关注公众号不迷路:DumpStack
扫码加关注

目录
- 一、数据结构
- 二、概念梳理
- 三、osq机制
- 四、乐观自旋
- 五、唤醒逻辑
- 六、读操作
- 七、写操作
- 八、其他扩展接口
- 九、要点总结
- 十、参考文档
- 关注公众号不迷路:DumpStack
rwsem特性:
a) 允许多个reader同时进入临界区;
b) 只允许一个writer同时进入临界区;
c) 当临界区是reader时,其他reader可以进入临界区,但是writer必须等着;
d) 当临界区是writer时,其他任何线程,不管是reader还是writer,都必须等着;
本文分析基于Linux5.10.61
一、数据结构
1.1 rw_semaphore
在设计rw_semaphore数据结构时考虑到了cache的一致性,我们自己在编码时也应该考虑下面信息,具体参见下面最前面的一段注释
a) 对于无竞争的rwsem,count和owner是一个task在获取rwsem时需要访问的唯一字段,因此,将它们彼此相邻放置,可以增加它们共享cacheline的机会
b) 在竞争rwsem中,owner可能是此结构中最常访问的字段,因为持有osq锁的乐观等待者将在owner上自旋。对于嵌入的rwsem,上层结构中的其它热字段应远离rwsem,以减少它们共享相同cacheline导致cacheline抖动问题的机会
|
/* * For an uncontended rwsem, count and owner are the only fields a task * needs to touch when acquiring the rwsem. So they are put next to each * other to increase the chance that they will share the same cacheline. * * In a contended rwsem, the owner is likely the most frequently accessed * field in the structure as the optimistic waiter that holds the osq lock * will spin on owner. For an embedded rwsem, other hot fields in the * containing structure should be moved further away from the rwsem to * reduce the chance that they will share the same cacheline causing * cacheline bouncing problem. */ struct rw_semaphore { //count的不用的bit代表不同的含义 atomic_long_t count; /* * Write owner or one of the read owners as well flags regarding * the current state of the rwsem. Can be used as a speculative * check to see if the write owner is running on the cpu. */ //如果是读持锁,只能记录最后一个进入临界区的reader //如果是写持锁,因为临界区只允许一个writer,owner记录的是那个唯一的writer atomic_long_t owner; #ifdef CONFIG_RWSEM_SPIN_ON_OWNER struct optimistic_spin_queue osq; /* spinner MCS lock */ #endif raw_spinlock_t wait_lock;
//阻塞的线程都挂在这个链表上,新加进来的task挂在链表末尾,唤醒从链表最前面开始唤醒 struct list_head wait_list; #ifdef CONFIG_DEBUG_RWSEMS void *magic; #endif #ifdef CONFIG_DEBUG_LOCK_ALLOC struct lockdep_map dep_map; #endif }; |
1.1.1 count成员不同bit的含义
各个字段含义如下:
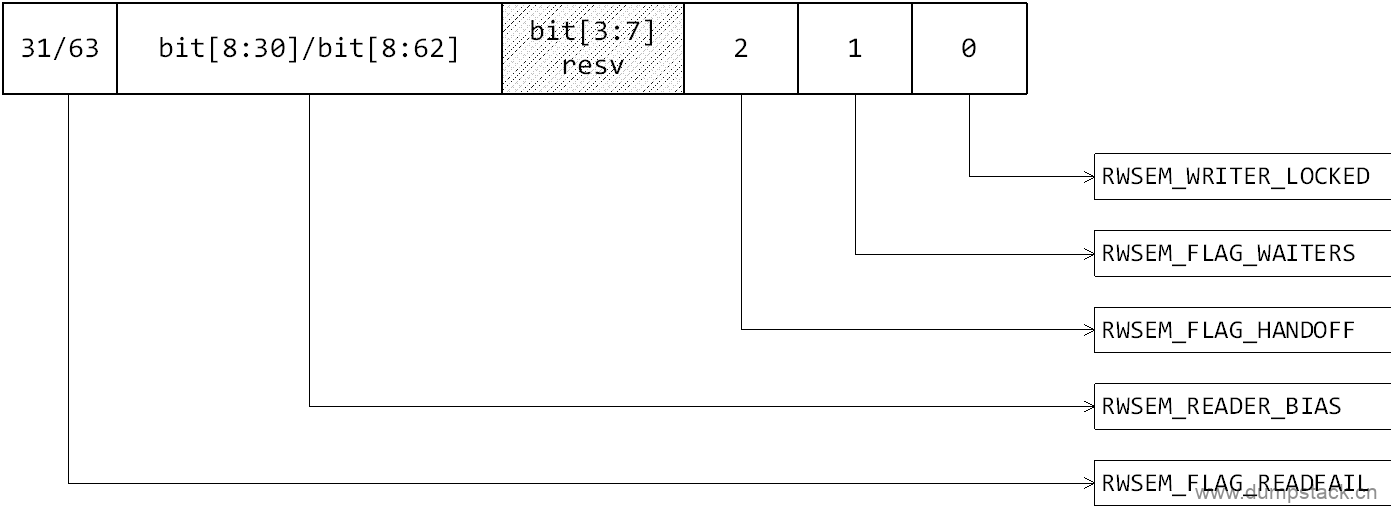
相关宏定义如下:
|
/* * On 64-bit architectures, the bit definitions of the count are: * * Bit 0 - writer locked bit * Bit 1 - waiters present bit * Bit 2 - lock handoff bit * Bits 3-7 - reserved * Bits 8-62 - 55-bit reader count * Bit 63 - read fail bit * * On 32-bit architectures, the bit definitions of the count are: * * Bit 0 - writer locked bit * Bit 1 - waiters present bit * Bit 2 - lock handoff bit * Bits 3-7 - reserved * Bits 8-30 - 23-bit reader count * Bit 31 - read fail bit * * It is not likely that the most significant bit (read fail bit) will ever * be set. This guard bit is still checked anyway in the down_read() fastpath * just in case we need to use up more of the reader bits for other purpose * in the future. * * atomic_long_fetch_add() is used to obtain reader lock, whereas * atomic_long_cmpxchg() will be used to obtain writer lock. * * There are three places where the lock handoff bit may be set or cleared. * 1) rwsem_mark_wake() for readers. * 2) rwsem_try_write_lock() for writers. * 3) Error path of rwsem_down_write_slowpath(). * * For all the above cases, wait_lock will be held. A writer must also * be the first one in the wait_list to be eligible for setting the handoff * bit. So concurrent setting/clearing of handoff bit is not possible. */
//RWSEM_WRITER_LOCKED : 标记当前是reader还是writer在临界区 //RWSEM_FLAG_WAITERS : 标记当前wait_list链表上有阻塞的线程 //RWSEM_FLAG_HANDOFF : 禁止自旋"偷锁",下一次将锁交给wait_list最前面的waiter //RWSEM_FLAG_READFAIL : reader在临界区,并且临界区的reader已经非常多了,计数已经溢出 // 因为其位于最高bit,所以代码中一般通过判断正负,来判断是否有太多 // reader在临界区了 #define RWSEM_WRITER_LOCKED (1UL << 0) //bit0 #define RWSEM_FLAG_WAITERS (1UL << 1) //bit1 #define RWSEM_FLAG_HANDOFF (1UL << 2) //bit2 #define RWSEM_FLAG_READFAIL (1UL << (BITS_PER_LONG - 1)) //最高bit
//RWSEM_READER_BIAS : 实现对count字段加1 //RWSEM_READER_MASK : 不为0时,表示当前有reader在临界区 #define RWSEM_READER_SHIFT 8 #define RWSEM_READER_BIAS (1UL << RWSEM_READER_SHIFT) //可直线count字段加1 #define RWSEM_READER_MASK (~(RWSEM_READER_BIAS - 1)) //bit[8:63]
//RWSEM_WRITER_MASK : 为1时,表示当前writer在临界区 //RWSEM_LOCK_MASK : 该字段不为0,表示当前有人在临界区,不管是reader还是writer #define RWSEM_WRITER_MASK RWSEM_WRITER_LOCKED //bit0 #define RWSEM_LOCK_MASK (RWSEM_WRITER_MASK|RWSEM_READER_MASK) //bit0和bit[8:63]
//除去count和resv字段之外的所有字段,如果该字段不为0,表示后 //来的reader不能通过快速路径拿到锁,必须进行乐观自旋或者睡眠了 // a) 已经有writer进入临界区 // b) 或有人(可能是reader或writer)阻塞在这把锁上 // c) 或当前已近禁止自旋"偷锁" // d) 临界区的reader已经撑爆了 #define RWSEM_READ_FAILED_MASK (RWSEM_WRITER_MASK|RWSEM_FLAG_WAITERS|\ RWSEM_FLAG_HANDOFF|RWSEM_FLAG_READFAIL) |
1.1.2 owner成员不同bit的含义
各个字段含义如下:
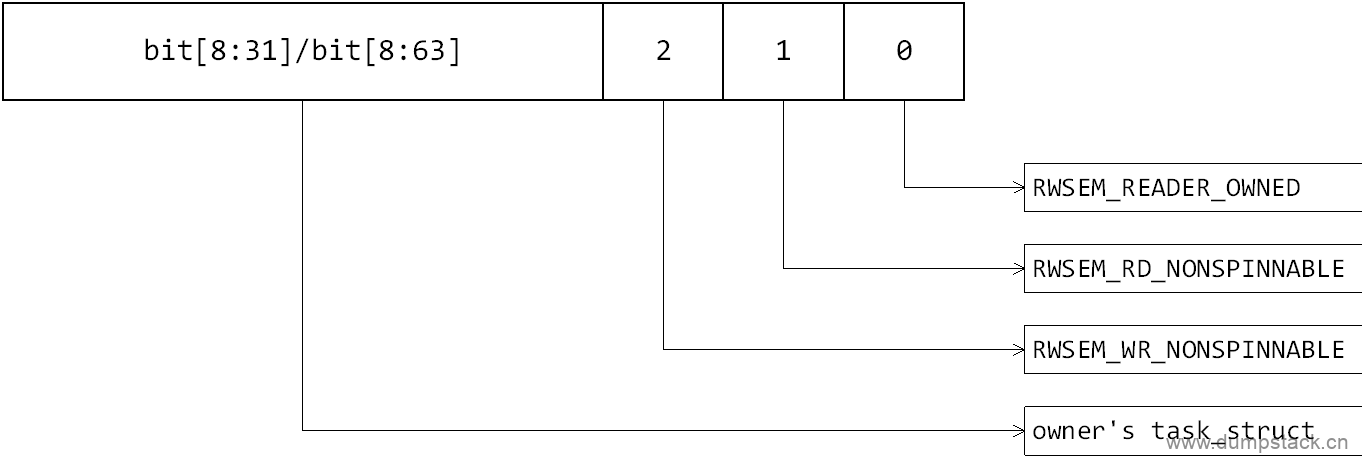
相关宏定义如下:
|
/* * The least significant 3 bits of the owner value has the following * meanings when set. * - Bit 0: RWSEM_READER_OWNED - The rwsem is owned by readers * - Bit 1: RWSEM_RD_NONSPINNABLE - Readers cannot spin on this lock. * - Bit 2: RWSEM_WR_NONSPINNABLE - Writers cannot spin on this lock. * * When the rwsem is either owned by an anonymous writer, or it is * reader-owned, but a spinning writer has timed out, both nonspinnable * bits will be set to disable optimistic spinning by readers and writers. * In the later case, the last unlocking reader should then check the * writer nonspinnable bit and clear it only to give writers preference * to acquire the lock via optimistic spinning, but not readers. Similar * action is also done in the reader slowpath.
* When a writer acquires a rwsem, it puts its task_struct pointer * into the owner field. It is cleared after an unlock. * * When a reader acquires a rwsem, it will also puts its task_struct * pointer into the owner field with the RWSEM_READER_OWNED bit set. * On unlock, the owner field will largely be left untouched. So * for a free or reader-owned rwsem, the owner value may contain * information about the last reader that acquires the rwsem. * * That information may be helpful in debugging cases where the system * seems to hang on a reader owned rwsem especially if only one reader * is involved. Ideally we would like to track all the readers that own * a rwsem, but the overhead is simply too big. * * Reader optimistic spinning is helpful when the reader critical section * is short and there aren't that many readers around. It makes readers * relatively more preferred than writers. When a writer times out spinning * on a reader-owned lock and set the nospinnable bits, there are two main * reasons for that. * * 1) The reader critical section is long, perhaps the task sleeps after * acquiring the read lock. * 2) There are just too many readers contending the lock causing it to * take a while to service all of them. * * In the former case, long reader critical section will impede the progress * of writers which is usually more important for system performance. In * the later case, reader optimistic spinning tends to make the reader * groups that contain readers that acquire the lock together smaller * leading to more of them. That may hurt performance in some cases. In * other words, the setting of nonspinnable bits indicates that reader * optimistic spinning may not be helpful for those workloads that cause * it. * * Therefore, any writers that had observed the setting of the writer * nonspinnable bit for a given rwsem after they fail to acquire the lock * via optimistic spinning will set the reader nonspinnable bit once they * acquire the write lock. Similarly, readers that observe the setting * of reader nonspinnable bit at slowpath entry will set the reader * nonspinnable bits when they acquire the read lock via the wakeup path. * * Once the reader nonspinnable bit is on, it will only be reset when * a writer is able to acquire the rwsem in the fast path or somehow a * reader or writer in the slowpath doesn't observe the nonspinable bit. * * This is to discourage reader optmistic spinning on that particular * rwsem and make writers more preferred. This adaptive disabling of reader * optimistic spinning will alleviate the negative side effect of this * feature. */ //RWSEM_READER_OWNED : 标记这把锁是否被reader持有,1读持锁;0写持锁 //RWSEM_RD_NONSPINNABLE : 是否允许reader执行乐观自旋逻辑,还是直接进阻塞状态 //RWSEM_WR_NONSPINNABLE : 是否允许writer执行乐观自旋逻辑,还是直接进阻塞状态 #define RWSEM_READER_OWNED (1UL << 0) #define RWSEM_RD_NONSPINNABLE (1UL << 1) #define RWSEM_WR_NONSPINNABLE (1UL << 2)
#define RWSEM_NONSPINNABLE (RWSEM_RD_NONSPINNABLE | RWSEM_WR_NONSPINNABLE) #define RWSEM_OWNER_FLAGS_MASK (RWSEM_READER_OWNED | RWSEM_NONSPINNABLE) |
1.2 rwsem_waiter - 描述一个waiter
下面last_rowner成员,在5cfd92e12e13中被提交,但是在617f3ef95177中又被移除了,对应的patch如下:

|
struct rwsem_waiter { //用于将该结构挂在rwsem->wait_list链表上 struct list_head list;
//waiter的task_struct结构 struct task_struct *task;
//标记老子是一个reader还是writer enum rwsem_waiter_type type;
//一个时间戳,waiter如果在链表上阻塞超过4ms,并且当前也已经是 //链表最前面的一个waiter了,就设置HANDOFF标记防止被自旋者"偷锁" unsigned long timeout;
//记录在自旋或睡眠前,也就是申请锁的时候锁的owner //上一次在rwsem_down_read_slowpath中,上一次读时候的锁的owner unsigned long last_rowner; }; |
1.3 rwsem_waiter_type - 标记waiter是reader还是writer
|
enum rwsem_waiter_type { RWSEM_WAITING_FOR_WRITE, //当前线程是一个writer RWSEM_WAITING_FOR_READ //当前线程是一个reader }; |
二、概念梳理
本章参考文档:
https://zhuanlan.zhihu.com/p/390107537
2.1 什么是乐观自旋?
举个例子,不带乐观自旋的锁,若A线程持有锁且正在运行,此时B线程想拿锁,发现锁正被A拿着,B将立即进入睡眠状态,在A线程释放锁后再去唤醒B线程来拿锁。
但是我们通常认为持有锁的A若是在运行的情况下,通常会很快的退出临界区并释放锁,那么B去睡眠则是不必要的,毕竟睡眠和唤醒也是有代价的,完全可以多等一会。那么当开启乐观自旋的机制后,若B拿不到锁,且发现锁的持有者A仍占用着cpu运行时,则不再去睡眠,而是像自旋锁一样进行自旋等待(实际是个for循环,和spin毛关系没有),直到A释放锁,但期间若A失去cpu(即p->on_cpu为0,可能是进runnable状态或者进入睡眠状态),那么B将不会继续傻傻的自旋等待,而是进入睡眠
2.2 什么是"偷锁"?
