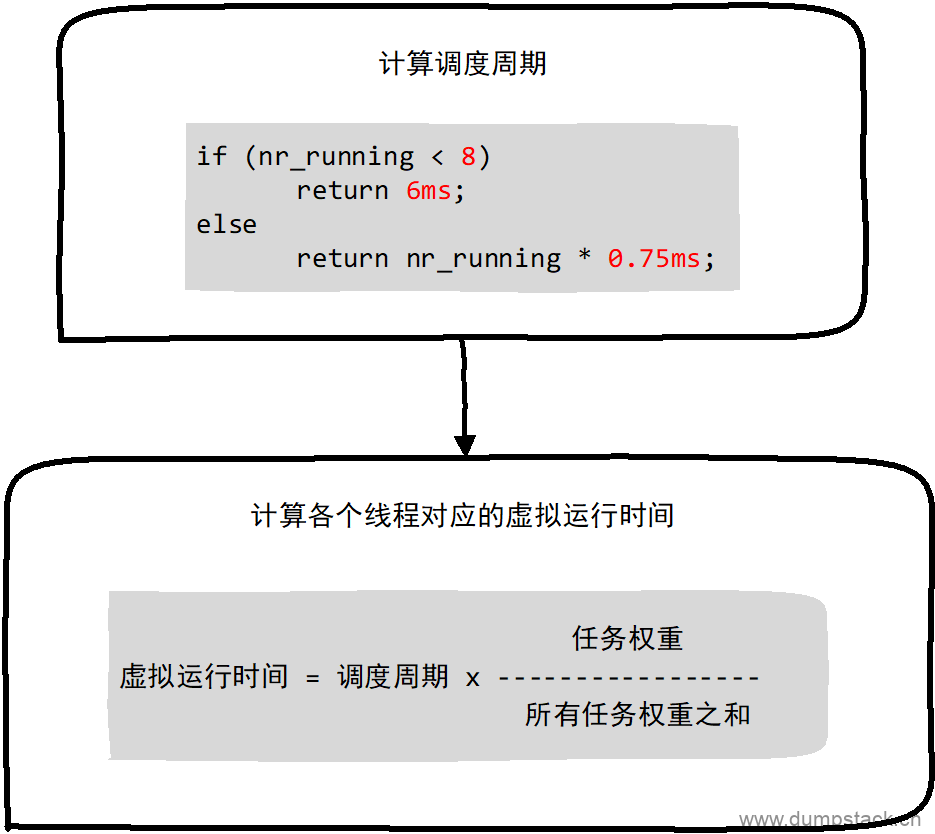
-
进程每降低一个nice值,将多获得10%cpu的时间
-
nice为0时,虚拟运行时间=物理运行时间
-
nice为0时,权重为1024,即下面的NICE_0_LOAD=1024
-
牢记做功的概念:
|
vruntime1 * weight1 = vruntime2 * weight2 |
-
由做功的概念可知虚拟运行时间和物理运行时间的转换关系如下:
|
vriture_runtime * weight = wall_time * NICE_0_LOAD |
下面我们详细分析上面实现细节
二、调度周期/调度延迟
调度周期又叫调度延迟,是物理时间
2.1 概念说明
调度延迟和调度周期是同一个概念,都是指系统中的所有的task都调用一遍后,所需的时间。即同一个进程,在相邻两次运行机会之间的时间差,即等待多长时间运行一次
调度周期是一个动态变化的值,如果每个进程运行的时间一样,例如每个进程都运行10ms,系统中总共有2个进程,那么调度延迟就是20ms,如果有5个进程,那么调度延迟就是50ms。
如果现在保证调度延迟不变,固定是6ms,那么系统中如果有2个进程,那么每个进程运行3ms,如果有6个进程,那么每个进程运行1ms,如果有100个进程,那么每个进程分配到的时间就是0.06ms,随着进程的增加,每个进程分配的时间在减少,但是这样的话,进程调度就会过于频繁,上下文切换时间开销就会变大。因此我们需要保证一个最小粒度,确保当有很多任务时,每个任务至少运行多长时间。
2.2 __sched_period - 已知任务个数,计算调度周期
由上面分析可知,CFS调度器的调度延迟并不是固定的,调度周期计算函数是__sched_period,实现如下:
-
当系统处于就绪态的进程少于一个定值(默认值8)的时候,调度延迟也是固定一个值不变(默认值6ms)
-
当系统就绪态进程个数超过这个值时,我们保证每个进程至少运行一定的时间才让出cpu,这个"最少的一定的时间"被称为最小粒度时间,在CFS默认设置中,最小粒度时间是0.75ms,用全局变量sysctl_sched_min_granularity记录
|
/* * The idea is to set a period in which each task runs once. * * When there are too many tasks (sched_nr_latency) we have to stretch * this period because otherwise the slices get too small. * * p = (nr <= nl) ? l : l*nr/nl */ static u64 __sched_period( unsigned long nr_running) //系统中的进程个数 { //若nr_running大于8时,无法保证调度延迟,因此转为保证调度最小粒度 //若nr_running小于8时,调度周期固定为6ms if (unlikely(nr_running > sched_nr_latency)) return nr_running * sysctl_sched_min_granularity; else return sysctl_sched_latency; } |
其中:
|
