关注公众号不迷路:DumpStack
扫码加关注

目录
ARM提供了SWP或LDREX/STREX指令集,这两个指令从RTL层面保证了"在某一时刻,只能有一个CPU成功修改内存中的值"。kernel利用这个特点,实现了atomic和spin等操作,是所有同步操作的基石。
一、术语介绍
1.1 睡眠
睡眠是对线程而言的,是线程的一种特殊状态,此被"睡眠"的对象一定要有一个task_struct结构,也就是说只有线程才能睡眠。
睡眠是当前线程在等待暂时无法获得的资源时,避免当前线程一直占用着CPU,将自己放入一个等待队列中,让出CPU给别的线程使用。一旦资源可用,将由内核相关子系统的代码(如rwsem,mutex的实现代码)唤醒某个等待队列上的部分或全部线程。从这点来说,睡眠也是一种线程间的同步机制。
线程被置为休眠,意味着它处于一种特殊的状态,并且会从调度器的运行队列中移出,这个线程将不在任何CPU上被调度,也就永远不会被运行。直到资源可用时将其重新放回到调度器的运行队列中,之后CPU才可以重新pick此线程运行,此时线程被唤醒后会再次检查是否需要继续休眠(即判断资源是否真的可用?),如果不需要就做清理工作,并将自己的状态调整为TASK_RUNNING。
睡眠的两种状态:
TASK_INTERRUPTIBLE:睡眠的线程能够被中断等信号唤醒,即sleep状态
TASK_UNINTERRUPTIBLE:睡眠的线程不能被中断等信号唤醒,kill也不行,即D状态
1.2 原子操作
在执行某一段代码时,不会被任何情况打断,包括中断、调度、主动让出CPU等
获得自旋锁之后也处于原子上下文
中断服务程序(中断上下文)也是原子上下文
1.3 临界资源 – 数据或外设
一次仅允许一个进程使用的共享资源,例如数据,外设等
1.4 临界区 – 代码
用于访问临界资源的那段代码称为临界区,每次只准许一个线程进入临界区,进入后不允许其他线程进入,也就是说在同一时刻只允许一个线程执行这段代码
1.5 并发源
导致出现多个线程(或中断)对同一共享资源进行访问的原因,主要有以下几个方面:
-
中断:当某个进程在访问某个临界资源的时候发生了中断,随后进入中断处理程序,如果在中断处理程序中也访问了该临界资源,就会造成了对该资源的竞态
-
任务调度:可抢占的操作系统中,存在任务调度。当某个进程在访问某个临界资源的时候发生了任务调度,如果新的进程中也访问了同一临界资源,那么就会造成进程与进程之间的并发
-
多核:多处理器系统上的进程与进程之间是严格意义上的并发,每个处理器都可以独自调度运行一个进程,在同一时刻有多个进程在同时运行。
1.6 自旋
忙等,可能是自旋锁,也可能就是一段for循环(例如后面要讲的乐观自旋)
1.7 什么是同步
在面试中,我们经常会被面试官问到:请解释一下同步的含义,此时,一定要注意这可能是个坑,注意!!!在被问到这个问题时,不要急着回答面试官,一定要向面试官确认一下,同步是那个背景的同步,别没问清楚就开始说哦
1.7.1 同步与异步中的同步
此同步指的是行为的同步
例如一群人在学跳舞,前面还有一个小姐姐在领舞,学舞的人的动作和领舞人的动作是一样的话,此时就是同步的体现
ps:进程/线程中的同步也是此处所指的同步
1.7.2 同步通信与异步通信中的同步
此时的同步是进程之间相互等待的机制
因为要访问临界资源,进程需要依次进入临界区,所以进程之间需要借助某种机制实现进程之间的相互等待,形成一定的制约关系,该过程称为同步