当锁支持乐观自旋机制时,那么就会存在这样的情况:wait_list中有一些线程在睡眠并等待被唤醒拿锁,同时还有一些线程不在wait_list中且不断的通过乐观自旋等锁,那么wait_list上的线程大概率是抢不过自旋拿锁的进程的,这是因为调度延时的存在,因为当wait_list上的线程被唤醒到真正的真正获得cpu运行,这期间可能已经过去很长时间,锁早就被自旋等锁的线程给"偷走"了。
既然"偷锁"有可能导致wait_list上的进程饥饿,那么为什么还要允许"偷锁"的发生呢?其实允许"偷锁"的行为可以算是对锁的一种性能优化,若是不允许"偷锁"那么下次拿锁的就一定是唤醒的wait_list上的等锁进程,但是从进程被唤醒到该进程真正获得cpu运行,这中间会存在一个时间差,即调度延时。且在这段时间内若还有其他进程一直在trylock尝试偷锁那么将不会偷成功,这些进程都会因此block住。由于调度延时某些场景下会比较久(例如整机高负载时,runqueue上的进程很多),所以还不如先将锁交给正在trylock的进程,也就是允许发生一次"偷锁"。
2.3 HANDOFF机制
因为乐观自旋"偷锁"逻辑的存在,导致正在乐观自旋的申请者很容易就能获得锁,而wait_list链表最前面的线程迟迟得不到锁,所以"偷锁"在一定程度的造成wait_list的等待者长时间"饥饿",如果任由"偷锁"下去,那么wait_list最前面的线程就会被饿死,严重时直接导致系统crash,所以"偷锁"要有个度,这个度就是:当wait_list最前面的线程阻塞时间超过一定的阈值(4ms),就将锁打上RWSEM_FLAG_HANDOFF标记,禁止乐观自旋"偷锁",这样在下一次锁交换时,就一定能够将锁交给wait_list链表最前面的线程
三、osq机制
涉及文件:
U:\linux-5.10.61\kernel\locking\osq_lock.c
U:\linux-5.10.61\include\linux\osq_lock.h
3.1 简介
osq(Optimistic spin queue),即乐观自旋队列,其工作原理示意图如下:
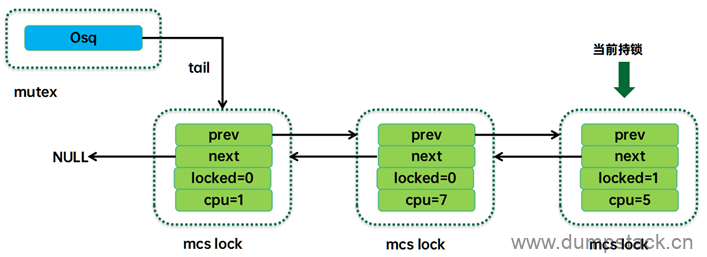
字如其名,Optimistic spin queue就是乐观自旋队列的意思,也就是形成一组处于自旋状态的任务队列。和等待队列wait_list不一样,这个队列中的任务都是当前正在执行的任务。Osq并没有直接将这些任务的task struct形成队列结构,而是把per-CPU的mcs lock对象串联形成队列。Mcs lock中有cpu number,通过这些cpu number可以定位到指定cpu上的current thread,也就定位到了自旋的任务。
虽然都是自旋,但是自旋方式并不一样。Osq队列中的头部节点是持有osq锁的,只有该任务处于对mutex的owner进行乐观自旋的状态(我们称之mutex乐观自旋)。Osq队列中的其他节点都是自旋在自己的mcs lock上(我们称之mcs乐观自旋)。当头部的mcs lock释放掉后(结束mutex乐观自旋,持有了mutex锁),它会将mcs lock传递给下一个节点,从而让spinner队列上的任务一个个的按顺序进入mutex的乐观自旋,从而避免了cache-line bouncing带来的性能开销。
3.2 数据结构
3.2.1 optimistic_spin_queue
|
struct optimistic_spin_queue { /* * Stores an encoded value of the CPU # of the tail node in the queue. * If the queue is empty, then it's set to OSQ_UNLOCKED_VAL. */ atomic_t tail; }; |
3.2.2 optimistic_spin_node
|
/* * An MCS like lock especially tailored for optimistic spinning for sleeping * lock implementations (mutex, rwsem, etc). */ struct optimistic_spin_node { struct optimistic_spin_node *next, *prev; int locked; /* 1 if lock acquired */ int cpu; /* encoded CPU # + 1 value */ }; |
3.3 osq_lock
|
bool osq_lock(struct optimistic_spin_queue *lock) { struct optimistic_spin_node *node = this_cpu_ptr(&osq_node); struct optimistic_spin_node *prev, *next; int curr = encode_cpu(smp_processor_id()); int old;
node->locked = 0; node->next = NULL; node->cpu = curr;
/* * We need both ACQUIRE (pairs with corresponding RELEASE in * unlock() uncontended, or fastpath) and RELEASE (to publish * the node fields we just initialised) semantics when updating * the lock tail. */ old = atomic_xchg(&lock->tail, curr); if (old == OSQ_UNLOCKED_VAL) return true;
prev = decode_cpu(old); node->prev = prev;
/* * osq_lock() unqueue * * node->prev = prev osq_wait_next() * WMB MB * prev->next = node next->prev = prev // unqueue-C * * Here 'node->prev' and 'next->prev' are the same variable and we need * to ensure these stores happen in-order to avoid corrupting the list. */ smp_wmb();
WRITE_ONCE(prev->next, node);
/* * Normally @prev is untouchable after the above store; because at that * moment unlock can proceed and wipe the node element from stack. * * However, since our nodes are static per-cpu storage, we're * guaranteed their existence -- this allows us to apply * cmpxchg in an attempt to undo our queueing. */
/* * Wait to acquire the lock or cancelation. Note that need_resched() * will come with an IPI, which will wake smp_cond_load_relaxed() if it * is implemented with a monitor-wait. vcpu_is_preempted() relies on * polling, be careful. */ if (smp_cond_load_relaxed(&node->locked, VAL || need_resched() || vcpu_is_preempted(node_cpu(node->prev)))) return true;
/* unqueue */ /* * Step - A -- stabilize @prev * * Undo our @prev->next assignment; this will make @prev's * unlock()/unqueue() wait for a next pointer since @lock points to us * (or later). */
for (;;) { /* * cpu_relax() below implies a compiler barrier which would * prevent this comparison being optimized away. */ if (data_race(prev->next) == node && cmpxchg(&prev->next, node, NULL) == node) break;
/* * We can only fail the cmpxchg() racing against an unlock(), * in which case we should observe @node->locked becomming * true. */ if (smp_load_acquire(&node->locked)) return true;
cpu_relax();
/* * Or we race against a concurrent unqueue()'s step-B, in which * case its step-C will write us a new @node->prev pointer. */ prev = READ_ONCE(node->prev); }
/* * Step - B -- stabilize @next * * Similar to unlock(), wait for @node->next or move @lock from @node * back to @prev. */
next = osq_wait_next(lock, node, prev); if (!next) return false;
/* * Step - C -- unlink * * @prev is stable because its still waiting for a new @prev->next * pointer, @next is stable because our @node->next pointer is NULL and * it will wait in Step-A. */
WRITE_ONCE(next->prev, prev); WRITE_ONCE(prev->next, next);
return false; } |
3.3.1 encode_cpu
|
/* * We use the value 0 to represent "no CPU", thus the encoded value * will be the CPU number incremented by 1. */ static inline int encode_cpu(int cpu_nr) { return cpu_nr + 1; } |
3.3.2 node_cpu
|
static inline int node_cpu(struct optimistic_spin_node *node) { return node->cpu - 1; } |
3.3.3 decode_cpu
|
static inline struct optimistic_spin_node *decode_cpu(int encoded_cpu_val) { int cpu_nr = encoded_cpu_val - 1;
return per_cpu_ptr(&osq_node, cpu_nr); } |
3.4 osq_unlock
|
void osq_unlock(struct optimistic_spin_queue *lock) { struct optimistic_spin_node *node, *next; int curr = encode_cpu(smp_processor_id());
/* * Fast path for the uncontended case. */ if (likely(atomic_cmpxchg_release(&lock->tail, curr, OSQ_UNLOCKED_VAL) == curr)) return;
/* * Second most likely case. */ node = this_cpu_ptr(&osq_node); next = xchg(&node->next, NULL); if (next) { WRITE_ONCE(next->locked, 1); return; }
next = osq_wait_next(lock, node, NULL); if (next) WRITE_ONCE(next->locked, 1); } |
四、乐观自旋
注意:这里说的自旋并不是靠自旋锁实现的,而是在一个for循环中不停的轮训实现的
4.1 rwsem_can_spin_on_owner - 判断当前场景是否可以自旋
是否允许自旋是可以通过CONFIG_RWSEM_SPIN_ON_OWNER宏控制的,当开启该宏时,下面场景不允许自旋:
a) 如果申请锁的人在下一个调度时机就会被调度出去,那么就没必要自旋了
b) 如果锁已经被打上nospinable标签(禁止自旋"偷锁"),也没必要自旋,直接挂入链表进阻塞状态
c) 如果是writer在临界区,但是这个writer拿锁不干活,即当前不是正在运行的状态,可能是runnable或者已经进入阻塞状态,但是不管是哪种,都表示这个writer短时间内是完不成了,此时也不用自旋
情景分析:如果当前reader或者writer在申请锁,并且锁未被打上nospinable标签,则有:
a) 如果临界区没人,则自旋
b) 如果reader在临界区,则自旋,因为我们认为reader一般都是很快就会退出临界区
c) 如果是writer在临界区,并且正在running,则自旋
d) 如果是writer在临界区,但是当前writer是处于runnable状态,则不可以自旋
传入的nonspinable参数取决于锁的申请者是reader还是writer:
a) 如果是reader,则从rwsem_down_read_slowpath中传入RWSEM_RD_NONSPINNABLE
b) 如果是writer,则从rwsem_down_write_slowpath中传入RWSEM_WR_NONSPINNABLE
注意:这里判断是否可以自旋时,并不知道调用者是reader还是writer,也就是说所有读或者写都是有可能自旋的
|
#ifdef CONFIG_RWSEM_SPIN_ON_OWNER static inline bool rwsem_can_spin_on_owner( struct rw_semaphore *sem, unsigned long nonspinnable) //锁的申请者是读者自旋还是写者自旋 { struct task_struct *owner; unsigned long flags; bool ret = true;
//1.如果正在申请锁的线程current在下一个调度时机即将调度出去,那么也没有必要自旋了 if (need_resched()) { lockevent_inc(rwsem_opt_fail); return false; }
preempt_disable(); rcu_read_lock();
//2.代码走到这里,表示申请锁的这个线程一时半会是不会调度出去的,此时就需要判断 // 是不是需要自旋等待了,而一个线程是否需要自旋等待取决于当前正在持锁的这个线程 // 下面剥离owner的flags和task_struct字段,分别保存在flags和owner变量中 owner = rwsem_owner_flags(sem, &flags);
/* * Don't check the read-owner as the entry may be stale. */ //3.下面场景也不允许自旋 // a) 锁已经被打上nonspinnable标签(已经禁止自旋"偷锁"),那就不用自旋 // b) 锁虽然没有被打上nonspinnable标签,但是锁已经被writer持有, // 但是writer当前不是处于running状态,可能是runnable或者已 // 经进入阻塞状态,但是不管是那种状态,都表示这个writer短时间 // 不会释放锁(runnable表示至少一个调度时间片都没有完成,也表 // 明短时间不会释放锁)
// 注意:当锁没有被打上nonspinnable标签时,并且满足下面两种情况允许自旋 // a) 如果是reader在临界区的话,后面来的不管是reader还是writer, // 都可以自旋一会,为啥捏??? // 这主要考虑reader很快就能结束,自旋一会可能很快就能拿到锁 // b) 如果是writer在临界区的话,并且这个writer当前正在running // 那么也会返回true,笔者感觉这里有赌的成分,因为内核简单的认 // 为只有在runnable或阻塞状态的writer,才表示这个writer短时 // 间之内不会释放锁,那么既然writer很快能退出,那么我们也等一会把 if ((flags & nonspinnable) || (owner && !(flags & RWSEM_READER_OWNED) && !owner_on_cpu(owner))) ret = false; rcu_read_unlock(); preempt_enable();
lockevent_cond_inc(rwsem_opt_fail, !ret); return ret; } #else static inline bool rwsem_can_spin_on_owner( struct rw_semaphore *sem, unsigned long nonspinnable) { return false; } #endif |
4.1.1 rwsem_owner_flags - 剥离owner的flags和task_struct字段
|
/* * Return the real task structure pointer of the owner and the embedded * flags in the owner. pflags must be non-NULL. */ static inline struct task_struct * rwsem_owner_flags( struct rw_semaphore *sem, unsigned long *pflags) { unsigned long owner = atomic_long_read(&sem->owner);
//1.返回低3bit *pflags = owner & RWSEM_OWNER_FLAGS_MASK;
//2.屏蔽掉低3bit,返回真正的task_struct结构 return (struct task_struct *)(owner & ~RWSEM_OWNER_FLAGS_MASK); } |
4.1.2 owner_on_cpu - 判读持锁者owner当前是不是正在running
如果持锁者处于runnable状态,或者已经进入阻塞状态,或者这个持锁者所在的cpu已经被抢占了,则返回false
|
static inline bool owner_on_cpu(struct task_struct *owner) { /* * As lock holder preemption issue, we both skip spinning if * task is not on cpu or its cpu is preempted */ //第一个条件表示持锁者当前正在running,不是出于runnable和阻塞状态 //第二个条件对arm64来说始终为false,我们暂不深究 return owner->on_cpu && !vcpu_is_preempted(task_cpu(owner)); } |
4.2 rwsem_optimistic_spin - 乐观自旋流程
返回值:拿到锁后返回true
注意:自旋期间,trace上的表现还是running
关于下面对rt线程的优化操作参见下面patch

乐观自旋逻辑如下:
|
#ifdef CONFIG_RWSEM_SPIN_ON_OWNER static bool rwsem_optimistic_spin( struct rw_semaphore *sem, bool wlock) //指示申请锁的人是reader还是writer, { //readr传false,writer传true bool taken = false; int prev_owner_state = OWNER_NULL; int loop = 0; u64 rspin_threshold = 0;
//1.wlock标记申请锁的人是想以读的身份还是写的身份进入临界区, // 申请者要读临界区传false,要写临界区传true,下面转换标记位 unsigned long nonspinnable = wlock ? RWSEM_WR_NONSPINNABLE : RWSEM_RD_NONSPINNABLE;
preempt_disable();
/* sem->wait_lock should not be held when doing optimistic spinning */ //2.标记乐观自旋开始 if (!osq_lock(&sem->osq)) goto done;
/* * Optimistically spin on the owner field and attempt to acquire the * lock whenever the owner changes. Spinning will be stopped when: * 1) the owning writer isn't running; or * 2) readers own the lock and spinning time has exceeded limit. */ //3.乐观自旋外循环,当出现下面情况时,退出自旋 // a) writer持锁,但是writer并没有在运行,而是已经进入阻塞状态 // b) reader持锁,但是申请锁的人是writer,并且这个writer已经自旋超时 //注意:只要没有超时,当reader在临界区时,后来申请锁的人就可以一直等下去 for (;;) { enum owner_state owner_state;
//3.1 内循环,顾名思义,围着这个owner转,直到owner或者flags发生变化 // 才会退出小循环,实际上,当rwsem_spin_on_owner围着owner转时,这 // 个owner一定是writer,其他情况该函数直接返回。函数返回值可为: // a) OWNER_NULL: 没人在临界区 // b) OWNER_WRITER: writer在临界区 // c) OWNER_READER: reader在临界区 // d) OWNER_NONSPINNABLE: 锁已经被打上nospin标记
// OWNER_SPINNABLE定义为(OWNER_NULL | OWNER_WRITER | OWNER_READER) // 也就是说,当临界区没人、写在临界区、读在临界区时,都是有可能自旋的 // 下面的逻辑表示,一旦发现锁已经被打上nospin标记(禁止自旋),就直接 // 退出大循环,并返回false,自旋拿锁失败,后面将会进入睡眠状态 owner_state = rwsem_spin_on_owner(sem, nonspinnable); if (!(owner_state & OWNER_SPINNABLE)) break;
//3.2 代码走到这里,这把锁一定没有被打上nospinable标记,此时的临界区要么 // 没人,要么是reader或者writer,此时需要进一步判断是否需要继续自旋
/* * Try to acquire the lock */ //3.3 执行"偷锁"逻辑 // 从上面小循环中返回,代码走到这里有下面三种情况 // a) OWNER_NULL: 临界区没人,那么可以在这里尝试获取锁 // b) OWNER_READER: reader在临界区,此时如果申请锁的人也是reader的话, // 那么可以直接进入临界区 // c) OWNER_WRITER: writer在临界区,在经过上面rwsem_spin_on_owner中 // 返回,表示有可能owner或者owner的flags发生了变化, // 下面尝试获取锁 //注意: // 如果wait_list链表上有线程阻塞着,则这些阻塞的线程肯定是比这里正在自旋的 // 申请者要先申请锁,但是在这里,后来的申请者却通过自旋的方式却先拿到了锁, // 就像是后来的申请者插队了,这公平吗?这就是传说中的"偷锁"!!!