/* * Targeted preemption latency for CPU-bound tasks: * (default: 6ms * (1 + ilog(ncpus)), units: nanoseconds) * * NOTE: this latency value is not the same as the concept of * 'timeslice length' - timeslices in CFS are of variable length * and have no persistent notion like in traditional, time-slice * based scheduling concepts. * * (to see the precise effective timeslice length of your workload, * run vmstat and monitor the context-switches (cs) field) */ //当任务个数小于8个时,调度周期固定为6ms unsigned int sysctl_sched_latency = 6000000ULL;
/* * Minimal preemption granularity for CPU-bound tasks: * (default: 0.75 msec * (1 + ilog(ncpus)), units: nanoseconds) */ //调度最小粒度,当任务个数大于8个时,必须保证任务能够运行0.75ms再切换出去 unsigned int sysctl_sched_min_granularity = 750000ULL;
/* * is kept at sysctl_sched_latency / sysctl_sched_min_granularity */ static unsigned int sched_nr_latency = 8; |
三、虚拟运行时间
虚拟运行时间是cfs调度类中的概念,rt、dl等其他调度类是不存在虚拟时间的概念的。
完全公平要求每个task运行的时间是一样的,但是不同的task有不同的优先级,我们总希望优先级高的任务能够获得更多的物理运行时间。上面两个矛盾激发,迫使我们提出虚拟运行时间的概念,既然物理时间维度无法保证,那就保证另一个维度上的公平吧,这就是虚拟运行时间
3.1 为什么要使用虚拟时间
cfs调度器的目标是保证每一个进程的完全公平调度
CFS调度器就像是一个母亲,她有很多个孩子(进程),但是,手上只有一个玩具(cpu)需要公平的分配给孩子玩,假设有2个孩子,那么一个玩具怎么才可以公平让2个孩子玩呢?简单点的思路就是第一个孩子玩10分钟,然后第二个孩子玩10分钟,以此循环下去。CFS调度器也是这样记录每一个进程的执行时间,保证每个进程获取CPU执行时间的公平。因此,哪个进程运行的时间最少,应该让哪个进程运行。
例如,调度周期固定是6ms,系统一共2个相同优先级的进程A和B,那么每个进程都将在6ms周期时间内内各运行3ms。如果他们的权重分别是1024和820(nice值分别是0和1),进程A获得的运行时间是6x1024/(1024+820)=3.3ms,进程B获得的执行时间是6x820/(1024+820)=2.7ms。进程A的cpu使用比例是3.3/6x100%=55%,进程B的cpu使用比例是2.7/6x100%=45%,计算结果也符合上面说的"进程每降低一个nice值,将多获得10%CPU的时间"。
很明显,上面2个进程的实际执行的物理时间是不相等的,但是CFS想保证每个进程运行时间相等,因此CFS引入了虚拟时间的概念,也就是说上面的2.7ms和3.3ms经过一个公式的转换可以得到一样的值,这个转换后的值称作虚拟时间。这样的话,CFS只需要保证每个进程运行的虚拟时间是相等的即可。
3.2 引入权重和nice的概念
CFS调度器和以往的调度器不同之处在于没有时间片的概念,而是分配"使用cpu时间的比例",例如2个相同优先级的进程在一个cpu上运行,那么每个进程都将会分配50%的cpu运行时间,(这里的时间是虚拟时间),这就是要实现的公平。
以上举例是基于同等优先级的情况下,但是现实却并非如此,有些任务优先级就是比较高,那么CFS调度器的优先级是如何实现的呢?