通俗点讲:同步就是为了防止多个进程执行同一段代码,而采取的相互等待的措施
同步:就是说呢,在发出一个调用时,在没有得到结果之前,该调用就不会返回,而是一直在那里等着,直到调用执行结束,此时也获得了该调用的返回值,即就是同步指的是由调用者主动等待这个调用的结果
异步:异步与同步刚好相反,调用在发出之后,这个调用就直接返回了,所以不会立即得到调用结果,而是在调用发出之后立即返回,而调用结果是由被调用者通过状态、通知等方式告知调用者
1.8 阻塞和非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息、返回值)时的状态
1.8.1 阻塞
阻塞调用就是,在调用结果返回之前,当前线程什么也不会做,而是一直在那里等待,直到调用线程得到结果,此时才会返回
1.8.2 非阻塞
非阻塞调用就是在等待的时候,可以去做别的事,只是会轮询的去查看调用线程的状态
1.8.3 同步阻塞
同步阻塞=同步+阻塞
调用结果由调用者主动获取,且是阻塞式的等待着,即就是说调用者会主动的关注调用结果,而且是阻塞式的在那里看着
1.8.4 同步非阻塞
同步非阻塞=同步+非阻塞
调用结果是由调用者主动获取的,但是是非阻塞式的等着,此时的动作是调用结果是由调用者主动获取的,但是他不会在那里傻等着,而是会去做别的事,只不过需要时不时的去看一下程序的执行情况
1.8.5 异步阻塞
异步阻塞=异步+阻塞
调用结果是由被调用者通知给调用者的,而且是阻塞式的在哪里等着,即就是调用者会一直在那里等着,但是不会去看程序执行的怎么样了,而是由被调用者来通知的
1.8.6 异步非阻塞
异步阻塞=异步+阻塞
调用结果是由被调用者告诉调用者的,就是调用者是被动的得知结果的,调用者在等结果的过程中,并不是一直在那里傻等着,而是可以去做自己的事
例如:
你等女朋友去吃饭,女朋友现在的状态就是她还没收拾好,你需要等她
同步阻塞:就是你在等她的时候,只是单纯的等她,不会去做别的事,而且你会主动的看她有没有收拾好,如果好了那就可以出去了
同步非阻塞:就是再等她的同时你可以做别的事,例如一边等她一边做题,但是他有没有收拾好是你自己主动去看的,而不是由她通知你
异步阻塞:就是你在等她的时候,什么也不能做,只能做一件事那就是等她,而且不会去关注她什么时候收拾好,等她收拾好,告诉你一声,此时你就会得知她已经可以收拾好了可以出去了,即就是你是被动的知道她收拾好的这个结果的
异步非阻塞:就是你在等她的时候,你可以去做别的事,可以一边等她一边做自己的事,但是此时还是不会主动的去关注她什么时候时候好,直到她通知你,她已经可以出去了,此时你才会得知这个结果,你是被动的知道的
二、同步原理
2.1 单CPU – 运行临界区的代码时不能被打断
在单CPU结构中,线程是宏观上并行,微观上串行,也就是说,在某一个时刻,CPU上只有一个线程在运行。此时同步实际上就归结于临界区的保护,在单CPU的结构中,由上面对并发源的介绍可知,对临界区的保护需要保证以下几点:
-
在执行临界区的代码时,不会产生线程调度
-
在执行临界区的代码时,不会产生中断,或即使产生了中断,中断服务程序也不会影响到相关资源
-
当不能关闭中断时,对临界资源的访问能够通过原子指令完成,因为在执行某条汇编指令期间是不可能被打断的,这也是为什么CPU指令集中要支持"测试并设置"和"测试并清除"原子指令的原因。
总结:运行临界区代码时不能被打断!