//注意: // 当一个reader在申请锁的时候,不管临界区时reader还是writer,即使这把锁 // 被打上了RWSEM_FLAG_HANDOFF标记,如果reader在这里"偷锁"失败,reader // 也会继续自旋下去,直到在上面rwsem_spin_on_owner中发现这把锁已经被打上 // nonspinable标记时(临界区reader已经撑爆,或者有一个writer已经自旋超时 // 了),才会结束自旋 taken = wlock ? rwsem_try_write_lock_unqueued(sem) : rwsem_try_read_lock_unqueued(sem); if (taken) break;
/* * Time-based reader-owned rwsem optimistic spinning */ //3.4 下面的逻辑表示当前是writer在自旋申请锁,但是当前是reader在临界区, // 因为我们认为reader一般很快会退出临界区,所以此时writer会再等一会, // 但是需要注意的是,由上面对rwsem_try_read_lock_unqueued的分析可知, // 在writer等待期间,当reader在临界区并且锁没有被打上RWSEM_FLAG_HANDOFF // 标记时,那么后来的reader会通过自旋"偷锁"的方式源源不断的进入临界区, // 也就是说在writer自旋期间,可能会不断的有reader插队,这样writer不就 // 永远拿不到锁了吗?为了确保writer不被饿死,不能一直让reader源源不断的 // 进入临界区吧!解决办法就是禁止reader自旋。 //注意: // 这里将锁的RWSEM_RD_NONSPINNABLE和RWSEM_WR_NONSPINNABLE位全部置位, // 因为此时writer已经长时间自旋都没有拿到锁了,全部置位主要有两个原因: // i) 设置RWSEM_WR_NONSPINNABLE,告诉后来的writer不要做无意义的 // 尝试了,前辈已翻车你就不要自旋了,直接进sleep状态 // ii) 设置RWSEM_RD_NONSPINNABLE,后来的reader也不不会再执行自旋 // 的逻辑,也就不会再出现reader源源不断进入临界区的情况,从源头 // 上防止reader的临界区越来越大 if (wlock && (owner_state == OWNER_READER)) { /* * Re-initialize rspin_threshold every time when * the owner state changes from non-reader to reader. * This allows a writer to steal the lock in between * 2 reader phases and have the threshold reset at * the beginning of the 2nd reader phase. */ //3.5 在reader刚进临界区的时候计算writer自旋的阈值 // (这个writer在上一次循环时,临界区还不是reader(可能没人, // 也可能是writer在临界区),但是这次循环却发现当前临界区已经是 // reader了,说明这些reader是刚被放进来的) if (prev_owner_state != OWNER_READER) { //3.5.1 在重新设置阈值之前,再次检查锁是否被打上了nospinnable // 标记,如果已经被打上了nonspinnable标记,则表示已经禁止 // writer自旋,此时直接结束自旋,(注意:此时nonspinnable // 为RWSEM_WR_NONSPINNABLE)
// reader在临界区时,什么时候会被打上nospin标记呢? // a) 临界区已经有很多reader了,已经溢出了 // b) 有一个writer已经自旋等了很长时间,再等就饿死了 if (rwsem_test_oflags(sem, nonspinnable)) break;
//3.5.2 重新计算自旋的时间 rspin_threshold = rwsem_rspin_threshold(sem); loop = 0; }
/* * Check time threshold once every 16 iterations to * avoid calling sched_clock() too frequently so * as to reduce the average latency between the times * when the lock becomes free and when the spinner * is ready to do a trylock. */ //3.6 代码如果走到这个分支,则表示这个writer在上一次循环时发现临界区时reader, // 这次循环发现临界区还是reader,因为当reader在临界区时,后续申请锁的reader // 是可以直接进入临界区的(只要临界区的reader没有被撑爆,并且锁没有被置为 // RWSEM_FLAG_HANDOFF标记,详见rwsem_try_read_lock_unqueued),也就是说, // 当这个writer在这里自旋时,可能会源源不断的有新的reader进入临界区,如 // 此下去的话,writer会一直自旋下去也拿不到锁,这显然不合理,所以我们在这 // 里设置了一个阈值,当writer自旋一段时间后没有拿到锁,就结束自旋,返回false
//注意到: // writer在自旋超期拿锁失败退出时,将锁的nospin标记置位,这是为啥捏? // 试想,一旦nospin标记被置位,那么后来的申请锁的人(不管是reader还 // 是writer),都不会自旋了,而是直接进入D状态。为啥要这么做捏? // 这还是防止这个writer饿死!试想,只要允许自旋,后来的reader就有可 // 能在自旋期间拿到锁直接进入临界区(只要临界区的reader没有被撑爆,并 // 且锁没有被置为RWSEM_FLAG_HANDOFF标记,详见rwsem_try_read_lock_unqueued), // 要知道wait_list上阻塞的线程是先申请锁的啊,这里通过自旋拿锁不就相 // 当于插队一样吗,这对于wait_list上阻塞的线程显然是不公平的,因为这 // 样wait_list链表上的writer就会越等越久,因为前面不断有人插队,这 // 样writer不就饿死了吗!所以,这里为了防止writer饿死,在进D状态之 // 前,关闭插队机制,即对这把锁打上nospin标记
// 换句话说,只要wait_list上有writer,后来的申请者,不管是reader // 还是writer,都一定不能不能自旋
// 另外一个注意点,下面每循环16次检查一次自旋时间是否已经超过预期限制 // 的值,这主要是为了防止频繁的调用sched_clock else if (!(++loop & 0xf) && (sched_clock() > rspin_threshold)) { rwsem_set_nonspinnable(sem); lockevent_inc(rwsem_opt_nospin); break; } }
/* * An RT task cannot do optimistic spinning if it cannot * be sure the lock holder is running or live-lock may * happen if the current task and the lock holder happen * to run in the same CPU. However, aborting optimistic * spinning while a NULL owner is detected may miss some * opportunity where spinning can continue without causing * problem. * * There are 2 possible cases where an RT task may be able * to continue spinning. * * 1) The lock owner is in the process of releasing the * lock, sem->owner is cleared but the lock has not * been released yet. * 2) The lock was free and owner cleared, but another * task just comes in and acquire the lock before * we try to get it. The new owner may be a spinnable * writer. * * To take advantage of two scenarios listed agove, the RT * task is made to retry one more time to see if it can * acquire the lock or continue spinning on the new owning * writer. Of course, if the time lag is long enough or the * new owner is not a writer or spinnable, the RT task will * quit spinning. * * If the owner is a writer, the need_resched() check is * done inside rwsem_spin_on_owner(). If the owner is not * a writer, need_resched() check needs to be done here. */ //3.7 关于rt线程的优化 // 由上面的注释可知,当rt线程和持锁的线程运行在同一个cpu上时,可能会 // 产生live-lock,(笔者在这里把他翻译为"活锁")。那么什么是"活锁"呢? // 试想,在同一个cpu上,一个普通的cfs线程先拿到锁进入临界区,此时一个 // rt线程来申请锁,那么这个rt线程必然会打断这个cfs线程,只要这个rt // 在自旋,那么这个cfs线程就永远得不到运行,也就永远无法释放锁,这就是 // "活锁" // 所以,这里理论上只要探测到时rt线程就应该立刻返回,实际上原来的代码就 // 是这样的逻辑,修改前代码如下,在990fa7384a305这笔提交做了修改,因为 // 作者Waiman Long通过实验发现,让rt线程在这里多尝试一次是可以提升性能, // 具体参见上面的patch // if (!sem->owner && (need_resched() || rt_task(current))) // break; // 下面我们来分析一下这段代码的具体逻辑,从哪看出是让rt线程"再试一次"的呢
// 实际上,如果申请锁的人是rt的话,代码走到这里时,owner_state一定不是 // OWNER_WRITER,只能是OWNER_NULL或者OWNER_READER。为啥捏,我们先假设 // owner_state是OWNER_WRITER,看看会发生什么情况:此时临界区时writer, // 并且这个rt线程和这个writer是在同一个cpu上,那么这个rt线程一定会抢 // 这个writer的cpu资源,导致这个writer的owner_on_cpu为false,所以在 // 上面的rwsem_spin_on_owner中就会返回OWNER_NONSPINNABLE,所以代码根本 // 不会走到这里!!!所以,对于申请锁的人如果是rt的话,代码走到这里owner_state // 一定是OWNER_NULL或者OWNER_READER
// 代码走到这里,这个rt线程还是没抢到锁,有下面三个可能 // a) owner_state为OWNER_NULL的第一种情况:当前持锁者正在释放锁,sem->owner // 已经被设置为NULL(注意:只有up_writer中才会调用rwsem_clear_owner // 接口将owner设置为NULL,reader退出临界区时并不会设置owner),导致上 // 面rwsem_spin_on_owner中返回的是OWNER_NULL,但锁还没有完全被释放 // (这里说的没有完全释放的意思是,在up_writer释放锁的时候,锁的 // RWSEM_FLAG_HANDOFF标记并没有清除,所以下一个会将锁交给wait_list最 // 前面的那个线程,到时我们在上面"偷锁"的逻辑中也获取不到锁) // b) owner_state为OWNER_NULL的另一种情况:虽然锁已经被完全释放了,sem->owner // 已经被设置为NULL,并且RWSEM_FLAG_HANDOFF标记也已经被清除了,但是因 // 为当前在其他cpu上还可能存在其他线程也在自旋抢这把锁,因为上面"偷锁" // 逻辑本质上也是atomic操作,所以在上面"偷锁"逻辑中,很可能这个rt线程 // 没有抢过其他cpu上的线程(即使其他cpu上的线程时cfs线程) // c) 而如果owner_state为OWNER_READER的话,则表示当前临界区是reader。那 // 么如果这个rt线程是reader,(临界区的reader没有被撑爆,并且锁没有被置 // 为RWSEM_FLAG_HANDOFF标记,后续的reader可以直接进入临界区),此时这个 // rt线程是可以直接进入临界区的,此时代码不会走到这里,因为在上面"偷锁" // 的位置就拿到锁退出了,所以这种情况也是不可能的;如果这个rt是writer, // 则只能自旋。
// prev_owner_state记录的是这个rt线程上一次自旋时临界区的状态, // owner_state记录的是本次自旋时临界区的状态。由上面分析可知,rt // 线程走到这里,"owner_state != OWNER_WRITER"一定成立,但是 // "owner_state != OWNER_WRITER"成立并不表示这个申请锁的线程是rt
// 如果一个rt线程连续两次走到这里,则表示其已经自旋了两次了,如果自旋 // 了两次owner_state状态都没有变化,则停止rt的自旋
if (owner_state != OWNER_WRITER) { //3.7.1 如果当前正在申请锁的线程马上要调度出去了,则返回false,停止自旋 if (need_resched()) break;
//3.7.2 如图rt自旋两次,owner_state都没有发生变化,则停止自旋 if (rt_task(current) && (prev_owner_state != OWNER_WRITER)) break; } prev_owner_state = owner_state;
/* * The cpu_relax() call is a compiler barrier which forces * everything in this loop to be re-loaded. We don't need * memory barriers as we'll eventually observe the right * values at the cost of a few extra spins. */ //3.8 原来这就是他妈的自旋?和spin没有半毛钱关系 cpu_relax(); }
//4.标记自旋结束 osq_unlock(&sem->osq); done: preempt_enable(); lockevent_cond_inc(rwsem_opt_fail, !taken);
//5.乐观自旋拿到锁后返回true,否则返回false return taken; }
#else static inline bool rwsem_optimistic_spin(struct rw_semaphore *sem, bool wlock) { return false; } #endif |
4.2.1 rwsem_try_read_lock_unqueued - reader尝试"偷锁"
reader在乐观自旋期间,通过执行该函数"偷锁"。需要注意的是,因为正在执行自旋逻辑的不仅仅是你一个reader,可能还有其他的reader,也可能有其他的writer,他们同时执行"偷锁"逻辑,那么这把锁会被谁"偷"走就不一定了(谁执行atomic操作能成功要看运气),如果这把锁已经被writer"偷"走(或者这把锁原本就是被writer持有的),或者锁已经被打上了RWSEM_FLAG_HANDOFF标记(禁止"偷锁"),那么这个reader在这里就"偷锁"失败了。
所以:当reader在临界区,只要临界区没有被reader撑爆,并且锁没有被打上RWSEM_FLAG_HANDOFF标记,后来的reader是可以直接进入临界区的
|
/* * Try to acquire read lock before the reader is put on wait queue. * Lock acquisition isn't allowed if the rwsem is locked or a writer handoff * is ongoing. */ static inline bool rwsem_try_read_lock_unqueued(struct rw_semaphore *sem) { long count = atomic_long_read(&sem->count);
//1.下面两种场景reader是"偷"不到锁的 // a) 有一个writer在临界区 // b) 锁已经被打上RWSEM_FLAG_HANDOFF标记,禁止"偷锁" if (count & (RWSEM_WRITER_MASK | RWSEM_FLAG_HANDOFF)) return false;
//2.代码走到这里,临界区可能没人或是reader,并且当前是允许"偷锁"的 // rwsem允许多个reader同时进入临界区,count字段记录的当前有多少个 // reader在临界区,下面对count执行加1标记拿锁。但是在这个原子操作 // 的过程中这把锁还是有可能被其他cpu上的其他线程拿走的,所以这里要判断 // 下面原子操作的返回值是加之前的值,所以这里需要注意,即使原子加完之后, // 这个reader也是有可能拿不到锁的,此时函数返回false count = atomic_long_fetch_add_acquire(RWSEM_READER_BIAS, &sem->count); if (!(count & (RWSEM_WRITER_MASK | RWSEM_FLAG_HANDOFF))) { rwsem_set_reader_owned(sem); lockevent_inc(rwsem_opt_rlock); return true; }
/* Back out the change */ //3.拿锁失败,说明在执行原子操作期间,存在下面两种情况导致拿锁失败, // 此时需要将count重新减回去 // a) 原子操作期间,锁被另一个cpu上的一个writer给抢了 // c) 原子操作期间,锁突然被打上RWSEM_FLAG_HANDOFF标记,禁止偷锁 atomic_long_add(-RWSEM_READER_BIAS, &sem->count); return false; } |
4.2.2 rwsem_try_write_lock_unqueued - writer尝试"偷锁"
执行自旋逻辑的writer在这里尝试"偷锁"进入临界区
|
/* * Try to acquire write lock before the writer has been put on wait queue. */ static inline bool rwsem_try_write_lock_unqueued(struct rw_semaphore *sem) { long count = atomic_long_read(&sem->count);
//1.下面任一条件,writer在这里都会"偷锁"失败 // a) 临界区有人(RWSEM_LOCK_MASK标记被置位),因为对于writer来说, // 只要临界区有人,writer都不能进入临界区 // b) 锁已经被打上RWSEM_FLAG_HANDOFF标记,禁止"偷锁" while (!(count & (RWSEM_LOCK_MASK|RWSEM_FLAG_HANDOFF))) { //2.进入该循环表示当前临界区没人,并且当前还是允许"偷锁"的 // writer拿锁就是通过原子操作将count的RWSEM_WRITER_LOCKED标记置位, // 当然,这个原子操作拿锁的过程,也有可能其他cpu上的线程拿走,下面原子 // 操作返回true表示xchg操作真的成功,也就是说这个writer已经拿到锁了; // 如果原子操作返回false,则表示锁被其他cpu上的其他线程拿走了,此时继 // 续while循环判断,如果真的是锁被别人拿走了,就返回false拿锁失败 // 注意:每次原子操作,count变量都会被修改 if (atomic_long_try_cmpxchg_acquire(&sem->count, &count, count | RWSEM_WRITER_LOCKED)) { rwsem_set_owner(sem); lockevent_inc(rwsem_opt_wlock); return true; } } return false; } |
4.2.3 rwsem_rspin_threshold - 计算当reader在临界区时,writer自旋的阈值
当writer申请锁的时候,如果发现临界区是reader,writer就会自旋等待,但是因为当前是reader在临界区,可能会有其他的reader源源不断的进入临界区(如果临界区的reader没有被撑爆,并且锁没有被置为RWSEM_FLAG_HANDOFF标记,后来的reader可以直接进入临界区的),这将导致reader的临界区不断扩大,但是writer总不能一直自旋下去吧!所以当我们发现writer自旋的时间超过一定的阈值时,就会做下面两件事:
a) writer结束自旋,之后便会进入睡眠状态
b) 顺便将锁的RWSEM_RD_NONSPINNABLE和RWSEM_WR_NONSPINNABLE位全部置位,因为此时writer已经长时间自旋都没有拿到锁了,这么做主要有两个原因:
i) 设置RWSEM_WR_NONSPINNABLE,告诉后来的writer不要做无意义的尝试了,不要自旋了,直接进sleep状态
ii) 设置RWSEM_RD_NONSPINNABLE,后来的reader也不不会再执行自旋的逻辑,也就不会再出现reader源源不断进入临界区的情况,从源头上防止reader的临界区越来越大
而rwsem_rspin_threshold要完成的工作就是计算这个阈值,writer最多允许自旋多长时间。显然,这个阈值的大小和当前临界区reader的个数相关。
|
/* * Calculate reader-owned rwsem spinning threshold for writer * * The more readers own the rwsem, the longer it will take for them to * wind down and free the rwsem. So the empirical formula used to * determine the actual spinning time limit here is: * * Spinning threshold = (10 + nr_readers/2)us * * The limit is capped to a maximum of 25us (30 readers). This is just * a heuristic and is subjected to change in the future. */ static inline u64 rwsem_rspin_threshold(struct rw_semaphore *sem) { long count = atomic_long_read(&sem->count); int readers = count >> RWSEM_READER_SHIFT; u64 delta;
if (readers > 30) readers = 30; delta = (20 + readers) * NSEC_PER_USEC / 2;
return sched_clock() + delta; } |
4.3 rwsem_spin_on_owner - 围着writer转
要点:只要writer一直在运行,小循环就不会退出,一直围着这个writer转,当writer的task或flag发生变化时,退出小循环
后面申请锁的人(可能是reader,也可能是writer),在进入这个小循环之前,会先经过判断,下面几个情况根本就不需要进入小循环:
a) 没人在临界区:这时候后来的申请者不需要自旋就能拿到锁,返回小循环后在大循环里先尝试拿锁,如果拿不到的话则继续自旋
