关注公众号不迷路:DumpStack
扫码加关注

目录
- 一、为什么要引入uclamp
- 二、system维度的uclamp信息
- 三、cgroup维度的uclamp信息
- 3.1 数据结构
- 3.2 节点: /dev/cpuctl/top-app/cpu.uclamp.*
- 3.2.1 cpu_uclamp_min_write - 设置cpu.uclamp.min
- 3.2.2 cpu_uclamp_max_write - 设置cpu.uclamp.max
- 3.2.3 cpu_uclamp_write
- 3.2.4 cpu_uclamp_min_show - 显示cpu.uclamp.min
- 3.2.5 cpu_uclamp_max_show - 显示cpu.uclamp.max
- 3.2.6 cpu_uclamp_print
- 3.2.7 cpu_uclamp_ls_write_u64 - 写task_group->latency_sensitive
- 3.2.8 cpu_uclamp_ls_read_u64 - 读task_group->latency_sensitive
- 3.3 示例
- 3.4 更新指定group的有效uclamp信息
- 四、task维度的uclamp信息
- 4.1 数据结构
- 4.2 sched_setattr系统调用
- 4.2.1 函数原型
- 4.2.2 sched_setattr系统调用实现
- 4.2.2.1 sys_sched_setattr - sched_setattr系统调用实现
- 4.2.2.2 sched_copy_attr - 拷贝用户空间的sched_attr参数
- 4.2.2.3 sched_setattr - 对指定的task,使能用户空间传入的attr
- 4.2.2.4 __sched_setscheduler - 对指定的task,使能用户空间传入的attr
- 4.2.2.5 uclamp_validate - 校验用户空间设置的uclamp值的有效性
- 4.2.2.6 __setscheduler_uclamp - 系统调用设置的值记录在task->uclamp_req中
- 4.2.2.7 for_each_clamp_id - 遍历每一个类型的uclamp
- 4.2.2.8 uclamp_se_set - 设置uclamp值
- 4.2.3 示例
- 4.3 计算task的util值
- 4.4 rt线程的uclamp信息
- 五、cpu维度的uclamp信息
- 六、参考文档
- 关注公众号不迷路:DumpStack
uclamp共有3个维度:
-
system维度:任何task的uclamp值,不管是uclamp_min还是uclamp_max,都不得大于system维度指定的uclamp值(实现参见uclamp_eff_get)。system维度的uclamp值可通过procfs中的节点设置
-
cgroup维度:任何task的uclamp值,不管是uclamp_min还是uclamp_max,都必须落在所属group指定的uclamp_min ~ uclamp_max之间(这个和system有差异,task的uclamp必须小于system维度的uclamp_min,具体实现参见uclamp_tg_restrict),group维度的uclamp信息可通过cgroup中的节点设置
-
task维度:task的util值不会超过uclamp的范围(具体参见uclamp_task_util实现),可通过sched_setattr系统调用设置
uclamp软件框架如下:
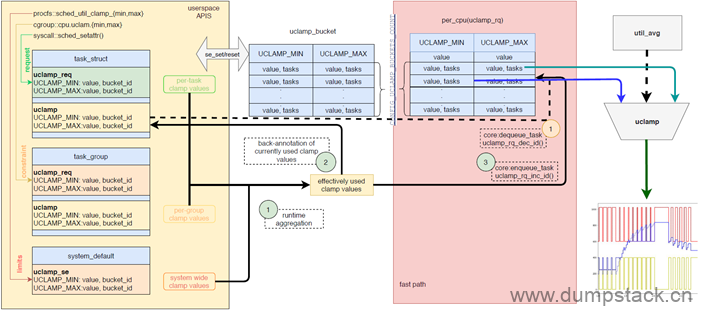
下面分别进行介绍,本文分析基于Linux-5.10.61
一、为什么要引入uclamp
随着linux调度技术的不断演进,目前内核中存在多个调度类(stop、deadline、rt、cfs、idle)以满足不同性质的task的调度需求。对于用户空间来说,CFS和RT调度器是绝大多数任务所使用的,但是基于POSIX Priority接口(通过这些接口可以完成对任务的调度类和优先级的设定)不足以支撑关于选核和调频的调度器特性。而task的性质、性能、功耗等需求用户空间自己是最清楚的,若用户空间能够将这些信息传递给调度器,则能够更好的帮调度器进行任务的调度。uclamp(Utilization Clamping)便是这样一种机制
util存在cpu util和task util两个维度,cpu util标记cpu的繁忙程度,调度器使用此信号驱动cpu的调频;task util用于指示一个task对cpu的使用量,表明一个task是"大"还是"小",此信号可以辅助内核调度器进行选核操作。task util值大就有可能选上大核,cpu util值越大就有可能调到更高的频率。
但是用PELT负载跟踪算法得到的task util与用户空间的期望有时候会出现分歧,比如对于控制线程或UI线程,PELT计算出的util可能较小,认为是"小"task,而用户空间则希望调度器将控制线程或UI线程看作"大"task,以便被调度到高性能核运行在高频点上使任务更快更及时的完成处理。同样地,对于某些长时间运行的后台task,比如日志记录的线程,PELT计算出的task util可能很大,认为是"大"task,但是对于用户空间来说,此类task对于完成时间要求并不高,并不希望被当作"大"task,以利于节省系统功耗和缓解发热。