首先,我们引入权重的概念,权重代表着进程的优先级,(权重和优先级两者可以相互转化),各个进程之间按照权重的比例分配cpu时间。例如2个进程A和B,A的权重是1024,B的权重是2048,那么A获得cpu的时间比例是1024/(1024+2048) = 33.3%,B进程获得的cpu时间比例是2048/(1024+2048)=66.7%。我们可以看出,权重越大分配的时间比例越大,相当于优先级越高,在引入权重之后,分配给进程的时间计算公式如下:
|
虚拟运行时间 = 调度周期 x -----------------
|
CFS调度器针对优先级又提出了nice值的概念,其实nice和权重是一一对应的关系,nice值就是一个具体的数字,取值范围是[-20, 19]。数值越小代表优先级越大,同时也意味着权重值越大,nice值和权重之间可以互相转换。内核提供了一个表格转换nice值和权重。下面为nice到权重的转化
|
const int sched_prio_to_weight[40] = { /* -20 */ 88761, 71755, 56483, 46273, 36291, /* -15 */ 29154, 23254, 18705, 14949, 11916, /* -10 */ 9548, 7620, 6100, 4904, 3906, /* -5 */ 3121, 2501, 1991, 1586, 1277, /* 0 */ 1024, 820, 655, 526, 423, /* 5 */ 335, 272, 215, 172, 137, /* 10 */ 110, 87, 70, 56, 45, /* 15 */ 36, 29, 23, 18, 15, }; |
数组的值可以看作是公式:weight = 1024 / 1.25nice计算得到
上面公式中的1.25取值依据是:进程每降低一个nice值,将多获得10%cpu的时间,公式中以1024权重为基准值计算得来,1024权重对应nice值为0,其权重被称为NICE_0_LOAD,默认情况下,大部分进程的权重基本都是NICE_0_LOAD。
3.3 已知nice,通过查表得到权重信息weight和inv_weight
关键字:做功!做功!做功!
类似与物理中的做功的概念,并且nice为0的虚拟时间和物理时间相等,虚拟时间vriture_runtime和物理时间(又叫墙上时间wall_time)转换公式如下
|
由: vriture_runtime * weight = wall_time * NICE_0_LOAD
得: NICE_0_LOAD vriture_runtime = wall_time * ---------------- weight |
上面例子中,进程A的虚拟时间3.3 * 1024 / 1024 = 3.3ms,(我们可以看出nice值为0的进程的虚拟时间和实际时间是相等的),进程B的虚拟时间是2.7 * 1024 / 820 = 3.3ms。我们可以看出尽管A和B进程的权重值不一样,但是计算得到的虚拟时间是一样的,因此CFS主要保证每一个进程获得执行的虚拟时间一致即可。在选择下一个即将运行的进程的时候,只需要找到虚拟时间最小的进程即可
为了避免浮点数运算,因此我们采用先放大再缩小的方法以保证计算精度,内核又对公式做了如下转换
|
NICE_0_LOAD vriture_runtime = wall_time * ---------------- weight
NICE_0_LOAD * 2^32 = (wall_time * -------------------------) >> 32 weight
= (wall_time * NICE_0_LOAD * inv_weight) >> 32
其中: 2^32 (inv_weight = ------------ ) weight |
权重的值weight已经计算保存到sched_prio_to_weight数组中,根据这个数组我们可以很容易计算inv_weight的值,内核中使用sched_prio_to_wmult数组保存inv_weight的值,计算公式是:sched_prio_to_wmult[i] = 2^32/sched_prio_to_weight[i]。
|
const u32 sched_prio_to_wmult[40] = { /* -20 */ 48388, 59856, 76040, 92818, 118348, /* -15 */ 147320, 184698, 229616, 287308, 360437, /* -10 */ 449829, 563644, 704093, 875809, 1099582, /* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326, /* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587, /* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126, /* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717, /* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153, }; |
系统中使用struct load_weight结构体描述进程的权重信息,weight代表进程的权重,inv_weight等于2^32/weight
|
struct load_weight { unsigned long weight; u32 inv_weight; // 2^32/weight }; |
3.4 已知权重和物理时间,计算虚拟时间
3.4.1 __calc_delta - 已知物理时间delta_exec和权重,计算虚拟时间
已知权重为weight的任务获得到的虚拟运行时间为delta_exe,此时如若保证公平,求权重为lw的任务应该获取到的虚拟运行时间vrtime?