b) reader在临界区:如果申请锁的人是reader,因为多个reader可以直接进入临界区(临界区的reader没有被撑爆,并且锁没有被置为RWSEM_FLAG_HANDOFF标记),退出小循环在大循环里面尝试拿锁,如果拿不到锁的话则继续自旋;如果申请锁的人是writer,此时也返回,在大循环中判断是否自旋超时了。
c) 锁被打上了nonspinable标记:显式打上了该标签,还自旋个毛啊,结束整个自旋流程
当进入了小循环时,此时临界区一定为writer,下面情况会退出小循环
a) 如果owner或flag发生变化(例如task发生了变化,或者同一个task从writer变成了reader)
b) 如果writer进入runnable或者进入阻塞状态(writer短时间之内是不能退出了)
|
static noinline enum owner_state rwsem_spin_on_owner( struct rw_semaphore *sem, unsigned long nonspinnable) //可为RWSEM_WR_NONSPINNABLE或RWSEM_RD_NONSPINNABLE { struct task_struct *new, *owner; unsigned long flags, new_flags; enum owner_state state;
//1.由rwsem_owner_state的实现可知,当返回的state不为OWNER_WRITER时,有下面几种可能 // a) 没人在临界区,这时候后来的申请者不需要自旋就能拿到锁,退出小循环在大循环中尝试拿锁 // b) reader在临界区,因为多个reader可以直接进入临界区,退出小循环在大循环中尝试拿锁 // c) 锁被打上了nonspinable标记,显式打上了该标签,还自旋个毛啊 owner = rwsem_owner_flags(sem, &flags); state = rwsem_owner_state(owner, flags, nonspinnable);
if (state != OWNER_WRITER) return state;
//2.代码都到这里说明这把锁是被writer持有,也就是说spin on owner一定是围着writer转 // 下面这个循环实际是在等锁切换writer,当writer发生切换时退出这里的循环 rcu_read_lock(); for (;;) { /* * When a waiting writer set the handoff flag, it may spin * on the owner as well. Once that writer acquires the lock, * we can spin on it. So we don't need to quit even when the * handoff bit is set. */ //3.由下面的逻辑可知,下面两种情况都会被认为是切换了writer,退出小循环 // a) 持锁的task发生变化 // b) 持锁的task没有变,但是flag发生了变化,例如nonspinable标记发生了变化 // 注意: 这里只是返回,并不是已经拿到到锁了,是否需要继续自旋由新的持锁者决定 new = rwsem_owner_flags(sem, &new_flags); if ((new != owner) || (new_flags != flags)) { state = rwsem_owner_state(new, new_flags, nonspinnable); break; }
/* * Ensure we emit the owner->on_cpu, dereference _after_ * checking sem->owner still matches owner, if that fails, * owner might point to free()d memory, if it still matches, * the rcu_read_lock() ensures the memory stays valid. */ barrier();
//4.代码走到这里说明持锁的writer还没有释放锁,状态也没变, // 但是满足下面条件,也不需要继续自旋了 // a) 锁的申请者即将调度出去,(自己都要挂了,还自旋个毛啊) // b) 或者当前持锁的writer不是正在running,可能是处于runnable // 状态,或者是进入D状态了。真是舔狗的宿命... if (need_resched() || !owner_on_cpu(owner)) { state = OWNER_NONSPINNABLE; break; }
//5.代码走到这里表示writer还没有从临界区出来,并且当前还在运行,那么就再等一下吧 cpu_relax(); } rcu_read_unlock();
return state; } |
4.3.1 owner_state - 描述临界区的状态
临界区的状态由下面4种
OWNER_NULL: 没人在临界区
OWNER_READER : reader在临界区
OWNER_WRITER : writer在临界区
OWNER_NONSPINNABLE : 不允许自旋
|
/* * The rwsem_spin_on_owner() function returns the folowing 4 values * depending on the lock owner state. * OWNER_NULL : owner is currently NULL * OWNER_WRITER: when owner changes and is a writer * OWNER_READER: when owner changes and the new owner may be a reader. * OWNER_NONSPINNABLE: * when optimistic spinning has to stop because either the * owner stops running, is unknown, or its timeslice has * been used up. */ enum owner_state { OWNER_NULL = 1 << 0, //没人在临界区 OWNER_WRITER = 1 << 1, //写在临界区 OWNER_READER = 1 << 2, //读在临界区 OWNER_NONSPINNABLE = 1 << 3, //owner结束自旋 };
//由下面的注释可知,当临界区有reader, writer或者根本就没人在临界区的时候,都有可能使申请者自旋 #define OWNER_SPINNABLE (OWNER_NULL | OWNER_WRITER | OWNER_READER) |
4.3.2 rwsem_owner_state - 获取临界区的状态
临界区的状态是由owner成员的task_struct和flags字段共同决定,判断流程如下:
a) 先将owner成员的task_struct和flags字段剥离
b) 再根据上面剥离的字段判断临界区的状态
|
static noinline enum owner_state rwsem_spin_on_owner( struct rw_semaphore *sem, unsigned long nonspinnable) { struct task_struct *new, *owner; unsigned long flags, new_flags; enum owner_state state;
owner = rwsem_owner_flags(sem, &flags); state = rwsem_owner_state(owner, flags, nonspinnable); if (state != OWNER_WRITER) return state; ... } |
只要owner自旋没有被显式标记为nonspinable(bit1和bit2被置一),都是有可能产生自旋的
|
static inline enum owner_state rwsem_owner_state( struct task_struct *owner, unsigned long flags, //owner成员的低3bit的flags unsigned long nonspinnable) //可为RWSEM_WR_NONSPINNABLE或RWSEM_RD_NONSPINNABLE { //1.判断临界区当前是否允许reader或writer自旋 // 传入的nonspinnable可为RWSEM_WR_NONSPINNABLE或RWSEM_RD_NONSPINNABLE // 该字段由申请锁的人传入,如果申请锁的人是reader,则传入RWSEM_RD_NONSPINNABLE, // 表示这个reader是想判断这个临界区当前是否允许读者自旋;如果申请锁的是人writer, // 则传入RWSEM_WR_NONSPINNABLE,表示这个writer是想判断这个临界区当前是否允许写者自旋 if (flags & nonspinnable) return OWNER_NONSPINNABLE;
//2.下面判断到底是谁在临界区,是reader还是writer,或者根本就没人 // 但是这并不表示申请锁的人就是可以自旋的,而是表示需要进一步判断
//2.1 reader在临界区 if (flags & RWSEM_READER_OWNED) return OWNER_READER;
//2.2 代码走到这里只有两种可能,这两种情况也是可能产生自旋的 // a) 写持锁 // b) 没人持锁 return owner ? OWNER_WRITER : OWNER_NULL; } |
五、唤醒逻辑
5.1 rwsem_first_waiter - 取出wait_list链表最前面的waiter
注意:这个waiter可能是reader,也可能是writer
|
#define rwsem_first_waiter(sem) \ list_first_entry(&sem->wait_list, struct rwsem_waiter, list) |
5.2 rwsem_mark_wake - 从wait_list链表上搜集要唤醒的线程
wait_list链表上的线程都是那些没有申请到锁,进入阻塞状态的线程,既有reader,也有writer,具体要唤醒哪些类型的线程,由wake_type参数决定。函数rwsem_mark_wake的执行逻辑为:根据wake_type,将要唤醒的task先临时添加进wake_q,等待后面一起唤醒
|
/* * handle the lock release when processes blocked on it that can now run * - if we come here from up_xxxx(), then the RWSEM_FLAG_WAITERS bit must * have been set. * - there must be someone on the queue * - the wait_lock must be held by the caller * - tasks are marked for wakeup, the caller must later invoke wake_up_q() * to actually wakeup the blocked task(s) and drop the reference count, * preferably when the wait_lock is released * - woken process blocks are discarded from the list after having task zeroed * - writers are only marked woken if downgrading is false */ static void rwsem_mark_wake( struct rw_semaphore *sem, enum rwsem_wake_type wake_type, //要唤醒什么类型的task struct wake_q_head *wake_q) //将要唤醒的task先添加到一个临时链表上 { struct rwsem_waiter *waiter, *tmp; long oldcount, woken = 0, adjustment = 0; struct list_head wlist;
lockdep_assert_held(&sem->wait_lock);
/* * Take a peek at the queue head waiter such that we can determine * the wakeup(s) to perform. */ //1.获取wait_list最前面的task,队列最前面的task是等待最久的,就唤醒他了 waiter = rwsem_first_waiter(sem);
//2.如果wait_list链表最前面是writer,则不会跳过这个writer去唤醒reader // 下面我们情景分析一下这段代码,满足下面if条件表示链表最前面的是writer: // a) 如果唤醒类型是RWSEM_WAKE_ANY,那么直接将这个writer唤醒 // b) 如果唤醒类型不是RWSEM_WAKE_ANY,那么wake_type只能是RWSEM_WAKE_READERS // 或RWSEM_WAKE_READ_OWNED,也就是说本次一定是想唤醒reader,我们看到下面的 // 代码逻辑就直接return了,并不会真的执行唤醒reader的动作,为啥呢? // 试想,如果真的去唤醒reader的话,那么这个writer就要再多等一会,所以为了防 // 止writer饿死,这个时候不去唤醒任何人
// RWSEM_WAKE_ANY参数应该这么理解:本次要唤醒谁取决于链表最前面线程 // a) 如果链表最前面的是reader,那么本次会唤醒链表上最前面的256个reader一起进入临界区; // b) 如果链表最前面的是writer,那么本次只会唤醒链表最前面的这个writer进入临界区; // 这么设计的原因主要是防止writer饿死,详见__up_read中的描述
// wake_type可取的值还可能是RWSEM_WAKE_READERS或RWSEM_WAKE_READ_OWNED // 这两个type都是表示要唤醒reader,但是背景不一样 // RWSEM_WAKE_READERS : 唤醒链表上的reader // RWSEM_WAKE_READ_OWNED: 用于标记waker已经拿到了reader锁,我是来带领 // wait_list链表上的其他reader一起进入临界区的 if (waiter->type == RWSEM_WAITING_FOR_WRITE) { if (wake_type == RWSEM_WAKE_ANY) { /* * Mark writer at the front of the queue for wakeup. * Until the task is actually later awoken later by * the caller, other writers are able to steal it. * Readers, on the other hand, will block as they * will notice the queued writer. */ wake_q_add(wake_q, waiter->task); lockevent_inc(rwsem_wake_writer); } return; }
//3.代码走到这里,wait_list最前面一定是一个reader,唤醒时一定是从链表最前 // 面开始向后依次唤醒,所以最前面的是reader的话,下一个一定是唤醒reader, // 下面的逻辑是唤醒reader
/* * No reader wakeup if there are too many of them already. */ //4.出现负数表示最高bit位RWSEM_FLAG_READFAIL已经被置一 // 也就是说当前临界区里已经有很多reader了,此时就不要再新的reader了 if (unlikely(atomic_long_read(&sem->count) < 0)) return;
/* * Writers might steal the lock before we grant it to the next reader. * We prefer to do the first reader grant before counting readers * so we can bail out early if a writer stole the lock. */ //5.如果当前wake_type不是RWSEM_WAKE_READ_OWNED,则表示当前的waker // 还没有拿到reader锁,这里唤醒的reader是第一次进入临界区 if (wake_type != RWSEM_WAKE_READ_OWNED) { struct task_struct *owner;
//5.1 如果writer偷了reader的锁,并且最前面的reader阻塞超时, // 则设置HANDOFF标记,禁止偷锁 // 在当前cpu上要唤醒链表上的reader去拿锁,同时在其他cpu上可能存在 // 一个writer也在申请锁(通过自旋的方式),他们通过原子操作公平的竞争, // 谁先抢到谁拿锁,如果下面的if条件成立,则表示在另一个cpu上的那个 // writer已经通过自旋的方式成功拿到锁了,当前cpu上的这个reader拿锁 // 失败,这就是writer"偷"锁的一种场景!!! // 这样链表最前面的reader又要继续处于D状态等下去,但是如果这个reader // 处于D状态的时间已经很长了,再阻塞下去可能就会导致系统crash,这时就会 // 强制设置HANDOFF标记,禁止"偷锁" adjustment = RWSEM_READER_BIAS; oldcount = atomic_long_fetch_add(adjustment, &sem->count); if (unlikely(oldcount & RWSEM_WRITER_MASK)) { /* * When we've been waiting "too" long (for writers * to give up the lock), request a HANDOFF to * force the issue. */ //注意: //这里在设置RWSEM_FLAG_HANDOFF标记时有个小技巧,if条件里 //面的adjustment是减去RWSEM_FLAG_HANDOFF,和后面原子操作 //中的atomic_long_add(-adjustment, &sem->count)结合,就 //是设置RWSEM_FLAG_HANDOFF位了 if (!(oldcount & RWSEM_FLAG_HANDOFF) && time_after(jiffies, waiter->timeout)) { adjustment -= RWSEM_FLAG_HANDOFF; lockevent_inc(rwsem_rlock_handoff); }
atomic_long_add(-adjustment, &sem->count); return; }
/* * Set it to reader-owned to give spinners an early * indication that readers now have the lock. * The reader nonspinnable bit seen at slowpath entry of * the reader is copied over. */ //5.2 代码走到这里,表示这个wait_list链表最前面的reader已经成功拿到了锁 // 下面就需要设置锁的owner,但是在设置owner之前,还有一个工作要做, // 就是继承last_rowner的nonspin标记,为啥捏?????????? owner = waiter->task; if (waiter->last_rowner & RWSEM_RD_NONSPINNABLE) { owner = (void *)((unsigned long)owner | RWSEM_RD_NONSPINNABLE); lockevent_inc(rwsem_opt_norspin); } __rwsem_set_reader_owned(sem, owner); }
/* * Grant up to MAX_READERS_WAKEUP read locks to all the readers in the * queue. We know that the woken will be at least 1 as we accounted * for above. Note we increment the 'active part' of the count by the * number of readers before waking any processes up. * * This is an adaptation of the phase-fair R/W locks where at the * reader phase (first waiter is a reader), all readers are eligible * to acquire the lock at the same time irrespective of their order * in the queue. The writers acquire the lock according to their * order in the queue. * * We have to do wakeup in 2 passes to prevent the possibility that * the reader count may be decremented before it is incremented. It * is because the to-be-woken waiter may not have slept yet. So it * may see waiter->task got cleared, finish its critical section and * do an unlock before the reader count increment. * * 1) Collect the read-waiters in a separate list, count them and * fully increment the reader count in rwsem. * 2) For each waiters in the new list, clear waiter->task and * put them into wake_q to be woken up later. */ //6.代码走到这里,一定是reader在临界区了,因为rwsem是允许多个reader // 同时进入临界区,所以下面需要唤醒wait_list链表上的其他reader,手牵 // 手一起进入临界区,一次最多唤醒256个reader,所以对于reader,rwsem // 是一个相对公平的锁,因为wait_list链表上的reader不管顺序是怎么排序 // 的,他们都可以一起进去临界区,同时获取锁,但是对于writer,是有顺序之 // 分的,wait_list链表前面的writer肯定是比后面的writer先获取到锁
//收集要唤醒的reader的工作必须分两步 // a) 先将这些reader收集在一个单独的链表上,并完成计数,并将计数的值先加 // 到sem->count中去,需要注意的是,这时候这些reader还没有真正的被唤醒 // b) 对上面链表上收集到的每一个reader,清空waiter->task成员,并将这 // 些task加到wake_q中去,以便稍后唤醒
//为啥要分两步呢?上面的注释已经给出答案: // 防止rwsem->count成员的count字段,在增加之前被减少的可能,这是因为 // 可能存在这一的情况:即将被唤醒的waiter可能根本就没有睡眠(参见 // rwsem_down_read_slowpath的实现),所以在慢速路径中这个waiter可能会 // 看到waiter->task成员被清空,于是就结束临界区,并且执行unlock操作, // 而在unlock中会将rwsem->count减1,但是这时候rwsem->count成员的 // count字段还没有执行加操作,先减的话可能会出问题
//6.1 第一步,先收集要唤醒的reader,最多不能超过256个,先将要唤醒的 // reader添加到临时链表wlist上,等到第二步将其放到wake_q上 //注意:这里在遍历链表时,跳过了writer,只唤醒reader INIT_LIST_HEAD(&wlist); list_for_each_entry_safe(waiter, tmp, &sem->wait_list, list) { if (waiter->type == RWSEM_WAITING_FOR_WRITE) continue;
woken++; list_move_tail(&waiter->list, &wlist);