uclamp提供了一种机制,通过该机制,用户空间可以将指定的task util限制在[util_min, util_max]范围内,而cpu util则是由其rq上的所有task的uclamp的最大值决定(不管是min还是max,都是取最大值,详见uclamp_rq_inc_id中对rq->uclamp[clamp_id]的设置)。通过将util_min设置为一个较大值,使得一个task看起来像一个"大"任务,使cpu运行在高性能状态,加速任务的处理,提升系统的性能表现;对于一些后台任务,通过将util_max设置为较小值,使其看起来像一个"小"任务,使CPU运行在高能效状态,以节省系统的功耗。
关于该feature介绍,可以参考作者在下面的解释,强烈建议读一读,比任何中文翻译都要好,直接copy了
https://lore.kernel.org/lkml/20181029183311.29175-1-patrick.bellasi@arm.com/
|
The Linux scheduler tracks a "utilization" signal for each scheduling entity (SE), e.g. tasks, to know how much CPU time they use. This signal allows the scheduler to know how "big" a task is and, in principle, it can support advanced task placement strategies by selecting the best CPU to run a task. Some of these strategies are represented by the Energy Aware Scheduler [1].
When the schedutil cpufreq governor is in use, the utilization signal allows the Linux scheduler also to drive frequency selection. The CPU utilization signal, which represents the aggregated utilization of tasks scheduled on that CPU, is used to select the frequency which best fits the workload generated by the tasks.
However, the current translation of utilization values into a frequency selection is pretty simple: we just go to max for RT tasks or to the minimum frequency which can accommodate the utilization of DL+FAIR tasks. Instead, utilization is of limited usage for tasks placement since its value alone is not enough to properly describe what the _expected_ power/performance behaviors of each task really is from a userspace standpoint.
In general, for both RT and FAIR tasks we can aim at better tasks placement and frequency selection policies if we take hints coming from user-space into consideration.
Utilization clamping is a mechanism which allows to "clamp" (i.e. filter) the utilization generated by RT and FAIR tasks within a range defined from user-space. The clamped utilization value can then be used, for example, to enforce a minimum and/or maximum frequency depending on which tasks are currently active on a CPU.
The main use-cases for utilization clamping are:
- boosting: better interactive response for small tasks which are affecting the user experience.