由做功的概念得到:
|
delta_exe * weight = vrtime * lw->weight
==> weight vrtime = delta_exe * ---------------- lw->weight
==> vrtime = (delta_exe * weight * lw->inv_weight) >> 32
==> 在分析下面的__calc_delta时,我们继续转化: vrtime = (delta_exe * (weight * lw->inv_weight)) >> 32 vrtime = (delta_exe * fact) >> shift
其中: fact = weight * lw->inv_weight shift = 32
上面只是理论计算方式,但是在实际编码时,还需要考虑一些溢出的情况 注意到:fact每除以2,shift就减1,可以少移动一位 |
注意:下面__calc_delta传入的参数delta_exec为虚拟运行时间,weight为这段虚拟运行时间对于的权重,但是实际上:当weight的值为NICE_0_LOAD时,delta_exec的值实际就是物理时间
|
/* * delta_exec * weight / lw.weight * OR * (delta_exec * (weight * lw->inv_weight)) >> WMULT_SHIFT * * Either weight := NICE_0_LOAD and lw \e sched_prio_to_wmult[], in which case * we're guaranteed shift stays positive because inv_weight is guaranteed to * fit 32 bits, and NICE_0_LOAD gives another 10 bits; therefore shift >= 22. * * Or, weight =< lw.weight (because lw.weight is the runqueue weight), thus * weight/lw.weight <= 1, and therefore our shift will also be positive. */ static u64 __calc_delta( u64 delta_exec, //已知的虚拟时间delta_exec unsigned long weight, //上面虚拟时间对应的权重 struct load_weight *lw) //计算权重lw应该得到的虚拟运行时间 { //1.由上面的分析可知,使用下面两个公式计算虚拟运行时间 // a) vrtime = (delta_exe * (weight * lw->inv_weight)) >> 32 // b) vrtime = (delta_exe * fact) >> shift u64 fact = scale_load_down(weight); int shift = WMULT_SHIFT;
//2.因为下面会使用到inv_weight,在使用之前需要先更新一下 __update_inv_weight(lw);
//3.为了防止下面fact * lw->inv_weight溢出,这里处理一下 // 由上面的分析可知:fact每除以2,shift就减1,可以少移动一位 if (unlikely(fact >> 32)) { while (fact >> 32) { fact >>= 1; shift--; } }
/* hint to use a 32x32->64 mul */ //4.两个32位的乘积,赋值给64位 fact = (u64)(u32)fact * lw->inv_weight;
//5.这里依然是考虑溢出的情况,防止下面delta_exec * fact溢出 while (fact >> 32) { fact >>= 1; shift--; }
//6.执行:(delta_exec * fact) >> shift return mul_u64_u32_shr(delta_exec, fact, shift); } |
3.4.1.1 __update_inv_weight - 计算inv_weight
|
#define WMULT_CONST (~0U) #define WMULT_SHIFT 32
static void __update_inv_weight(struct load_weight *lw) { unsigned long w;
//1.已经有值了,则什么也不干 if (likely(lw->inv_weight)) return;
//2.转化到32位 w = scale_load_down(lw->weight);
if (BITS_PER_LONG > 32 && unlikely(w >= WMULT_CONST)) lw->inv_weight = 1; else if (unlikely(!w)) lw->inv_weight = WMULT_CONST; else lw->inv_weight = WMULT_CONST / w; // inv_weight = 2^32/weight } |
3.4.2 calc_delta_fair - 已知se获得到的物理时间为delta,求对应的虚拟时间
按照上面说的理论,calc_delta_fair函数调用__calc_delta的时候传递的weight参数是NICE_0_LOAD,lw参数是进程对应的struct load_weight结构体
|
/* * delta /= w */ static inline u64 calc_delta_fair( u64 delta, //物理时间 struct sched_entity *se) //为哪个进程计算虚拟运行时间 { //首先有一个判断逻辑,如果这个进程的权重为NICE_0_LOAD, //则其虚拟时间和物理时间时相等的,此时不需要计算,直接返回delta //注意下面__calc_delta传入的参数,因为是物理时间,所以传入的权重为NICE_0_LOAD if (unlikely(se->load.weight != NICE_0_LOAD)) delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta; } |