/* * Limit # of readers that can be woken up per wakeup call. */ if (woken >= MAX_READERS_WAKEUP) break; }
//6.1.1 计算count要调整的值 adjustment = woken * RWSEM_READER_BIAS - adjustment; lockevent_cond_inc(rwsem_wake_reader, woken);
//6.1.2 如果此时wait_list为空的话,则取消RWSEM_FLAG_WAITERS标记, // 表示链表上已经没有waiter了 if (list_empty(&sem->wait_list)) { /* hit end of list above */ adjustment -= RWSEM_FLAG_WAITERS; }
/* * When we've woken a reader, we no longer need to force writers * to give up the lock and we can clear HANDOFF. */
//6.1.3 由上面的分析可知,上面设置HANDOFF是为了防止其他writer偷了链表 // 最前面的reader的锁,从而临时禁止偷锁,现在链表最前面的reader已 // 经得到唤醒,需要取消HANDOFF标记,重新允许自旋的线程偷锁 if (woken && (atomic_long_read(&sem->count) & RWSEM_FLAG_HANDOFF)) adjustment -= RWSEM_FLAG_HANDOFF;
if (adjustment) atomic_long_add(adjustment, &sem->count);
/* 2nd pass */ //6.2 第二步:将临时链表wlist上的添加进唤醒队列wake_q中去,以便后面唤醒 list_for_each_entry_safe(waiter, tmp, &wlist, list) { struct task_struct *tsk;
tsk = waiter->task; get_task_struct(tsk);
/* * Ensure calling get_task_struct() before setting the reader * waiter to nil such that rwsem_down_read_slowpath() cannot * race with do_exit() by always holding a reference count * to the task to wakeup. */
//6.2 1 为啥要将waiter->task清空呢? // 这主要和rwsem_down_read_slowpath中的唤醒逻辑有关,在线程被 // 唤醒时,会先判断这个waiter->task成员,如果该成员被清空,则表 // 示其被真正的唤醒了,退出for循环,详见rwsem_down_read_slowpath实现 smp_store_release(&waiter->task, NULL); /* * Ensure issuing the wakeup (either by us or someone else) * after setting the reader waiter to nil. */ //6.2.2 确保在waiter->task设置为NULL后,再执行唤醒动作 // 这里还不是唤醒,只是将其添加到队列中 wake_q_add_safe(wake_q, tsk); } } |
5.1.1 rwsem_wake_type - 要唤醒哪些线程
在调用rwsem_mark_wake唤醒wait_list上的线程时,rwsem_wake_type类型用于指示本次要唤醒哪些waiter
a) RWSEM_WAKE_ANY : 表示唤醒wait_list最前面的线程,他可能是reader,也可能是writer
b) RWSEM_WAKE_READERS : 只唤醒链表上的reader,唤醒的时候会跳过writer
c) RWSEM_WAKE_READ_OWNED : 标记执行唤醒动作的waker,这个waker已经拿到了reader锁
|
enum rwsem_wake_type { RWSEM_WAKE_ANY, /* Wake whatever's at head of wait list */ RWSEM_WAKE_READERS, /* Wake readers only */ RWSEM_WAKE_READ_OWNED /* Waker thread holds the read lock */ }; |
5.3 rwsem_wake - 唤醒wait_list链表上的线程
下面两条路径会调用本函数:
a) __up_write : 那个唯一的writer退出临界区了
b) __up_reader : 临界区的所有reader全部都退出临界区了
但是不管是哪一个路径,都表示:
a) 临界区没人了;
b) wait_list链表上还有人等着;
这时候调用rwsem_mark_wake函数从wait_list上重新唤醒一波线程进入临界区,传入的参数为RWSEM_WAKE_ANY,该参数表示根据wait_list链表最前面的线程是reader还是writer来决定唤醒哪些线程
a) 如果链表最前面的是reader,那么本次会唤醒链表上最前面的256个reader一起进入临界区;
b) 如果链表最前面的是writer,那么本次只会唤醒链表最前面的这个writer进入临界区;
|
/* * handle waking up a waiter on the semaphore * - up_read/up_write has decremented the active part of count if we come here */ static struct rw_semaphore *rwsem_wake(struct rw_semaphore *sem, long count) { unsigned long flags; DEFINE_WAKE_Q(wake_q);
//1.先将要唤醒的线程放到临时链表wake_q上,然后一起唤醒 raw_spin_lock_irqsave(&sem->wait_lock, flags); if (!list_empty(&sem->wait_list)) rwsem_mark_wake(sem, RWSEM_WAKE_ANY, &wake_q); raw_spin_unlock_irqrestore(&sem->wait_lock, flags);
//2.执行唤醒的动作 wake_up_q(&wake_q);
return sem; } |
六、读操作
6.1 down_read - 拿不到锁进D状态
|
void __sched down_read(struct rw_semaphore *sem) { //1.增加抢占点,可能会进入睡眠 // 打开CONFIG_PREEMPT_VOLUNTARY宏表示自愿抢占,是内核的一种抢占模型, // 打开该宏后,might_sleep、might_resched这类接口才会有实现,否则就是 // 空的,在内核中会有多个模块调用这两个函数,例如mutex、信号量、驱动等。 // 这两个函数要完成的工作实际就是判断current的TIF_NEED_RESCHED标记是 // 否被打上,也就是说判断是否要自愿让出cpu,如果被打上的话,就主动调用 // schedule函数调度其他线程运行,通过这样的方式,相当于在代码中会增加了 // 抢占点,这里先简单了解一下,后面在调度章节详细分析 might_sleep();
//2.只有在使能CONFIG_DEBUG_LOCK_ALLOC时才有效 rwsem_acquire_read(&sem->dep_map, 0, 0, _RET_IP_);
//3.这里才是真正的持锁 LOCK_CONTENDED(sem, __down_read_trylock, __down_read); } |
CONFIG_LOCK_STAT宏实现如下,快速路径尝试失败,才会走到慢速路径
|
#ifdef CONFIG_LOCK_STAT #define LOCK_CONTENDED(_lock, try, lock) \ do { \ if (!try(_lock)) { \ lock_contended(&(_lock)->dep_map, _RET_IP_); \ lock(_lock); \ } \ lock_acquired(&(_lock)->dep_map, _RET_IP_); \ } while (0) #else #define LOCK_CONTENDED(_lock, try, lock) \ lock(_lock) #endif |
6.2 __down_read_trylock - 直接拿锁,当reader在临界区,并且wait_list上没有阻塞的线程时,reader可以直接拿到锁
当一个reader在申请rwsem时,如果没人在临界区,或者同时满足下面条件,这个reader能直接拿到锁
a) 当前是reader在临界区
b) 并且wait_list上没有阻塞的线程时
直接拿锁成功返回1,失败返回0
|
static inline int __down_read_trylock(struct rw_semaphore *sem) { long tmp;
//1.调试相关,暂时不关注 DEBUG_RWSEMS_WARN_ON(sem->magic != sem, sem);
/* * Optimize for the case when the rwsem is not locked at all. */ //2.尝试直接拿锁,(所谓拿到锁,就是成功对这个原子变量执行了加1操作) // reader拿到锁时完成下面两个工作 // a) 将sem->count的count字段加1 // b) 将sem->owner设置为current // 需要注意的是,对于reader来说,owner记录的是最后一个进入临界区的reader // 但是并不表示owner指向的task一定就在临界区,详见rwsem_clear_reader_owned
// 首先来看一下atomic_try_cmpxchg_acquire原子操作: // 如果第一个参数和第二个参数相等,则将第三个参数赋值给第一个参数,并返回true, // 否则不执行赋值操作,并返回false,关键字try用于标记是否完成和chg操作 // 注意: // 不管是否交换成功,每次调用atomic_try_cmpxchg_acquire操作后,tmp // 的值都会被修改,tmp会被改为原子变量的旧值,结合这里的do-while表示: // 只要count没有被打上RWSEM_READ_FAILED_MASK标记,这个reader就 // 会一直循环尝试修改这个原子变量的值,直到成功
// RWSEM_READ_FAILED_MASK定义如下: // (RWSEM_WRITER_MASK|RWSEM_FLAG_WAITERS|RWSEM_FLAG_HANDOFF|RWSEM_FLAG_READFAIL), // 这表示满足下面任意一个条件,reader就会退出循环,快速持锁路径都会失败: // a) 如果有writer已经进入临界区 // b) wait_list上有人(可能是reader或writer),即有人阻塞在这把锁上 // c) 锁已经被打上HANDOFF标记 // d) 临界区的reader已经撑爆了
// 换句话说,只有同时满足下面条件,reader才能直接拿到锁 // a) 当前在reader在临界区 // b) 并且wait_list上没有阻塞的线程时 // c) 锁没有被打上HANDOFF标记,即允许偷锁 // (严格意义上来讲,这里不应该叫偷锁,应该叫插队拿锁)
// 还有一个问题,那么这里为什么要不停的循环尝试呢? // 这主要是防止多个cpu同时修改这个count值撞到一块去了,也就是多个cpu // 上在同一时刻恰好都有reader需要进入临界区时,这时候多个cpu会同时来修 // 改这个count的值,一个cpu在写count时,另一个cpu就必须等着
// 返回值:直接拿锁成功返回1,失败返回0 tmp = RWSEM_UNLOCKED_VALUE; do { if (atomic_long_try_cmpxchg_acquire(&sem->count, &tmp, tmp + RWSEM_READER_BIAS)) { rwsem_set_reader_owned(sem);
return 1; } } while (!(tmp & RWSEM_READ_FAILED_MASK)); return 0; } |
6.2.1 rwsem_set_reader_owned - 将current设置为读owner
注意:当reader在临界区时,sem->owner中记录的task并不一定在临界区!!!这是因为当reader在退出临界区时执行的rwsem_clear_reader_owned实际上是空的
|
static inline void rwsem_set_reader_owned(struct rw_semaphore *sem) { //将当前线程current标记为读的owner __rwsem_set_reader_owned(sem, current); } |
6.2.2 __rwsem_set_reader_owned - 将指定的task设置为读owner
|
/* * The task_struct pointer of the last owning reader will be left in * the owner field. * * Note that the owner value just indicates the task has owned the rwsem * previously, it may not be the real owner or one of the real owners * anymore when that field is examined, so take it with a grain of salt. * * The reader non-spinnable bit is preserved. */ static inline void __rwsem_set_reader_owned( struct rw_semaphore *sem, struct task_struct *owner) { //1.在设置read_owner时,除了设置task_struct之外,还完成下面3个工作 // a) 标记RWSEM_READER_OWNED,这个很好理解,因为现在是reader持锁 // b) 保留owner中原来的RWSEM_RD_NONSPINNABLE位的值 // c) 需要特别注意的是,此处还清除了RWSEM_WR_NONSPINNABLE位被清零, // 也就是说,当reader在临界区时,我们认为reader很快就会退出临界 // 区,writer应该再自旋等一下,不用直接进D状态 // 需要注意的是,只要有reader进入临界区,都会清一次RWSEM_RD_NONSPINNABLE // 标记位,也就是说后来的writer都会自旋 unsigned long val = (unsigned long)owner | RWSEM_READER_OWNED | (atomic_long_read(&sem->owner) & RWSEM_RD_NONSPINNABLE);
atomic_long_set(&sem->owner, val); } |
6.3 __down_read
|
static inline void __down_read(struct rw_semaphore *sem) { //背景:代码走到__down_read这里,一定表示前面在调用 // __down_read_trylock时失败了,也就是说此时可能 // a) 临界区里是writer // b) 或者临界区里是reader,但是wait_list上有线程阻塞着
//1.首先是尝试走快速路径持锁,拿到锁后就直接设置owner了 if (!rwsem_read_trylock(sem)) {
//2.上面快速路径拿锁失败,不得不走到这里执行慢速路径 rwsem_down_read_slowpath(sem, TASK_UNINTERRUPTIBLE); DEBUG_RWSEMS_WARN_ON(!is_rwsem_reader_owned(sem), sem); } else { //3.快速路径持锁成功后设置owner // 对于reader,owner记录的是最后一次进入临界区的reader rwsem_set_reader_owned(sem); } } |
6.4 rwsem_read_trylock - 再次尝试直接拿锁,当reader在临界区,并且wait_list上没有阻塞的线程时,reader可以直接拿到锁
感觉这个逻辑和__down_read_trylock是一样的啊,为啥要做成两个函数呢?
返回true持锁成功,返回false持锁失败
|
static inline bool rwsem_read_trylock(struct rw_semaphore *sem) { //1.原子操作返回的值是加完1之后的值,注意这里的逻辑 // 不管这个reader是否能够拿到锁,也不管wait_list链表上是否有线程在等着, // 上来就先将rwsem->count成员的count字段加1,要知道,count字段中记录的 // 是在临界区的reader的个数啊,你这个reader还不一定能成功拿到锁呢,凭啥上 // 来就加1呢?这么自信吗? // 实际上如果这里持锁失败,则会进入慢速路径,在慢速路径中会将这个1减去的 // 那么为啥要提前加呢?难道是起到了提前预警的作用? long cnt = atomic_long_add_return_acquire(RWSEM_READER_BIAS, &sem->count);
//2.这里判断小于0实际是判断count的最高bit位RWSEM_FLAG_READFAIL // RWSEM_FLAG_READFAIL位被置一表示已经有很多reader在临界区了 // 这时候设置nospinable标记,也就是后续不管是reader还是writer // 都不需要再自旋了,直接进阻塞状态,因为服务完这么多reader需要很长时间 if (WARN_ON_ONCE(cnt < 0)) rwsem_set_nonspinnable(sem);
//3.RWSEM_READ_FAILED_MASK的定义如下 // (RWSEM_WRITER_MASK|RWSEM_FLAG_WAITERS|RWSEM_FLAG_HANDOFF|RWSEM_FLAG_READFAIL) // 这表示: // a) 如果临界区的是writer,后来的reader快速持锁失败 // b) 如果wait_list上有等待的线程,则后来的reader也会持锁失败 // c) 如果锁已经被打上HANDOFF标记,则后来的reader持锁失败 // d) 如果临界区的reader已经特别多了,后来的reader也会持锁失败
// 也就是说,只有在当临界区全是reader,并且wait_list上没有阻塞的线程时, // 后来的reader才可以直接拿到锁进入临界区 return !(cnt & RWSEM_READ_FAILED_MASK); } |
6.4.1 rwsem_set_nonspinnable - 设置RWSEM_NONSPINNABLE标记,关闭自旋
RWSEM_NONSPINNABLE是RWSEM_RD_NONSPINNABLE和RWSEM_WR_NONSPINNABLE,设置这两个bit表示reader和writer都不能自旋,直接进阻塞状态,共有两个地方会调用该函数设置nonspinable标记
a) 在rwsem_read_trylock中,发现已经有很多reader在临界区了,此时设置nonspinnable标记,这样后续申请锁的人,不管是reader还是wirter,都不会在自旋了,直接进阻塞状态,因为要等待这些reader都处理完可能要很长时间
b) 在rwsem_optimistic_spin中,reader在临界区,当一个writer已经自旋超时后,会设置nonspinnable标记并退出自旋,这样后续申请锁的人,不管是reader还是wirter,都不会在自旋了,直接进D状态。表示前面已经有一个writer已经很急迫了,关闭了自旋,也就切断了后续的reader源源不断的通过自旋偷锁的方式进入临界区,避免reader的临界区越来越大,这也是防止writer饿死的一种机制。从这一点也可以看出,只有wait_list上有writer阻塞着,后面申请锁的线程,不管是reader还是writer,都不能自旋,直接进阻塞状态
|
/* * Set the RWSEM_NONSPINNABLE bits if the RWSEM_READER_OWNED flag * remains set. Otherwise, the operation will be aborted. */ static inline void rwsem_set_nonspinnable(struct rw_semaphore *sem) { unsigned long owner = atomic_long_read(&sem->owner);
do { //1.下面的条件表示: // a) 如果是reader在临界区时,继续向下,一定会设置RWSEM_NONSPINNABLE, // 此时后来的reader或者writer都不允许自旋 // b) 如果是writer或者没人在临界区时,直接返回,RWSEM_NONSPINNABLE标记 // 保持原来的状态,此时后来的reader或者writer允许自旋,为啥呀? // 该函数的调用时机,都是reader在临界区,根本的目的是禁止reader通过 // 乐观自旋的方式源源不断的进入临界区,导致reader的临界区越来越大,这 // 也是防止writer饿死的一种机制 if (!(owner & RWSEM_READER_OWNED)) break;
if (owner & RWSEM_NONSPINNABLE) break;
//2.代码走到这里,表示reader在临界区,并且还没有设置 // RWSEM_NONSPINNABLE标记,下面就需要设置该标记位
// atomic_long_try_cmpxchg有三个参数,如果第一个参数等于第二个参数, // 则执行xchg操作将第三个参数的值赋值给第一个参数,并返回true;不相 // 等则不执行xchg操作,也就不执行赋值操作,并返回false;并且每次原子 // 操作后,不管是否成功,owner每次都会被更改为最新读取到的sem->owner // 的值,函数返回标记是否已经成功执行了xchg操作;
// 所以,这里的循环的意思是:只有真正的执行了xchg操作时,atomic_long_try_cmpxchg // 才会返回true,表示已经成功将RWSEM_NONSPINNABLE设置上,此时退出循环; // 如果在执行原子变量期间owner成员发生变化(可能值持锁者发生变化,也可能 // 是标记发生变化),atomic_long_try_cmpxchg没有真正的执行xchg操作, // 此时返回false,继续循环操作,直到成功设置RWSEM_NONSPINNABLE标记为止 } while (!atomic_long_try_cmpxchg(&sem->owner, &owner, owner | RWSEM_NONSPINNABLE)); } |
6.5 rwsem_down_read_slowpath - 慢速路径持锁
该函数传入的参数state表示如果reader持锁失败,则将这个reader设置为什么状态,可取值为:
a) TASK_UNINTERRUPTIBLE : 进入D状态
b) TASK_INTERRUPTIBLE : 进入sleep状态
c) TASK_KILLABLE : 直接杀死
|
/* * Wait for the read lock to be granted */ static struct rw_semaphore __sched * rwsem_down_read_slowpath( struct rw_semaphore *sem, int state) //持锁失败时线程进入的状态 { //1.adjustment的初值为-1,表示对count字段减1 // 因为在调用rwsem_down_read_slowpath之前一定已经调用过rwsem_read_trylock // 由前面的分析可知,在rwsem_read_trylock中不管三七二十一直接对count加1了 // 走到这里肯定是没拿到锁,需要减掉了,但是为啥要提前加呢???? long count, adjustment = -RWSEM_READER_BIAS; struct rwsem_waiter waiter;
//2.定义一个等待队列,批量唤醒,这个在后面分析 DEFINE_WAKE_Q(wake_q); bool wake = false;