Consider for example the case of a small control thread for an external accelerator (e.g. GPU, DSP, other devices). In this case, from the task utilization the scheduler does not have a complete view of what the task requirements are and, if it's a small utilization task, it keep selecting a more energy efficient CPU, with smaller capacity and lower frequency, thus affecting the overall time required to complete task activations.
- capping: increase energy efficiency for background tasks not directly affecting the user experience.
Since running on a lower capacity CPU at a lower frequency is in general more energy efficient, when the completion time is not a main goal, then capping the utilization considered for certain (maybe big) tasks can have positive effects, both on energy consumption and thermal headroom. Moreover, this feature allows also to make RT tasks more energy friendly on mobile systems, where running them on high capacity CPUs and at the maximum frequency is not strictly required.
From these two use-cases, it's worth to notice that frequency selection biasing, introduced by patches 9 and 10 of this series, is just one possible usage of utilization clamping. Another compelling extension of utilization clamping is in helping the scheduler on tasks placement decisions.
Utilization is (also) a task specific property which is used by the scheduler to know how much CPU bandwidth a task requires, at least as long as there is idle time. Thus, the utilization clamp values, defined either per-task or per-taskgroup, can be used to represent tasks to the scheduler as being bigger (or smaller) than what they really are.
Utilization clamping thus ultimately enables interesting additional optimizations, especially on asymmetric capacity systems like Arm big.LITTLE and DynamIQ CPUs, where:
- boosting: small/foreground tasks are preferably scheduled on higher-capacity CPUs where, despite being less energy efficient, they are expected to complete faster.
- capping: big/background tasks are preferably scheduled on low-capacity CPUs where, being more energy efficient, they can still run but save power and thermal headroom for more important tasks.
This additional usage of utilization clamping is not presented in this series but it's an integral part of the EAS feature set, where [1] is one of its main components. A solution similar to utilization clamping, namely SchedTune, is already used on Android kernels to bias both 'frequency selection' and 'task placement'.