2.2 多CPU – 同一时刻只能由一个cpu修改内存中的变量
但是对于SMP系统来说,即使是原子操作指令,也可能被其他CPU"打断",以"测试并设置"指令为例,虽然是原子指令,依然经历了"读 – 改 – 写"三个微操作,在单CPU上,这三个连续的操作一气呵成,执行这个连续的操作时,不会被其他进程所打断。但是在多CPU时,可能存在多个CPU对同一个变量进行"读 – 改 – 写"的操作,进而造成错误,(不考虑硬件加锁的原子指令)。也就是说,在SMP结构中,原子操作将不再是原子的了。
对于x86来说,为了防止原子指令被打断,提供了在指令执行期间对总线加锁的机制,具体的是在执行某一条指令时,加上前缀lock。总线加锁后,总线上的其他CPU就不能通过总线访问内存了,保证了在同一时刻只能有一个CPU访问内存里面的临界资源,从而保证了指令的原子性。
ARM采用的方法和x86类似,提供下面两组机制:
-
提供swp/swpb汇编指令,在访问内存的时候对总线加锁,这样在同一时刻只能有一个cpu对变量进行"读 – 改 – 写"
-
提供ldrex/strex汇编指令,提供内存监视器模块,多cpu可以同时读取该变量的值,但是同一时刻只能有一个cpu成功修改该变量的值,(即将修改后的值写入内存)
三、SWP/SWPB指令 – ARMv6之前,无SMP,锁住总线
类似于上面x86的加锁机制,在ARMv6之前的版本,提供了SWP和SWPB两条汇编指令,在执行这两个指令访问内存时,系统的硬件机制会对内存总线上锁,从而实现即使在多CPU时,总线上的其他CPU也不能通过总线访问内存中的数据,保证了在同一时刻只能有一个CPU访问内存里面的临界资源,从而保证了指令的原子性。
|
swpb rd, rm, [rn] swp rd, rm, [rn] |
|

四、LDREX/STREX指令 – ARMv6之后,存在SMP,内存独占访问
什么是独占访问?字面意思就是某一时刻只有一个CPU能够访问
4.1 Exclusive Monitor - 内存独占监视器
在ARM系统中,内存有两种属性,即共享和非共享。共享意味着该段内存可以被系统中任何处理器访问到,而非共享意味着该段内存只能被系统中的一个处理器所访问到,对别的处理器来说不可见。为了实现内存独占访问,ARM系统中还特别提供了所谓独占监视器Exclusive Monitor的东西,其结构如下:
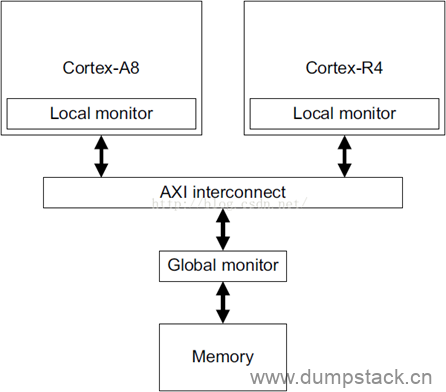
独占监视器Exclusive Monitor分两部分组成,即本地监视器Local Monitor和全局监视器Global Monitor,如果要对非共享内存进行独占访问,只涉及Local Monitor,而如果要对共享内存进行独占访问,除了涉及Local Monitor外,还涉及到Global Monitor。
Local Monitor只标记了本处理器对某段内存的独占访问,在调用LDREX指令时设置独占访问标志,在调用STREX指令时清除独占访问标志。而Global Monitor则可以标记每个处理器对某段内存的独占访问。也就是说,当一个处理器调用LDREX访问某段共享内存时,Global Monitor只会设置针对该处理器的独占访问标记,不会影响到其它的处理器。当在以下两种情况下,会清除某个处理器的独占访问标记:
-
当该处理器再次调用LDREX指令,申请独占访问另一段内存时
-
当别的处理器成功更新了该段独占访问内存值时
对于第二种情况,即当独占内存访问内存的值在任何情况下,被任何一个处理器更改过之后,所有申请独占该段内存的处理器的独占标记都会被清空。另外,此处更新内存的操作不一定非要是STREX指令,任何其它存储指令都可以。
关于监视器怎样被标志为独占的,涉及硬件原理,暂不分析
4.2 LDREX/STREX原理讲解
从ARMv6之后,ARM摒弃了SWP和SWPB指令,并提供LDREX和STREX两条指令。
LDREX指令格式如下,该指令与LDR指令类似,将[R0]对应的的内存中的数据加载进R1,并在Local Monitor和Global Monitor中设置当前CPU对该段内存的独占访问。
|
LDREX R1, [R0] |