/* * Save the current read-owner of rwsem, if available, and the * reader nonspinnable bit. */ //3.备份当前rwsem的owner,owner的值可为: // a) 如果是读持锁,只能记录最后一个进入临界区的reader,但是需要注意的是,这个 // owner指向的task当前并不一定在临界区哦,详见rwsem_clear_reader_owned实现 // b) 如果是写持锁,因为临界区只允许一个writer,owner记录的是那个唯一的writer
// 如果当前是writer在临界区,则只保留RWSEM_RD_NONSPINNABLE标记,为啥捏???? // 原因就是方便在后面rwsem_reader_phase_trylock中判断锁的持有者是否被更换了。 // 这里主要是考虑到了这种情况:同一个task,可能一会是reader,而在另一个时刻却 // 摇身一变成了writer,过一会又会在变成reader,这种情况下Linux也会被看做是不 // 同的owner持了锁,但是这种情况下owner的task_struct字段却又是一样的,这样在 // rwsem_reader_phase_trylock中通过(owner ^ last_rowner)的方式判断是否切换过 // owner就会失败,所以这里如果是writer在临界区,会将task_struct字段清空
// 题外话,不得不吐槽一下这里的代码逻辑,真是太乱了,怎么审核过的!!! waiter.last_rowner = atomic_long_read(&sem->owner); if (!(waiter.last_rowner & RWSEM_READER_OWNED)) waiter.last_rowner &= RWSEM_RD_NONSPINNABLE;
//4.判断这个reader是否满足乐观自旋的条件,下面情况不满足乐观自旋的条件, // 详见rwsem_can_spin_on_owner实现 // a) current,也就是当前申请锁的这个reader如果不久就会被调度出去, // 在下一个调度时机就会让出cpu,那么就没必要乐观自旋了 // b) 如果这把锁已经被持锁者打上RWSEM_RD_NONSPINNABLE标签 // 设置nospinable时机详见后面要点总结 // c) 虽然这把锁没有被打上RWSEM_RD_NONSPINNABLE,但是在spin on // writer的过程中,如果这个writer已经不在cpu上了(on_cpu为0, // 也就是不是在running状态,可能是runnable或已经进入阻塞状态), // 则表示这个writer短时间内是不会退出临界区的,那么后来的reader // 也没必要乐观自旋了 if (!rwsem_can_spin_on_owner(sem, RWSEM_RD_NONSPINNABLE)) goto queue;
//5.代码走到这里表示后来的这个reader在当前场景下是满足乐观自旋的条件的
/* * Undo read bias from down_read() and do optimistic spinning. */ //6.还记得我们在rwsem_read_trylock中不管三七二十一,先对count字段执行加1 // 操作吗,现在这个reader需要执行乐观自旋,短时间拿不到锁,进不了临界区,所 // 以先将count减1,因为count字段记录的是在临界区的reader的数量 // 将adjustment清0表示这里已经减去1了,不需要后面再调整了 // 但是为啥要提前加捏??难道是想提前预警吗? atomic_long_add(-RWSEM_READER_BIAS, &sem->count); adjustment = 0;
//7.乐观自旋也不是一直自旋下去,也不一定能拿到锁,下面情况会拿锁失败 // a) 自旋者如果是rt线程,不管是reader还是writer,如果连续尝试过两次自旋失败,就结束自旋 // b) 自旋者如果是writer,当writer自旋超时(临界区是reader),拿锁失败,结束自旋 // c) 自旋者如果是reader,会一直自旋下去,除非自己马上要调度出去,或者当一个writer已 // 经处于自旋状态等临界区的reader超时了,自旋的reader也会退出自旋。(因为此时会设置 // RWSEM_RD_NONSPINNABLE和RWSEM_WR_NONSPINNABLE标记,详见rwsem_optimistic_spin // 实现。换句话说,只要wait_list上有writer,后来的申请者,不管是reader还是writer, // 都一定不能不能自旋) if (rwsem_optimistic_spin(sem, false)) { /* rwsem_optimistic_spin() implies ACQUIRE on success */ /* * Wake up other readers in the wait list if the front * waiter is a reader. */ //8.代码走到这里表示本人reader通过乐观自旋已经拿到锁了,此时临界区已经是 // reader的天下,因为允许reader同时进入临界区,所以这里唤醒wait_list // 链表上阻塞的reader,手牵手一起进入临界区。具体做法是先将这些reader // 添加进临时的等待队列wake_q,然后一起唤醒
// 这里有个问题,在判断wait_list链表上是否有阻塞的线程时,为啥已经通过count // 的RWSEM_FLAG_WAITERS字段判断了,还要再通过list_empty判断一次呢???? if ((atomic_long_read(&sem->count) & RWSEM_FLAG_WAITERS)) {
//8.1 将wait_list链表上的reader先添加进wake_q raw_spin_lock_irq(&sem->wait_lock); if (!list_empty(&sem->wait_list)) rwsem_mark_wake(sem, RWSEM_WAKE_READ_OWNED, &wake_q); raw_spin_unlock_irq(&sem->wait_lock);
//8.2 再讲wake_q链表上的所有reader全部唤醒 wake_up_q(&wake_q); }
//8.3 返回非空表示成功拿到锁 return sem; }
//9.代码走到这里表示reader通过乐观自旋没有拿到锁,下面还有一次机会 // 在真正的挂入链表之前,再尝试一次吧 // waiter.last_rowner中记录的那个在乐观自旋前,锁的持有者, // 我们想通过这个知道到底临界区的持锁者是否换过一波 else if (rwsem_reader_phase_trylock(sem, waiter.last_rowner)) { /* rwsem_reader_phase_trylock() implies ACQUIRE on success */ return sem; }
//10.代码走到这里表示乐观自旋拿锁失败,下面也需要将本reader挂到链表上了
queue: //11.代码走到这里表示不得不把本reader挂到wait_list上了 // 下面初始化rwsem_waiter结构,阻塞超时时间是4ms,需要注意的是, // 这里并不是说阻塞超过4ms就退出,而是阻塞超过4ms设置HANDOFF标 // 记,防止饿死,禁止哪些后来的申请锁的人在自旋过程中拿到锁 waiter.task = current; waiter.type = RWSEM_WAITING_FOR_READ; waiter.timeout = jiffies + RWSEM_WAIT_TIMEOUT;
raw_spin_lock_irq(&sem->wait_lock);
//12.如果链表为空,则说明之前没有其他的线程阻塞在这把锁上 // 第一次有线程被加到wait_list上,需要设置RWSEM_FLAG_WAITERS标记 if (list_empty(&sem->wait_list)) { /* * In case the wait queue is empty and the lock isn't owned * by a writer or has the handoff bit set, this reader can * exit the slowpath and return immediately as its * RWSEM_READER_BIAS has already been set in the count. */ //13.尝试"偷锁",这里实际上是偷了正在自旋的writer的锁 // a) 如果adjustment为0,则表示本reader在此之前就已经执行过自旋逻辑了, // 给你机会你不中用啊,还是老实去wait_list上呆着吧 // b) 如果adjustment不为0,则表示这个reader之前不满足自旋的条件,前面并 // 没有乐观自旋过,如果同时满足下面两个条件,则在这里偷锁 // i) 当前是临界区没人或者是reader // ii) 并且锁没有被加上HANDOFF标记,也就是说还是允许"偷锁"的 if (adjustment && !(atomic_long_read(&sem->count) & (RWSEM_WRITER_MASK | RWSEM_FLAG_HANDOFF))) { /* Provide lock ACQUIRE */ smp_acquire__after_ctrl_dep(); raw_spin_unlock_irq(&sem->wait_lock); rwsem_set_reader_owned(sem); lockevent_inc(rwsem_rlock_fast); return sem; }
//14.加上RWSEM_FLAG_WAITERS标记 adjustment += RWSEM_FLAG_WAITERS; }
//15.将reader添加进wait_list链表,添加到末尾 list_add_tail(&waiter.list, &sem->wait_list);
/* we're now waiting on the lock, but no longer actively locking */ //16.调整rwsem->count成员 if (adjustment) count = atomic_long_add_return(adjustment, &sem->count); else count = atomic_long_read(&sem->count);
/* * If there are no active locks, wake the front queued process(es). * * If there are no writers and we are first in the queue, * wake our own waiter to join the existing active readers ! */ //17.满足下面条件表示当前临界区已经没人了 // 为啥临界区没人了,这个reader却无法进入临界区呢???
// 当同时满足下面两个条件时,即使临界区是空的,后来的reader也不能进入临界区 // a) 如果wait_list上已经有writer阻塞着,则后来的这个reader则在慢速路径中首先不会自旋 // b) 如果链表最前面的writer已经阻塞超时了,并且已经设置了RWSEM_FLAG_HANDOFF标记,则在 // 上面也是有可能拿到锁的
// 下面的操作: // a) 清除RWSEM_WR_NONSPINNABLE标记,后来的writer在申请锁的时候又可以乐观自旋了 // 为什么呢要这么做呢?为什么不把RWSEM_RD_NONSPINNABLE标记也清掉了? // 详细参见后面clear_wr_nonspinnable的分析 // b) 并将wake标记为true,因为临界区没人了,可以从wait_list链表上重新唤醒一波进入临界区了 if (!(count & RWSEM_LOCK_MASK)) { clear_wr_nonspinnable(sem); wake = true; }
//18.满足下面任意一个条件,去wait_list上唤醒一波 // a) 如果当前临界区里已经没人了; // b) 或者是reader在临界区,并且本reader在上面也刚刚被加入队列,这是为啥捏??? //注意: // 这里的rwsem_mark_wake传入的参数为RWSEM_WAKE_ANY,表示会根据 // 链表最前面的线程,决定唤醒reader还是writer if (wake || (!(count & RWSEM_WRITER_MASK) && (adjustment & RWSEM_FLAG_WAITERS))) rwsem_mark_wake(sem, RWSEM_WAKE_ANY, &wake_q);
raw_spin_unlock_irq(&sem->wait_lock); wake_up_q(&wake_q);
/* wait to be given the lock */ //19.下面将要进入阻塞状态了 for (;;) { //19.1 设置当前线程的状态 set_current_state(state);
//19.2 注意:这个waiter可能都还没有真正的睡眠就被唤醒了,也就是刚 // 被加到队列中,就在上面的rwsem_mark_wake中被唤醒了。也正是 // 因为在这里是判断waiter.task是否为空,所以在rwsem_mark_wake // 时需要分两步唤醒 if (!smp_load_acquire(&waiter.task)) { /* Matches rwsem_mark_wake()'s smp_store_release(). */ break; }
//19.3 检查是否有挂起的信号等待处理,如果有挂起的信号等待处理, // 则进入该分支处理信号,可以被kill之类的操作唤醒 if (signal_pending_state(state, current)) { raw_spin_lock_irq(&sem->wait_lock);
//19.4 被信号唤醒后先判断一下,是否拿到锁了 if (waiter.task) goto out_nolock; raw_spin_unlock_irq(&sem->wait_lock); /* Ordered by sem->wait_lock against rwsem_mark_wake(). */ break; }
//19.5 调度其他线程执行 schedule(); lockevent_inc(rwsem_sleep_reader); }
//20.代码走到这里表示已经成功拿到锁了,重新设置为running状态 __set_current_state(TASK_RUNNING); lockevent_inc(rwsem_rlock); return sem;
out_nolock: //21.代码走到这里表示拿锁失败,从D状态中唤醒时因为被kill等操作唤醒的 // 下面将其从链表上摘下来,如果wait_list链表空了的话,则清除 // RWSEM_FLAG_WAITERS和RWSEM_FLAG_HANDOFF标记 list_del(&waiter.list); if (list_empty(&sem->wait_list)) { atomic_long_andnot(RWSEM_FLAG_WAITERS|RWSEM_FLAG_HANDOFF, &sem->count); }
//22.重新设置running状态,并返回拿锁失败 raw_spin_unlock_irq(&sem->wait_lock); __set_current_state(TASK_RUNNING); lockevent_inc(rwsem_rlock_fail); return ERR_PTR(-EINTR); } |
6.5.1 rwsem_reader_phase_trylock - 在挂入wait_list之前,再挣扎一下
由下面的注释可知,只有在一个reader经过乐观自旋还是没有获取到锁时,才会调用到这个函数,这个函数的作用就是,在乐观自旋失败,本reader即将被挂入链表进入阻塞状态之前,再挣扎一把,看看能不能获取到锁。
怎么个挣扎法呢?
本reader在执行乐观自旋之前锁的持有者被记录在last_rowner中,乐观自旋结束后锁的新持有者被记录在sem->owner中,为了方便描述,我们把这个新的owner记为new_owner,则存在下面情况:
a) 新的持有者new_owner是一个writer,那么reader是注定在短时间内拿不到锁了,这时候返回false
b) 如果新的持有者new_owner也是一个reader,那么还存在下面两个情况:
i) new_owner和last_rowner一样,也就是说在本reader乐观自旋期间,临界区的reader们压根就没变过,之前是哪些人现在还是哪些人,没有任何一个新的owner进入过临界区,那还等个毛啊,注定在临界区的reader们短时间之内是不会退出了。举个例子,你去办事大厅取号办事,前面排了很多人,要等,此时你突然肚子疼想拉屎,拉屎前你发现现在窗口正在办理业务的是张三,你一泡屎拉了10分钟,回来后发现窗口前还是在办张三的业务,这说明张三的业务很负载,短时间之内是办理不完了,此时返回false,不挣扎了,去wait_list上迷瞪一会吧;
ii) 但是如果new_owner和last_owner不一样,那至少说明还是有新的reader可以进入临界区的。也就是说你在拉屎前发现正在办理张三的业务,拉完屎后办理的是李四的业务,至少办事流程是走的,还是有希望的,这时候可以尝试一下
|
/* * This function is called when the reader fails to acquire the lock via * optimistic spinning. In this case we will still attempt to do a trylock * when comparing the rwsem state right now with the state when entering * the slowpath indicates that the reader is still in a valid reader phase. * This happens when the following conditions are true: * * 1) The lock is currently reader owned, and * 2) The lock is previously not reader-owned or the last read owner changes. * * In the former case, we have transitioned from a writer phase to a * reader-phase while spinning. In the latter case, it means the reader * phase hasn't ended when we entered the optimistic spinning loop. In * both cases, the reader is eligible to acquire the lock. This is the * secondary path where a read lock is acquired optimistically. * * The reader non-spinnable bit wasn't set at time of entry or it will * not be here at all. */ static inline bool rwsem_reader_phase_trylock( struct rw_semaphore *sem, unsigned long last_rowner) //记录乐观自旋之前的reader { unsigned long owner = atomic_long_read(&sem->owner);
//1.经历一段时间的乐观自旋后,新的持有者是一个writer, // 那么reader是注定在短时间内拿不到锁了,这时候返回false if (!(owner & RWSEM_READER_OWNED)) return false;
//2.代码走到这表示当前还是reader们在临界区,此时的rwsem->owner记录的是最 // 后一个进入临界区的reader,(owner ^ last_rowner)表示如果乐观自旋前后的 // owner不一样,则说明临界区里还是有新的reader进去了,为什么下一个不能是 // 我呢,此时可以再次尝试一下获取锁,说不定就拿到了
// 注意: // 在执行rwsem_try_read_lock_unqueued时,申请锁的是reader,锁的owner也是reader if (((owner ^ last_rowner) & ~RWSEM_OWNER_FLAGS_MASK) && rwsem_try_read_lock_unqueued(sem)) { lockevent_inc(rwsem_opt_rlock2); lockevent_add(rwsem_opt_fail, -1); return true; }
//3.代码走到这里,虽然此时临界区里面还是reader的天下,但是可能存在下面两种情况 // a) 临界区的reader们就没换过,也就是说这里的所有reader操作都是很耗时的 // b) 虽然不断有新的reader进入临界区,但是轮也轮不到我啊!崩溃 return false; } |
6.6 up_read - reader退出临界区时释放锁
|
void up_read(struct rw_semaphore *sem) { rwsem_release(&sem->dep_map, _RET_IP_); __up_read(sem); } |
6.7 __up_read - reader退出临界区时释放锁
注意:reader退出临界区时,是一个一个退出的,此时的owner并不一定是指向自己,并且当临界区还是reader的天下时,owner的task_struct字段并不一定在临界区
|
/* * unlock after reading */ static inline void __up_read(struct rw_semaphore *sem) { long tmp;
//1.调试信息 DEBUG_RWSEMS_WARN_ON(sem->magic != sem, sem); DEBUG_RWSEMS_WARN_ON(!is_rwsem_reader_owned(sem), sem);
//2.清除owner,正式项目没有开启CONFIG_DEBUG_RWSEMS宏,啥也不干 // 也就是说即使owner所指向的task_struct已经退出临界区,但是这个 // owner的task_struct可能依然指向他(假设没有新的reader进入临界区) rwsem_clear_reader_owned(sem);
//3.有一个reader已经退出临界区了,count减1 tmp = atomic_long_add_return_release(-RWSEM_READER_BIAS, &sem->count); DEBUG_RWSEMS_WARN_ON(tmp < 0, sem);
//4.所有reader退出临界区时,唤醒wait_list链表上阻塞的线程进入临界区 // 满足下面条件表示临界区已经没人了,但是wait_list上还有阻塞着的线程, // 此时从wait_list链表上唤醒新的任务进入临界区
// 在唤醒wait_list链表上其他线程时,为啥要等所有reader都退出时才唤醒呢? // 因为多个reader是可以同时进入临界区的,并且一般reader在临界区的时间都 // 很短,在临界区的reader的数量又很多。如过不加上上面两个条件,那么只要有 // reader退出,就执行rwsem_wake操作,那么将会带来下面两个问题: // a) 频繁的遍历wait_list挑选要唤醒的线程,带来额外的开销 // b) 因为当前reader在临界区,所以rwsem_wake只会唤醒reader, // 那么就会导致这样的现象:只要wait_list上有reader,就会被 // 唤醒进入临界区,这样wait_list上的reader源源不断的进入临 // 界区,reader的临界区不断变大,writer却迟迟不能等到锁,直 // 到wait_list上没有任何reader后,writer才允许进入临界区, // 这样writer不就饿死了吗
// 加上上面两个条件限制,完美的解决了这个问题,并不是每次有reader退出临界区, // 都会从wait_list链表上重新唤醒新的线程进入临界区,而是当临界区的reader全 // 部退出临界区后才重新从wait_list上唤醒新的线程进入临界区,而这些新唤醒的线 // 程可能是reader,也可能是writer,如果是writer,一次只能放一个进来,如果是 // reader,一次最多放256个进来