This series provides the foundation bits to add similar features to mainline while focusing, for the time being, just on schedutil integration.
[1] https://lore.kernel.org/lkml/20181016101513.26919-1-quentin.perret@arm.com/ |
二、system维度的uclamp信息
system维度的uclamp有下面两个含义:
-
uclamp_max: 系统中所有task的uclamp_max值,都必须小于这个值
-
uclamp_min: 系统中所有task的uclamp_min值,都必须小于这个值
system维度的uclamp信息可通过procfs中的节点"/proc/sys/kernel/sched_util_clamp_*"设置,控制系统中所有task的uclamp值,不管是uclamp_min还是uclamp_max,都小于system维度的uclamp_min和uclamp_max,(详见uclamp_eff_get实现)。
system维度的uclamp_min和uclamp_max的默认值均为1024,表示没有任何限制。
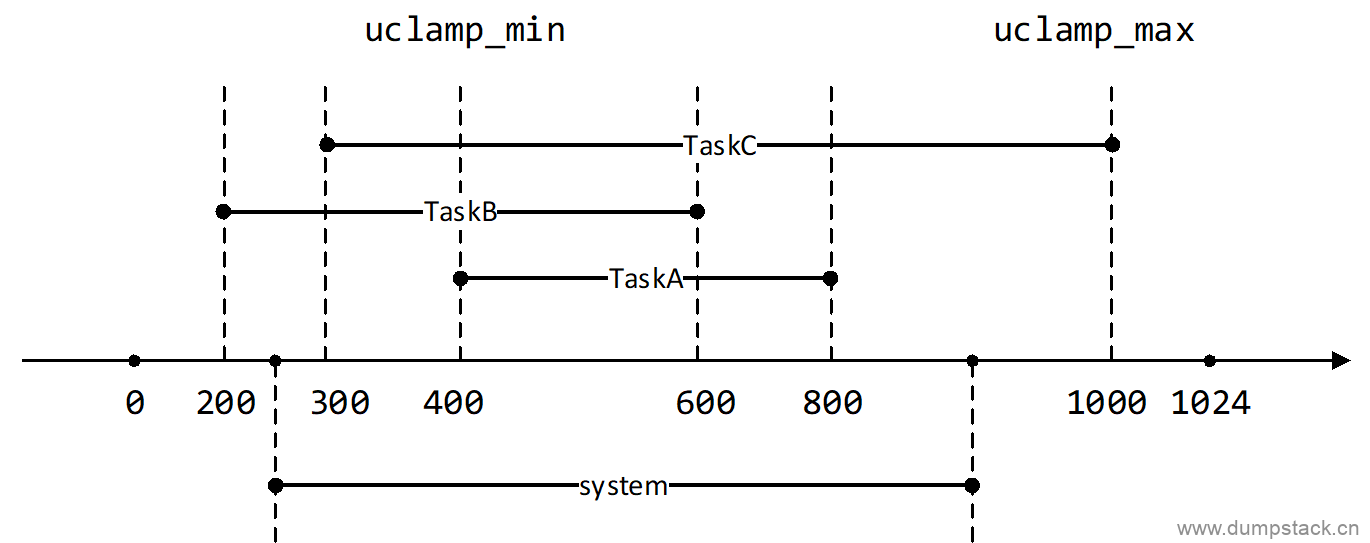
system维度的uclamp需求的提出参见下面patch,由下面的注释可知,当一个task通过系统调用设置了uclamp后,那么他的util值就只能在这个用户空间指定的uclamp_min ~ uclamp_max之间。但是有时候有一些系统控制类的软件希望能够控制系统中的所有task的util值,因此便搞出了system维度的uclamp机制。下面举个栗子:
TaskA的uclamp为[400, 800]
TaskB的uclamp为[200, 600]
TaskC的uclamp为[300, 1000]
system维度的uclamp为[250, 900]
则最终的uclamp为
TaskA的uclamp为[250, 800]
TaskB的uclamp为[200, 600]
TaskC的uclamp为[250, 900]
更多信息参考下面patch

|
Tasks without a user-defined clamp value are considered not clamped and by default their utilization can have any value in the [0..SCHED_CAPACITY_SCALE] range.
Tasks with a user-defined clamp value are allowed to request any value in that range, and the required clamp is unconditionally enforced. However, a "System Management Software" could be interested in limiting the range of clamp values allowed for all tasks.
Add a privileged interface to define a system default configuration via:
/proc/sys/kernel/sched_uclamp_util_{min,max}
which works as an unconditional clamp range restriction for all tasks.
With the default configuration, the full SCHED_CAPACITY_SCALE range of values is allowed for each clamp index. Otherwise, the task-specific clamp is capped by the corresponding system default value.
Do that by tracking, for each task, the "effective" clamp value and bucket the task has been refcounted in at enqueue time. This allows to lazy aggregate "requested" and "system default" values at enqueue time and simplifies refcounting updates at dequeue time.
The cached bucket ids are used to avoid (relatively) more expensive integer divisions every time a task is enqueued.