STREX指令的格式如下,STREX在写内存之前,芯片的RTL逻辑首先会判断在Local Monitor和Global Monitor中,是否已经将该段内存设置为独占访问了,若已经设置,则将Rm的值写回[Rn]对应的内存,并将Rd清零。否则不会执行内存写入操作,并将Rd置一返回,因此可以通过Rd的值判断写内存是否成功。
|
STREX Rd, Rm, [Rn] |
备注:在使用LDREX访问某个具体的地址Memory_address的内存时,监视器会将一段内存都添加独占访问,被添加独占监视的内存的起始地址为Tagged_address,两者关系如下,其中a的值是由具体的RTL设计决定的,也就是说是CPU在RTL级布线的时候就定下来了,取值为[3, 11]
|
Tagged_address = Memory_address[31:a] |
例如a的值为4,则当要独占访问地址为0x000341B4处的内存时,Tagged_address地址为0x000341B,这就意味了将0x000341B0 ~ 0x000341BF之间的内存加入独占访问。
为了更加清楚的说明,下面举一个例子。如下图,假设系统中有两个处理器内核,而一个程序由三个线程组成,其中两个线程被分配到了第一个处理器上,另外一个线程被分配到了第二个处理器上。且他们的执行序列如下:

-
CPU2上的线程3最早执行LDREX,锁定某段共享内存区域。它会相应更新本地监视器和全局监视器。
-
然后,CPU1上的线程1执行LDREX,它也会更新本地监视器和全局监视器。这时在全局监视器上,CPU1和CPU2都对该段内存做了独占标记。
-
接着,CPU1上的线程2执行LDREX指令,它会发现本处理器的本地监视器对该段内存有了独占标记,同时全局监视器上CPU1也对该段内存做了独占标记,但这并不会影响这条指令的操作。
-
再下来,CPU1上的线程1最先执行了STREX指令,尝试更新该段内存的值。它会发现本地监视器对该段内存是有独占标记的,而全局监视器上CPU1也有该段内存的独占标记,则更新内存值成功。同时,清除本地监视器对该段内存的独占标记,还有全局监视器所有处理器对该段内存的独占标记。
-
下面,CPU2上的线程3执行STREX指令,也想更新该段内存值。它会发现本地监视器拥有对该段内存的独占标记,但是在全局监视器上CPU2没有了该段内存的独占标记(前面一步清空了),则更新不成功。
-
最后,CPU1上的线程2执行STREX指令,试着更新该段内存值。它会发现本地监视器已经没有了对该段内存的独占标记(第4步清除了),则直接更新失败,不需要再查全局监视器了。
所以,可以看出来,这套机制的精髓就是,无论有多少个处理器,有多少个地方会申请对同一个内存段进行操作,保证只有最早的更新可以成功,这之后的更新都会失败。失败了就证明对该段内存有访问冲突了。实际的使用中,可以重新用LDREX读取该段内存中保存的最新值,再处理一次,再尝试保存,直到成功为止。
不管是对于上面的swp/swpb还是ldrex/strex,在编程的过程中不会直接使用这两个汇编指令,而是在这两个汇编指令的基础上又封装了一层,以便编程的时候直接调用相关的api。
五、总结
Linux内核同步机制的最底层的原理就是基于ldrex和strex这两条指令
5.1 ldrex – 读数据
该指令实现从内存中读取数据,关键操作如下
-
从内存中读出数据,无论要读取的内存是否被某个CPU独占,都一定能读取成功
-
在Local Monitor和Global Monitor中,标记"指定内存已经被当前CPU独占了"
|
LDREX R1, [R0] |
5.2 strex – 写数据
在写入内存之前,RTL逻辑会先判断Local Monitor和Global Monitor中的标记,若:
-
若指定的内存正在被当前的CPU独占,则执行写内存操作Rm->[Rn];并将Rd=0
-
否则不会执行内存写入操作,并将Rd置一返回
因此可以通过Rd的值来判断是否写入成功
|
STREX Rd, Rm, [Rn] |
注意:当有多个进程使用ldrex和strex指令操作内存中的数据时,读一定都能成功,但是只有最先写的能写成功,后面写的全部失败。

文章评论