// 这里为啥只清除RWSEM_WR_NONSPINNABLE呢,而RWSEM_RD_NONSPINNABLE保持原样呢? // 此时临界区为空了,此时一切从头再来,所以这里理论上应该将RWSEM_WR_NONSPINNABLE // 和RWSEM_RD_NONSPINNABLE全部都清除才合理,即后面来的不管是reader还是writer // 都又可以通过自旋拿锁了,但是这里偏偏只清除RWSEM_WR_NONSPINNABLE呢,而 // RWSEM_RD_NONSPINNABLE保持原样,这是为啥呢? // 试想,当前时刻是所有的reader都退出临界区,因为rwsem是允许多个reader同时进 // 入临界区的,当reader在临界区时,后来的reader是可以直接进临界区的(详见 // __down_read_trylock实现),所以当所有reader全部退出临界区时,reader可能已经 // 霸占这把锁相当一段时间了,如果我们在这里将RWSEM_RD_NONSPINNABLE也清除,那么很 // 可能后来的reader又会通过自旋的方式进入临界区,又会出现长时间霸占锁的情况,这对 // writer不公平!所以我们在这里只将RWSEM_WR_NONSPINNABLE标记清零,也就是说值允 // 许writer自旋拿锁,而后面的reader会直接被挂进wait_list上 if (unlikely((tmp & (RWSEM_LOCK_MASK|RWSEM_FLAG_WAITERS)) == RWSEM_FLAG_WAITERS)) { clear_wr_nonspinnable(sem); rwsem_wake(sem, tmp); } } |
6.7.1 rwsem_clear_reader_owned - reader退出临界区时清除owner
注意:只有在使能CONFIG_DEBUG_RWSEMS才会清除owner成员中的task_struct字段
|
#ifdef CONFIG_DEBUG_RWSEMS /* * With CONFIG_DEBUG_RWSEMS configured, it will make sure that if there * is a task pointer in owner of a reader-owned rwsem, it will be the * real owner or one of the real owners. The only exception is when the * unlock is done by up_read_non_owner(). */ static inline void rwsem_clear_reader_owned(struct rw_semaphore *sem) { unsigned long val = atomic_long_read(&sem->owner);
//因为rwsem允许多个reader在临界区,此时rwsem->owner中记录的是最后一个进入 //临界区的线程。所以当一个reader退出临界区时,rwsem->owner并不一定是指向这个 //reader的,需要判断,如果不一致的话则不做任何操作;一致则会清除owner成员中的 //task_struct字段,保留flags字段,这时候task_struct字段是空的
//注意: // 使能CONFIG_DEBUG_RWSEMS时,如果没有新的reader进入临界区,只是不断的有 // reader退出临界区,那么此时owner的task_struct字段会一直是空的,所以, // 如果当使能CONFIG_DEBUG_RWSEMS宏时,发现owner字段为空的话,并不表示当前 // 临界区没人哦 while ((val & ~RWSEM_OWNER_FLAGS_MASK) == (unsigned long)current) { if (atomic_long_try_cmpxchg(&sem->owner, &val, val & RWSEM_OWNER_FLAGS_MASK)) return; } } #else //注意: // 没有开启CONFIG_DEBUG_RWSEMS宏时,啥也不干。也就是说即使owenr指向的task_struct // 字段已经退出临界区了,也不会将这个task_struct字段清除或重新赋值(我们假设没有新的 // reader进入临界区),所以在我们分析dump文件时,如果临界区是reader时,owner的 // task_struct字段所指向的线程并不一定在临界区 static inline void rwsem_clear_reader_owned(struct rw_semaphore *sem) { } #endif |
6.7.2 clear_wr_nonspinnable - 只清除RWSEM_WR_NONSPINNABLE标记,优先让writer通过自旋拿锁
由下面的注释可知,该函数仅在所有reader退出临界区时才会被调用,该函数共有下面两个调用位置:
a) 在__up_read中,也就是所有reader退出临界区的时候,发现wait_list链表上有人等着的时候,会清除RWSEM_WR_NONSPINNABLE标记
b) 在rwsem_down_read_slowpath中,当一个reader因申请不到锁被挂入wait_list后,发现临界区没人了
清除RWSEM_WR_NONSPINNABLE标记后,后续的writer再申请锁时,会先尝试自旋,而不是直接进入D状态。那么既然临界区没人了,为什么只清除RWSEM_WR_NONSPINNABLE而不清除RWSEM_RD_NONSPINNABLE呢?由下面的注释可知,所有的reader都退出临界区之后,说明这个rwsem可能已经被reader持有了很长一段时间,这时候只将RWSEM_WR_NONSPINNABLE清除是为了确保优先让writer获取到锁,因为这时候后来的reader可能会直接进D状态,而后来的writer会尝试自旋拿锁
|
/* * Clear the owner's RWSEM_WR_NONSPINNABLE bit if it is set. This should * only be called when the reader count reaches 0. * * This give writers better chance to acquire the rwsem first before * readers when the rwsem was being held by readers for a relatively long * period of time. Race can happen that an optimistic spinner may have * just stolen the rwsem and set the owner, but just clearing the * RWSEM_WR_NONSPINNABLE bit will do no harm anyway. */ static inline void clear_wr_nonspinnable(struct rw_semaphore *sem) { //如果确实设置了该标记位,则清除掉 if (rwsem_test_oflags(sem, RWSEM_WR_NONSPINNABLE)) atomic_long_andnot(RWSEM_WR_NONSPINNABLE, &sem->owner); } |
6.7.3 rwsem_test_oflags - 检查owner的某个标记位是否被设置
|
/* * Test the flags in the owner field. */ static inline bool rwsem_test_oflags(struct rw_semaphore *sem, long flags) { return atomic_long_read(&sem->owner) & flags; } |
七、写操作
申请锁的人是想以写的身份进入临界区
7.1 down_write - 拿不到锁进D状态
|
/* * lock for writing */ void __sched down_write(struct rw_semaphore *sem) { might_sleep(); rwsem_acquire(&sem->dep_map, 0, 0, _RET_IP_); LOCK_CONTENDED(sem, __down_write_trylock, __down_write); } |
7.2 __down_write_trylock - 快速路径,无人拿锁时直接获取到锁
|
static inline int __down_write_trylock(struct rw_semaphore *sem) { long tmp;
DEBUG_RWSEMS_WARN_ON(sem->magic != sem, sem);
//如果当前临界区没人持锁的话,则直接获取到锁,并打上RWSEM_WRITER_LOCKED标记 tmp = RWSEM_UNLOCKED_VALUE; if (atomic_long_try_cmpxchg_acquire(&sem->count, &tmp, RWSEM_WRITER_LOCKED)) { rwsem_set_owner(sem); return true; } return false; } |
7.2.1 rwsem_set_owner - writer拿到锁时将current设置为owner
|
/* * All writes to owner are protected by WRITE_ONCE() to make sure that * store tearing can't happen as optimistic spinners may read and use * the owner value concurrently without lock. Read from owner, however, * may not need READ_ONCE() as long as the pointer value is only used * for comparison and isn't being dereferenced. */ static inline void rwsem_set_owner(struct rw_semaphore *sem) { //该函数一定是writer进入临界区的时候才会调用,需要注意的是,该函数在设置 //owner的同时,还将下面三个标记位清空了: //a) RWSEM_READER_OWNED : 这个很好理解,因为当前是writer进入临界区 //b) RWSEM_RD_NONSPINNABLE : 后来的reader有可以通过自旋的方式去拿锁了 //c) RWSEM_WR_NONSPINNABLE : 后来的writer有可以通过自旋的方式去拿锁了 atomic_long_set(&sem->owner, (long)current); } |
7.3 __down_write
|
/* * lock for writing */ static inline void __down_write(struct rw_semaphore *sem) { long tmp = RWSEM_UNLOCKED_VALUE;
//为啥在这里又试一次呢???? if (unlikely(!atomic_long_try_cmpxchg_acquire(&sem->count, &tmp, RWSEM_WRITER_LOCKED))) rwsem_down_write_slowpath(sem, TASK_UNINTERRUPTIBLE); else rwsem_set_owner(sem); } |
7.4 rwsem_down_write_slowpath - 慢速持锁路径
|
/* * Wait until we successfully acquire the write lock */ static struct rw_semaphore * rwsem_down_write_slowpath( struct rw_semaphore *sem, int state) //线程挂在链表上的状态 { long count; bool disable_rspin;
//0.注意,这个wstate是一个局部变量,每个任务的栈空间都有一个, // 也就是说该变量是针对正在申请锁的这个writer的 //注意: // RWSEM_FLAG_HANDOFF和WRITER_HANDOFF的区别,前者针对整个锁, // 后者针对本writer,因为wstate是一个局部变量,每一个申请锁的 // writer线程的任务栈里面都有一个wstate变量,所以WRITER_HANDOFF // 是针对一个指定的线程 enum writer_wait_state wstate; struct rwsem_waiter waiter; struct rw_semaphore *ret = sem; DEFINE_WAKE_Q(wake_q);
/* do optimistic spinning and steal lock if possible */ //1.尝试通过乐观自旋的方式去拿锁 if (rwsem_can_spin_on_owner(sem, RWSEM_WR_NONSPINNABLE) && rwsem_optimistic_spin(sem, true)) { /* rwsem_optimistic_spin() implies ACQUIRE on success */ return sem; }
//2.代码走到这里,表示乐观自旋拿锁失败,下面进入睡眠逻辑
/* * Disable reader optimistic spinning for this rwsem after * acquiring the write lock when the setting of the nonspinnable * bits are observed. */ //3.记录锁的RWSEM_NONSPINNABLE标记,以便在后面恢复,为啥捏???? disable_rspin = atomic_long_read(&sem->owner) & RWSEM_NONSPINNABLE;
/* * Optimistic spinning failed, proceed to the slowpath * and block until we can acquire the sem. */ //4.准备waiter结构,阻塞超过4ms后设置RWSEM_FLAG_HANDOFF waiter.task = current; waiter.type = RWSEM_WAITING_FOR_WRITE; waiter.timeout = jiffies + RWSEM_WAIT_TIMEOUT;
raw_spin_lock_irq(&sem->wait_lock);
/* account for this before adding a new element to the list */ //5.标记新插进来的writer是不是链表上的第一个 wstate = list_empty(&sem->wait_list) ? WRITER_FIRST : WRITER_NOT_FIRST;
//6.插链表,注意,这里仅仅是插入链表,还没有真正的进入睡眠状态(sleep状态或D状态) list_add_tail(&waiter.list, &sem->wait_list);
/* we're now waiting on the lock */ //7.为了缩短在wait_list上的阻塞时间,唤醒在本writer前面的线程!
// 满足该条件,表示刚插进来的writer并不是链表最前面的线程, // 前面还有其他线程,这时候将前面阻塞的线程唤醒,为啥捏?? // 试想,wait_list链表上的线程的唤醒顺序一定是从前向后依次 // 唤醒的,当前我是一个writer插在链表的末尾,一定要等到前 // 面的线程全部被唤醒后才能有机会唤醒我,所以如果当前临界区 // 没人或者全是reader的时候,还不如先唤醒一波线程进入临界 // 区赶紧处理,这样我这个writer也可以少等一会,缩短阻塞时间 if (wstate == WRITER_NOT_FIRST) { count = atomic_long_read(&sem->count);
/* * If there were already threads queued before us and: * 1) there are no active locks, wake the front * queued process(es) as the handoff bit might be set. * 2) there are no active writers and some readers, the lock * must be read owned; so we try to wake any read lock * waiters that were queued ahead of us. */ //7.1 对于rwsem来说,如果临界区是writer时,则其他任何 // 线程都不能进入临界区,所以此时无法唤醒任何线程 if (count & RWSEM_WRITER_MASK) goto wait;
//7.2 代码走到这里,说明临界区要么没人,要么是reader在临界区, // 但是不管是哪种情况,都可以唤醒一波线程 // a) 如果临界区是reader的话,则唤醒前面的reader // b) 如果临界区没人的话,则根据链表最前面的线程是reader // 还是writer决定唤醒谁 rwsem_mark_wake(sem, (count & RWSEM_READER_MASK) ? RWSEM_WAKE_READERS : RWSEM_WAKE_ANY, &wake_q);
if (!wake_q_empty(&wake_q)) { /* * We want to minimize wait_lock hold time especially * when a large number of readers are to be woken up. */ raw_spin_unlock_irq(&sem->wait_lock); wake_up_q(&wake_q); wake_q_init(&wake_q); /* Used again, reinit */ raw_spin_lock_irq(&sem->wait_lock); } } else { //7.3 代码走到这里,表示在这个writer插链表之前,链表上是空的, // writer插入链表后,自己就是链表最前面的线程了,也就不需要 // 再唤醒其他人,并且因为链表上第一次有了waiter,此时设置 // RWSEM_FLAG_WAITERS标记 atomic_long_or(RWSEM_FLAG_WAITERS, &sem->count); }
wait: /* wait until we successfully acquire the lock */ //8.下面进入阻塞状态(sleep状态或D状态),直到真正的拿到锁才会 // 退出下面的循环。需要注意的是,下面是两个嵌套的循环,外循环只 // 有在真正的拿到锁才退出 set_current_state(state); for (;;) { //9.唤醒后尝试获取锁,成功拿锁后退出外循环 if (rwsem_try_write_lock(sem, wstate)) { /* rwsem_try_write_lock() implies ACQUIRE on success */ break; }
raw_spin_unlock_irq(&sem->wait_lock);
/* * After setting the handoff bit and failing to acquire * the lock, attempt to spin on owner to accelerate lock * transfer. If the previous owner is a on-cpu writer and it * has just released the lock, OWNER_NULL will be returned. * In this case, we attempt to acquire the lock again * without sleeping. */ //10.由上面的注释可知,如果刚刚被唤醒的writer被打上WRITER_HANDOFF // 标记,则说明这个writer已经很急迫了(此时他一定是wait_list链表 // 前面第一个线程),此时如果临界区没人,此时就不要再睡眠了,直接跳转 // 到trylock_again再次尝试获取锁,直到这把锁已经被别人拿走,才会重 // 新进入睡眠状态
// rwsem_spin_on_owner在下面场景中会返回OWNER_NULL // a) 当前临界区没人,直接返回OWNER_NULL,根本不会乐观自旋 // b) 上一个锁的owner是一个writer,这个writer退出临界区后, // 没有其他人拿锁进入临界区,此时也会返回OWNER_NULL if (wstate == WRITER_HANDOFF && rwsem_spin_on_owner(sem, RWSEM_NONSPINNABLE) == OWNER_NULL) goto trylock_again;
/* Block until there are no active lockers. */ //11.代码走到这里,则有下面两种可能,则但是不管是哪种,都躲不了进睡眠状 // 态了(sleep状态或D状态) // a) 要么本writer当前并不是很急迫(还没有设置WRITER_HANDOFF标记, // 可能其不是链表最前面的线程,或者阻塞等待没有超时),此时肯定要先 // 执行链表最前面的线程啊,本writer也只能进睡眠状态了(即sleep状 // 态或D状态,对于哪些处于sleep状态,并被kill等信号唤醒的线程, // 在下面for循环刚开始的时候识别到由未处理的信号就退出了) // b) 要么本writer虽然当前已经很急迫(WRITER_HANDOFF标记已经被设置), // 但是此时临界区是有人的,此时writer也只能进睡眠状态了(sleep状 // 态或D状态) for (;;) { //11.1 在下一次唤醒的时候,首先检查是否有挂起的信号等待处理, // 如果有挂起的信号等待处理,则跳转到out_nolock,此时就 // 拿锁失败了,例如kill等信号是可以唤醒这些睡眠的writer // 的,当然,这里说的睡眠状态的writer是指sleep状态,对 // 于D状态,是无法响应信号的 if (signal_pending_state(state, current)) goto out_nolock;
//11.2 代码走到这里,表示没有需要处理的信号,继续进睡眠状态(sleep // 状态或D状态),只有下面两种情况才会唤醒这个writer,才会从 // schedule中退出: // a) 被kill等信号唤醒(只针对sleep状态的writer) // b) 临界区没人了,退出临界区时被唤醒wait_list上阻塞的线程 schedule(); lockevent_inc(rwsem_sleep_writer);
//11.3 被唤醒后重新设置状态睡眠状态(sleep状态),因为此时还不一定 // 能获取到锁,防止其被调度执行 set_current_state(state);
/* * If HANDOFF bit is set, unconditionally do * a trylock. */ //11.4 如果设置了WRITER_HANDOFF标记,则表示当前这个writer // 已经是链表最前面的线程,并且已经很急迫了,此时无条件的 // 退出内循环,在外循环中重新尝试拿锁 //注意: // 处于sleep状态的writer被kill唤醒,在这里是有可能拿 // 到锁的,拿到锁访问完临界区,在下一个退货用户空间的时候 // 处理pending的型号,这时候才真正的被杀死 if (wstate == WRITER_HANDOFF) break;
//11.5 本writer睡了一段时间后被唤醒,wait_list前面可能有线程进 // 入临界区,本writer在wait_list链表上的位置可能已经发生了 // 变化,此时重新判断本writer是不是链表最前面的线程,如果是, // 则设置WRITER_FIRST标记 //注意: // 这里你可以有这样的疑惑,既然这个writer都被唤醒了,那么他怎 // 么可能不是wait_list链表最前面的线程呢?对于writer的唤醒不 // 是严格的从先往后的顺序唤醒的吗? // 我们在上面讲过,唤醒有两种情况: // a) 如果是因为临界区空了,被退出临界区的线程唤醒的,那么这个 // writer必定是wait_list链表前面的线程 // b) 但是如果这个writer是被kill等异常信号唤醒的,那么他就 // 不一定是链表最前面的线程了哦 if ((wstate == WRITER_NOT_FIRST) && (rwsem_first_waiter(sem) == &waiter)) wstate = WRITER_FIRST;