An active flag is used to report when the "effective" value is valid and thus the task is actually refcounted in the corresponding rq's bucket. |
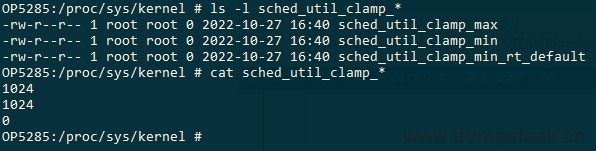
2.1 节点: /proc/sys/kernel/sched_util_clamp_*
用户空间的节点如下,取值范围[0, SCHED_CAPACITY_SCALE],默认前两个文件都是1024,表示没有任何限制;第三个文件是0,这是因为对RT任务只有一个min_clamp的限制
|
a) 设置uclamp_default[],这是system维度的uclamp值,所有uclamp值必须小于该值 b) 设置根组的root_task_group->uclamp_req[]值 /proc/sys/kernel/sched_util_clamp_min /proc/sys/kernel/sched_util_clamp_max
a) 设置到系统中所有rt线程的p->uclamp_req[UCLAMP_MIN] /proc/sys/kernel/sched_util_clamp_min_rt_default |
节点创建位置如下:
W:\opensource\linux-5.10.61\kernel\sysctl.c
|
#ifdef CONFIG_UCLAMP_TASK { .procname = "sched_util_clamp_min", .data = &sysctl_sched_uclamp_util_min, .maxlen = sizeof(unsigned int), .mode = 0644, .proc_handler = sysctl_sched_uclamp_handler, }, { .procname = "sched_util_clamp_max", .data = &sysctl_sched_uclamp_util_max, .maxlen = sizeof(unsigned int), .mode = 0644, .proc_handler = sysctl_sched_uclamp_handler, }, { .procname = "sched_util_clamp_min_rt_default", .data = &sysctl_sched_uclamp_util_min_rt_default, .maxlen = sizeof(unsigned int), .mode = 0644, .proc_handler = sysctl_sched_uclamp_handler, }, #endif |
涉及的全局变量如下:
|
/* Max allowed minimum utilization */ //所有task的uclamp_min都不能超过这个值 unsigned int sysctl_sched_uclamp_util_min = SCHED_CAPACITY_SCALE;
/* Max allowed maximum utilization */ unsigned int sysctl_sched_uclamp_util_max = SCHED_CAPACITY_SCALE;
/* * By default RT tasks run at the maximum performance point/capacity of the * system. Uclamp enforces this by always setting UCLAMP_MIN of RT tasks to * SCHED_CAPACITY_SCALE. * * This knob allows admins to change the default behavior when uclamp is being * used. In battery powered devices, particularly, running at the maximum * capacity and frequency will increase energy consumption and shorten the * battery life. * * This knob only affects RT tasks that their uclamp_se->user_defined == false. * * This knob will not override the system default sched_util_clamp_min defined * above. */ //控制系统中所有rt任务的最小uclamp值 unsigned int sysctl_sched_uclamp_util_min_rt_default = SCHED_CAPACITY_SCALE;
/* All clamps are required to be less or equal than these values */ //system维度的uclamp值,所有uclamp,不管是uclamp_min还是uclamp_max,都必须小于该值 static struct uclamp_se uclamp_default[UCLAMP_CNT]; |
2.2 sysctl_sched_uclamp_handler - 读写节点回调函数
a) 通过sched_util_clamp_[min|max]文件设置的值会设置到全局变量uclamp_default[]中,同时还会设置到全局变量root_task_group::uclamp_req[]中
b) 通过sched_util_clamp_min_rt_default文件设置的值会设置到所有RT任务的p->uclamp_req[UCLAMP_MIN]中,它会在RT任务选核中起作用
|
int sysctl_sched_uclamp_handler( struct ctl_table *table, int write, void *buffer, size_t *lenp, loff_t *ppos) { bool update_root_tg = false; int old_min, old_max, old_min_rt; int result;