3.4.3 update_curr - 更新cfs_rq->curr的运行时间信息
这里我们先只关心进程的运行时间,该函数会在后面详细分析
|
/* * Update the current task's runtime statistics. */ static void update_curr(struct cfs_rq *cfs_rq) { //1.对cfs_rq上当前正在运行的进程进行更新 struct sched_entity *curr = cfs_rq->curr;
//2.注意,这是一个物理时间 u64 now = rq_clock_task(rq_of(cfs_rq)); u64 delta_exec;
if (unlikely(!curr)) return;
//2.curr->exec_start中记录着这个进程的sched_entity结构在上一次更新的时间 // 计算距离上一次过去了多长时间,这是一个物理时间, // 这个时间被认为是task运行的物理时间 delta_exec = now - curr->exec_start; if (unlikely((s64)delta_exec <= 0)) return; curr->exec_start = now;
schedstat_set(curr->statistics.exec_max, max(delta_exec, curr->statistics.exec_max));
//3.更新这个进程在整个生命周期中,运行的物理时间总和 curr->sum_exec_runtime += delta_exec; schedstat_add(cfs_rq->exec_clock, delta_exec);
//4.更新这个进行在整个生命周期中,运行的虚拟时间总和 curr->vruntime += calc_delta_fair(delta_exec, curr);
//5.更新cfs_rq的min_vruntime的值 update_min_vruntime(cfs_rq);
if (entity_is_task(curr)) { struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime); cpuacct_charge(curtask, delta_exec);
//6.统计task所在线程组(thread group)的运行时间: // tsk->signal->cputimer.cputime_atomic.sum_exec_runtime account_group_exec_runtime(curtask, delta_exec); }
//7.计算cfs_rq的运行时间,是否超过cfs_bandwidth的限制,暂时不详细分析 account_cfs_rq_runtime(cfs_rq, delta_exec); } |
四、虚拟运行时间的大小比较 - 考虑到虚拟运行时间溢出的情况
vruntime溢出怎么办?虽然调度实体se的vruntime成员是u64类型,可以保存非常大的数,但是当达到2^64ns后依然会溢出?怎么解决溢出问题呢?
下面利用entity_before比较两个调度实体se的vruntime值大小,以确定搜索方向
假设要插入a的vruntime是101,b的vruntime是100,那么entity_before(a, b)函数返回0。现在假设a的vruntime溢出了,vruntime的值是5(我们期望是2^64+5,但是很遗憾溢出结果是5),b的vruntime即将溢出,vruntime的值是2^64-2。那么调度实体a的vruntime无论是5还是2^64+5,entity_before(a, b)函数都会返回0。因此计算结果保持了一致性,所以溢出是没有任何问题的。要看懂这里的代码,需要对负数在计算机中表示形式有所了解。
同样样的C语言技巧还应用在就绪队列min_vruntime成员,试想min_vruntime同样是u64类型也是存在溢出的时候。min_vruntime的溢出是否会有问题呢?其实也不会,我们继续看一下update_min_vruntime函数最后一条代码
|
cfs_rq->min_vruntime = max_vruntime(cfs_rq->min_vruntime, vruntime); |
max_vruntime函数也利用了类似entity_before函数的技巧。所以min_vruntime溢出也不会有问题,max_vruntime依然可以返回正确的结果
4.1 entity_before - 判断两个se的虚拟时间哪个更短
通过判断两个se的虚拟时间哪个更短,a是否在b的前面,以便确定搜索红黑树的方向
|
static inline int entity_before( struct sched_entity *a, struct sched_entity *b) { return (s64)(a->vruntime - b->vruntime) < 0; } |
4.2 min_vruntime - 取小值
|
static inline u64 min_vruntime(u64 min_vruntime, u64 vruntime) { s64 delta = (s64)(vruntime - min_vruntime); if (delta < 0) min_vruntime = vruntime;
return min_vruntime; } |
4.3 max_vruntime - 取大值
|
static inline u64 max_vruntime(u64 max_vruntime, u64 vruntime) { s64 delta = (s64)(vruntime - max_vruntime); if (delta > 0) max_vruntime = vruntime;
return max_vruntime; } |

文章评论