//11.6 如果当前临界区没人了,则退出内循环,尝试在外循环中拿锁 // 这里你可能有这样的疑问:老子都被唤醒了,临界区可能有人 // 那为啥唤醒我,既然唤醒我必然是没人啊!!!实际上根据上面 // 吗?的分析,唤醒由两种可能: // a) 被kill信号唤醒,此时无法确定临界区是否有人。 // 如果此时临界区有人则继续向下进入内存换,被信号唤醒的 // 线程会在下一次内循环中处理kill信号;但是只要临界区 // 没人的话,就退出内循环,在外循环中尝试拿锁,所以kill // 的线程还是有可能拿到锁的(当然是哪些处于sleep状态的 // 线程,D状态时不会响应信号的) // b) 被退出临界区的线程唤醒,此时临界区实际上也不一定是空的。 // 因为在我们刚被唤醒时,可能出现锁被一个自旋的申请者拿走了, // 也就是说锁被"偷"了,这时候临界区也不是空的 count = atomic_long_read(&sem->count); if (!(count & RWSEM_LOCK_MASK)) break;
/* * The setting of the handoff bit is deferred * until rwsem_try_write_lock() is called. */ //11.7 代码走到这里,说明临界区里面还有人 // 由上面的分析可知,锁被"偷"了可能会导致我这个writer长时间 // 获取不到锁,这不公平,所以,当我们阻塞的时间超过4ms时,会设 // 置WRITER_HANDOFF标记,(在rwsem_try_write_lock中会根据 // WRITER_HANDOFF标记对锁打上RWSEM_FLAG_HANDOFF标记),禁止其 // 他线程通过自旋的方式拿锁,也就是防止锁被"偷"了 // 需要注意的是,如果当前阻塞的线程是rt线程,为了不让rt线程阻 // 塞太长时间,这里也设置WRITER_HANDOFF标记,而不管是否会超时 if ((wstate == WRITER_FIRST) && (rt_task(current) || time_after(jiffies, waiter.timeout))) { wstate = WRITER_HANDOFF; lockevent_inc(rwsem_wlock_handoff); break; } } trylock_again: raw_spin_lock_irq(&sem->wait_lock); }
//12.代码走到这里表示writer已经成功拿到锁,下面设置状态,并将其从wait_list上摘下来 __set_current_state(TASK_RUNNING); list_del(&waiter.list);
//13.如果这个writer在阻塞之前,这把锁被打上了nospin标记,则在拿到锁之后恢复,为啥捏 rwsem_disable_reader_optspin(sem, disable_rspin); raw_spin_unlock_irq(&sem->wait_lock); lockevent_inc(rwsem_wlock);
return ret;
out_nolock: //14.代码走到这里,一定是收到了kill等信号退出了,拿锁失败 __set_current_state(TASK_RUNNING); raw_spin_lock_irq(&sem->wait_lock); list_del(&waiter.list);
//14.1 取消RWSEM_FLAG_HANDOFF标记, // 只要这个线程被设置了WRITER_HANDOFF,那么其一定是链表最前面的线程了, // 此时如果他被kill掉的话,不应该把RWSEM_FLAG_HANDOFF标记继续保留着, // 因为RWSEM_FLAG_HANDOFF是针对全局的(而WRITER_HANDOFF是针对当前这 // 个writer的) if (unlikely(wstate == WRITER_HANDOFF)) atomic_long_add(-RWSEM_FLAG_HANDOFF, &sem->count);
//14.2 如果链表上为空了,则清除将RWSEM_FLAG_WAITERS标记清零,否则,继续唤醒一波 // 这里唤醒链表上的其他线程的原因和上面一样,都是为了使wait_list上的线程阻塞 // 的时间短一些 if (list_empty(&sem->wait_list)) atomic_long_andnot(RWSEM_FLAG_WAITERS, &sem->count); else rwsem_mark_wake(sem, RWSEM_WAKE_ANY, &wake_q); raw_spin_unlock_irq(&sem->wait_lock); wake_up_q(&wake_q); lockevent_inc(rwsem_wlock_fail);
return ERR_PTR(-EINTR); } |
7.4.1 writer_wait_state - 标记正在申请writer锁的线程的状态
a) WRITER_NOT_FIRST: writer不是wait_list链表最前面的线程
b) WRITER_FIRST: writer是wait_list链表最前面的线程
c) WRITER_HANDOFF: writer不是wait_list链表最前面的线程,并且handoff
|
enum writer_wait_state { WRITER_NOT_FIRST, /* Writer is not first in wait list */ WRITER_FIRST, /* Writer is first in wait list */ WRITER_HANDOFF /* Writer is first & handoff needed */ }; |
7.4.2 rwsem_try_write_lock - 尝试获取锁或者设置RWSEM_FLAG_HANDOFF标记
本函数完成的操作:要么成功拿到锁,要么设置RWSEM_FLAG_HANDOFF标记。
锁的状态和线程的状态共有下面6种场景,下面依次分析这6种场景完成的操作
|
场景 |
锁状态 |
线程状态 |
|
1 |
has_handoff |
WRITER_NOT_FIRST |
|
2 |
has_handoff |
WRITER_FIRST |
|
3 |
has_handoff |
WRITER_HANDOFF |
|
4 |
!has_handoff |
WRITER_NOT_FIRST |
|
5 |
!has_handoff |
WRITER_FIRST |
|
6 |
!has_handoff |
WRITER_HANDOFF |
函数实现如下:
|
/* * This function must be called with the sem->wait_lock held to prevent * race conditions between checking the rwsem wait list and setting the * sem->count accordingly. * * If wstate is WRITER_HANDOFF, it will make sure that either the handoff * bit is set or the lock is acquired with handoff bit cleared. */ static inline bool rwsem_try_write_lock( struct rw_semaphore *sem, enum writer_wait_state wstate) //记录当前正在申请锁的线程的状态 { long count, new;
lockdep_assert_held(&sem->wait_lock);
count = atomic_long_read(&sem->count); do { //1.记录这把锁是否设置了RWSEM_FLAG_HANDOFF标记 bool has_handoff = !!(count & RWSEM_FLAG_HANDOFF);
//2.下面两个条件对应上面表格中的场景1 // a) has_handoff: 禁止"偷锁",wait_list链表最前面的线程很急迫 // b) WRITER_NOT_FIRST: 当前这个writer并不是链表最前面的的线程
// 因为本函数的作用是:要么拿到锁,要么设置RWSEM_FLAG_HANDOFF标记 // 但是现在RWSEM_FLAG_HANDOFF标记已经被别人抢先设置了,并且当前本 // writer也不是链表最前面的线程,所以这里的RWSEM_FLAG_HANDOFF标记 // 对本writer是无效的。这种场景啥也干不了,直接返回 if (has_handoff && wstate == WRITER_NOT_FIRST) return false;
new = count;
//3.上面表格中场景2,3,4,5,6会走到这里 if (count & RWSEM_LOCK_MASK) { //3.1 进入该分支表示临界区有人,此时无论如何这个writer都不能拿 // 到锁,顶多是设置RWSEM_FLAG_HANDOFF标记就退出了,以便在 // 下一次拿锁
// 下面if条件对应上表中场景2,3,4,5,直接返回 // 对于场景2,3: RWSEM_FLAG_HANDOFF标记已经被设置上了,无需 // 重复设置,并且因为此时这个writer是链表最前 // 面的线程,下一次锁交接的时候就能获取锁; // 对于场景4: 因为此时本writer并不是wait_list链表最前面的 // 线程,此时即使是设置了RWSEM_FLAG_HANDOFF标记 // 对自己也是无效的,所以也不需要设置 // 对于场景5: 虽然锁的RWSEM_FLAG_HANDOFF标记没有被设置上, // 并且此时本writer也已经是wait_list链表最前面 // 的线程了,但是这个writer阻塞的时间还不够,还不 // 够紧急,没有被打上WRITER_HANDOFF标记,此时也 // 不用设置RWSEM_FLAG_HANDOFF标记 if (has_handoff || (wstate != WRITER_HANDOFF)) return false;
//3.2 只有上面场景6才会走到这里 // 此时锁没有被标记RWSEM_FLAG_HANDOFF,并且这个waiter已经是 // wait_list链表最前面的线程,并且已经很紧急了。已经被打上了 // WRITER_HANDOFF标记,这时候对这把锁标记RWSEM_FLAG_HANDOFF // 后,在下一个锁交换的时候就能够拿到锁 new |= RWSEM_FLAG_HANDOFF; } else { //3.3 进入该分支,表示当前临界区已经没人了,此时任何线程都可以通过 // 原子操作公平的竞争这把锁,而不管其在链表中的位置,即使它不是 // 链表最前面的线程
// 上面表格中场景2,3,4,5,6都能走到这,但是需要注意的是,对于场 // 景2,3表示锁已经被打上了RWSEM_WRITER_LOCKED标记,并且本writer // 就是wait_list链表最前面的线程,下一个锁交换时,一定会将锁交 // 给本writer
// a) writer即将进入临界区,打上RWSEM_WRITER_LOCKED标记 // b) 如果已经设置了RWSEM_FLAG_HANDOFF标记,则清除,未设置的话 // 则本身就是0 new |= RWSEM_WRITER_LOCKED; new &= ~RWSEM_FLAG_HANDOFF;
//3.4 如果链表上只有本writer一个线程在等锁了,那么成功 // 拿锁后将RWSEM_FLAG_WAITERS清除 if (list_is_singular(&sem->wait_list)) new &= ~RWSEM_FLAG_WAITERS; }
//4.进行xchg操作 // a) 如果sem->count和count不相等,则说明锁的状态已经发生变化,此时根本就不 // 会进行xchg操作,原子操作返回false,循环继续,继续下一次xchg // b) 如果sem->count和count相等,则进行xchg操作,但是如果在原子操作期间, // 锁可能被其他cpu上的其他线程拿走了,锁的状态又发生了变化,则原子操作也返 // 回false,循环继续,继续下一次xchg // c) 如果sem->count和count相等,则进行xchg操作,如果成功完成xchg操作, // 则原子操作返回true,循环结束 // 需要注意的是,这里的count变量在每次执行完原子操作后(不管原子操作是否成功), // 都会被重新赋值的 } while (!atomic_long_try_cmpxchg_acquire(&sem->count, &count, new));
/* * We have either acquired the lock with handoff bit cleared or * set the handoff bit. */ //5.代码走到这里,仅表示上面xchg已经成功了,但是这并不表示已经成功拿到锁了, // 由上面分析可知,如果临界区有人,这个writer是拿不到锁的,顶多是对锁设置 // RWSEM_FLAG_HANDOFF标记。所以代码走到这里有下面两种情况 // a) 已经拿到了锁,并且将RWSEM_FLAG_HANDOFF标记清除 // b) 或者根本没有拿到锁,但是已经设置了RWSEM_FLAG_HANDOFF标记 if (new & RWSEM_FLAG_HANDOFF) return false;
//6.代码走到这表示成功拿到锁,设置owner后退出 rwsem_set_owner(sem); return true; } |
7.5 up_write
|
/* * release a write lock */ void up_write(struct rw_semaphore *sem) { rwsem_release(&sem->dep_map, _RET_IP_); __up_write(sem); } |
7.6 __up_write
|
/* * unlock after writing */ static inline void __up_write(struct rw_semaphore *sem) { long tmp;
DEBUG_RWSEMS_WARN_ON(sem->magic != sem, sem); /* * sem->owner may differ from current if the ownership is transferred * to an anonymous writer by setting the RWSEM_NONSPINNABLE bits. */ DEBUG_RWSEMS_WARN_ON((rwsem_owner(sem) != current) && !rwsem_test_oflags(sem, RWSEM_NONSPINNABLE), sem);
//1.因为rwsem只允许一个writer在临界区,所以当这个writer退出临界区时,会直接 // 将sem->owner设置为0,不仅清除了task_struct字段,还清除了nonspin标记 rwsem_clear_owner(sem);
//2.count字段将RWSEM_WRITER_LOCKED标记清零,表示当前不是write在临界区 tmp = atomic_long_fetch_add_release(-RWSEM_WRITER_LOCKED, &sem->count);
//3.如果链表中还有其他线程在等这把锁,则唤醒链表最前面的线程 if (unlikely(tmp & RWSEM_FLAG_WAITERS)) rwsem_wake(sem, tmp); } |
7.6.1 rwsem_clear_owner - writer退出临界区时清除owner,直接设置为0
因为rwsem只允许一个writer退出临界区,所以当一个writer退出临界区时,临界区一定空了
|
static inline void rwsem_clear_owner(struct rw_semaphore *sem) { //注意:这里直接设置为0,表示nonspinable标记也清零了,后来申请锁的人 // 不管是reader还是writer,都会重新尝试自旋 atomic_long_set(&sem->owner, 0); } |
八、其他扩展接口
8.1 down_read_interruptible - 拿不到锁进sleep
|
int __sched down_read_interruptible(struct rw_semaphore *sem) { might_sleep(); rwsem_acquire_read(&sem->dep_map, 0, 0, _RET_IP_);
if (LOCK_CONTENDED_RETURN(sem, __down_read_trylock, __down_read_interruptible)) { rwsem_release(&sem->dep_map, _RET_IP_); return -EINTR; }
return 0; } |
8.2 down_read_killable - 拿不到锁将自己kill掉
|
int __sched down_read_killable(struct rw_semaphore *sem) { might_sleep(); rwsem_acquire_read(&sem->dep_map, 0, 0, _RET_IP_);
if (LOCK_CONTENDED_RETURN(sem, __down_read_trylock, __down_read_killable)) { rwsem_release(&sem->dep_map, _RET_IP_); return -EINTR; }
return 0; } |
8.3 down_read_trylock - 拿不到锁后也不睡眠
|
/* * trylock for reading -- returns 1 if successful, 0 if contention */ int down_read_trylock(struct rw_semaphore *sem) { int ret = __down_read_trylock(sem);
if (ret == 1) rwsem_acquire_read(&sem->dep_map, 0, 1, _RET_IP_); return ret; } |
8.4 down_write_killable - 拿不到锁后将自己kill掉
|
/* * lock for writing */ int __sched down_write_killable(struct rw_semaphore *sem) { might_sleep(); rwsem_acquire(&sem->dep_map, 0, 0, _RET_IP_);
if (LOCK_CONTENDED_RETURN(sem, __down_write_trylock, __down_write_killable)) { rwsem_release(&sem->dep_map, _RET_IP_); return -EINTR; }
return 0; } |
8.5 down_write_trylock - 拿不到锁后也不睡眠
|
/* * trylock for writing -- returns 1 if successful, 0 if contention */ int down_write_trylock(struct rw_semaphore *sem) { int ret = __down_write_trylock(sem);
if (ret == 1) rwsem_acquire(&sem->dep_map, 0, 1, _RET_IP_);
return ret; } |
九、要点总结
9.1 当reader在临界区时,owner的task_struct字段指向的线程并不一定在临界区
因为rwsem是允许多个reader同时进入临界区的,当有reader退出临界区时,会调用rwsem_clear_reader_owned函数将owner字段清空。但是当没有开启CONFIG_DEBUG_RWSEMS宏时,该函数啥也不干。也就是说可能存在这种情况:即使owenr指向的task_struct字段已经退出临界区了,也不会将这个task_struct字段清除或重新赋值(我们假设没有新的reader进入临界区)。极端情况下,当所有的reader都退出临界区后,这个owner还是指向哪个曾经的reader,所以在我们分析dump文件时,如果临界区是reader时,owner的task_struct字段所指向的线程并不一定在临界区
那么什么时候清除这个task_struct结构呢?难道是当writer进入并退出临界区的时候
9.2 当reader在临界区时,后来的reader能否直接进入临界区?
当reader在临界区时,后来的reader不一定能够直接进入临界区,如果满足下面任一情况,后来的这个reader一定会进入慢速路径(乐观自旋或者睡眠状态),详见__down_read_trylock和rwsem_read_trylock和RWSEM_READ_FAILED_MASK宏的实现
a) RWSEM_FLAG_WAITERS: 有人阻塞在wait_list上
b) RWSEM_FLAG_HANDOFF: 锁已经被打上HANDOFF标记,禁止自旋偷锁
c) RWSEM_FLAG_READFAIL: 临界区的reader已经撑爆了
但是在慢速路径中,如果是reader在临界区,后来的reader是有可能"偷"到锁进入临界区的,除非存在下面情况导致偷锁失败,详见rwsem_try_read_lock_unqueued实现
a) wait_list最前面的线程已经很紧急,锁已经被打上RWSEM_FLAG_HANDOFF
总结:如果临界区的reader没有被撑爆,并且锁没有被置为RWSEM_FLAG_HANDOFF标记,后来的reader可以直接进入临界区的
9.3 什么时候禁止自旋(设置nonspinable标记)
下面两个场景:
a) 当临界区的reader已经撑爆时,会同时设置RWSEM_RD_NONSPINNABLE和RWSEM_WR_NONSPINNABLE标记,详见rwsem_read_trylock
b) 当一个writer处于自旋状态等临界区的reader,并且已经超时了,会同时设置RWSEM_RD_NONSPINNABLE和RWSEM_WR_NONSPINNABLE标记,详见rwsem_optimistic_spin实现。(换句话说,只要wait_list上有writer,后来的申请者,不管是reader还是writer,都一定不能自旋)
9.4 什么时候允许自旋(清除nonspinable标记)
a) 因为rwsem一次只允许一个writer进入临界区,所以当一个writer退出临界区时,临界区一定空了,此时会同时清除RWSEM_WR_NONSPINNABLE和RWSEM_RD_NONSPINNABLE标记,后面再有reader会在writer来申请锁,都可以自旋等锁了,详见__up_writer -> rwsem_clear_owner
b) 当writer进入临界区是,调用rwsem_set_owner,将nonspinable清除,允许reader和writer重新通过自旋拿锁
9.5 什么时候清除RWSEM_WR_NONSPINNABLE,允许writer自旋
a) 每当有新的reader进入临界区的时候,都会调用rwsem_set_reader_owned函数设置锁的owner,但是在rwsem_set_reader_owned接口的实现中会将owner的RWSEM_WR_NONSPINNABLE位被清零,也就是说,只要源源不断的有新的reader进入临界区,RWSEM_WR_NONSPINNABLE位就会一直处于0的状态,也就是说后来的writer都可以尝试自旋等锁了
b) 在rwsem_down_read_slowpath中,当判断当前没人在临界区的时候,将清除RWSEM_WR_NONSPINNABLE标记,表示writer可以自旋了,详见rwsem_down_read_slowpath -> clear_wr_nonspinnable
9.6 什么时候设置handoff
wait_list最前面的线程已经很紧急,锁已经被打上RWSEM_FLAG_HANDOFF
十、参考文档
https://blog.csdn.net/wangpengqi/article/details/8043340
https://www.dazhuanlan.com/yingji_224/topics/1860486
http://www.wowotech.net/kernel_synchronization/504.html
https://www.cnblogs.com/hellokitty2/p/16343272.html
https://blog.csdn.net/wangquan1992/article/details/124863014
https://blog.csdn.net/jianchi88/article/details/123638915
https://zhuanlan.zhihu.com/p/71156910
https://www.jianshu.com/p/a9817c353ef5
https://blog.codingnow.com/2014/12/skynet_spinlock.html

文章评论
非常不错的文章。网站可以考虑支持下 RSS 订阅嘛
CONFIG_LOCK_STAT 宏都是默认关的, LOCK_CONTENDED 相当于只执行了 down_read(sem) down_write(sem) , 没有在LOCK_CONTENDED 里try