mutex_lock(&uclamp_mutex); //1.先记录旧的值 old_min = sysctl_sched_uclamp_util_min; old_max = sysctl_sched_uclamp_util_max; old_min_rt = sysctl_sched_uclamp_util_min_rt_default;
//2.下面接口返回后,上面的三个全局变量就已经被用户空间修改了 result = proc_dointvec(table, write, buffer, lenp, ppos); if (result) goto undo; if (!write) goto done;
//3.检查用户空间设置的值是否合理,不合理的话则还是使用旧的值 if (sysctl_sched_uclamp_util_min > sysctl_sched_uclamp_util_max || sysctl_sched_uclamp_util_max > SCHED_CAPACITY_SCALE || sysctl_sched_uclamp_util_min_rt_default > SCHED_CAPACITY_SCALE) {
result = -EINVAL; goto undo; }
//4.下面检测用户空间修改了那个值 // sysctl_sched_uclamp_util_[min|max]分别设置到 // 全局数组uclamp_default[UCLAMP_MIN|MAX]中去 // 下面传入的参数为false标记这个uclamp值并不是来源于用户空间的系统调用 if (old_min != sysctl_sched_uclamp_util_min) { uclamp_se_set(&uclamp_default[UCLAMP_MIN], sysctl_sched_uclamp_util_min, false); update_root_tg = true; } if (old_max != sysctl_sched_uclamp_util_max) { uclamp_se_set(&uclamp_default[UCLAMP_MAX], sysctl_sched_uclamp_util_max, false); update_root_tg = true; }
//4.只要系统维度的uclamp发生变化,就执行下面操作 // 完成对group和task维度的uclamp进行更新 if (update_root_tg) { //4.1 在enqueue/dequeue时用于计算CPU的clamp值时进行判断 static_branch_enable(&sched_uclamp_used);
//4.2 设置到全局变量root_task_group uclamp_update_root_tg(); }
//5.如果修改的是sysctl_sched_uclamp_util_min_rt_default if (old_min_rt != sysctl_sched_uclamp_util_min_rt_default) { static_branch_enable(&sched_uclamp_used);
//5.1 设置到系统中所有rt线程的p->uclamp_req[UCLAMP_MIN] uclamp_sync_util_min_rt_default(); }
/* * We update all RUNNABLE tasks only when task groups are in use. * Otherwise, keep it simple and do just a lazy update at each next * task enqueue time. */
goto done;
undo: sysctl_sched_uclamp_util_min = old_min; sysctl_sched_uclamp_util_max = old_max; sysctl_sched_uclamp_util_min_rt_default = old_min_rt; done: mutex_unlock(&uclamp_mutex);
return result; } |
2.3 uclamp_update_root_tg - 设置根组的task_group->uclamp_req[]
|
static void uclamp_update_root_tg(void) { struct task_group *tg = &root_task_group;
//1.根组的uclamp信息和system维度的uclamp信息相等 uclamp_se_set(&tg->uclamp_req[UCLAMP_MIN], sysctl_sched_uclamp_util_min, false); uclamp_se_set(&tg->uclamp_req[UCLAMP_MAX], sysctl_sched_uclamp_util_max, false);
//2.一个group的uclamp信息发生了变化,需要完成下面三个工作 // a) 更新这个group下的子group的uclamp信息 // b) 更新这个group下的task的uclamp信息,包括子group中的task // c) 更新这些task所属的rq的uclamp信息,即rq->uclamp[clamp_id] rcu_read_lock(); cpu_util_update_eff(&root_task_group.css); rcu_read_unlock(); } |
三、cgroup维度的uclamp信息
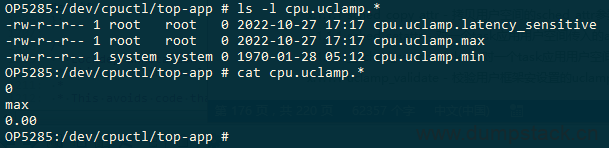
cgroup维度的uclamp信息可通过节点"/dev/cpuctl/<group>/cpu.uclamp.*"设置,取值范围0.00 - 100.00,格式为两位小数精度的百分比值。cgroup维度的uclamp有下面两个含义:
-
uclamp_min:
a) 所有子group的uclamp_min值,都不得大于这个父group的uclamp_min值
b) 这个group下的所有task的uclamp_min值,都都不得大于这个父group的uclamp_min值
-
uclamp_max:
a) 所有子group的uclamp_max值都不得大于这个父group的uclamp_max值
b) 这个group下的所有task的uclamp_max值,都都不得大于这个父group的uclamp_max值
注意:根组root不支持通过这里的节点进行配置,而是在system维度的uclamp配置的时候设置,详见sysctl_sched_uclamp_handler实现
3.1 数据结构
3.1.1 task_group中对uclamp的扩展
|
struct task_group { ... #ifdef CONFIG_UCLAMP_TASK_GROUP /* The two decimal precision [%] value requested from user-space */ //用户空间通过/dev/cpuctl/<group>/cpu.uclamp.[min|max]节点设置的值对应的百分比 unsigned int uclamp_pct[UCLAMP_CNT];
/* Clamp values requested for a task group */ //用户空间通过/dev/cpuctl/<group>/cpu.uclamp.[min|max]节点设置的值对应的util值 struct uclamp_se
/* Effective clamp values used for a task group */ //有效的uclamp值 struct uclamp_se
/* Latency-sensitive flag used for a task group */ //下面成员只在AOSP中有 unsigned int latency_sensitive; #endif
}; |
3.1.2 uclamp_request - 描述一个百分数
|
/* * Integer 10^N with a given N exponent by casting to integer the literal "1eN" * C expression. Since there is no way to convert a macro argument (N) into a * character constant, use two levels of macros. */ //上面的宏解释了为什么要使用两级宏,将宏的参数转化为字符常量 //POW10(N)表示10^N #define _POW10(exp) ((unsigned int)1e##exp) #define POW10(exp) _POW10(exp)
struct uclamp_request { //2表示两位小数 #define UCLAMP_PERCENT_SHIFT 2 #define UCLAMP_PERCENT_SCALE (100 * POW10(UCLAMP_PERCENT_SHIFT)) //用户空间的百分比,例如87.95%,该值就是8795 s64 percent;
//上面百分比对应的util值大小 u64 util; int ret; }; |
3.2 节点: /dev/cpuctl/top-app/cpu.uclamp.*
该值会限制group内所有task的uclamp值,cpu.uclamp.[min|max]取值范围0.00~100.00,格式为两位小数精度的百分比值,还可以直接向cpu.uclamp.max中echo max,表示直接将值设置为100.00,cpu.uclamp.latency_sensitive只能设置0或1
注意根目录/dev/cpuctl/下是没有uclamp相关文件的,也就是说根组的uclamp不是在这里控制的,实际上是放在system维度的profs文件接口给设置,详见sysctl_sched_uclamp_handler实现
|
更新task_group中的uclamp_req[]和uclamp_pct[] /dev/cpuctl/<group>/cpu.uclamp.min /dev/cpuctl/<group>/cpu.uclamp.max
更新task_group中的latency_sensitive /dev/cpuctl/<group>/cpu.uclamp.latency_sensitive |
文件位置:W:\opensource\linux-5.10.61\kernel\sched\core.c
|
static struct cftype cpu_legacy_files[] = { ... #ifdef CONFIG_UCLAMP_TASK_GROUP { .name = "uclamp.min", .flags = CFTYPE_NOT_ON_ROOT, .seq_show = cpu_uclamp_min_show, .write = cpu_uclamp_min_write, }, { .name = "uclamp.max", .flags = CFTYPE_NOT_ON_ROOT, .seq_show = cpu_uclamp_max_show, .write = cpu_uclamp_max_write, }, { .name = "uclamp.latency_sensitive", //只有AOSP中会存在该节点 .flags = CFTYPE_NOT_ON_ROOT, .read_u64 = cpu_uclamp_ls_read_u64, .write_u64 = cpu_uclamp_ls_write_u64, }, #endif ... }; |
3.2.1 cpu_uclamp_min_write - 设置cpu.uclamp.min
|
static ssize_t cpu_uclamp_min_write( struct kernfs_open_file *of, char *buf, size_t nbytes, loff_t off) { return cpu_uclamp_write(of, buf, nbytes, off, UCLAMP_MIN); } |
3.2.2 cpu_uclamp_max_write - 设置cpu.uclamp.max
|
static ssize_t cpu_uclamp_max_write( struct kernfs_open_file *of, char *buf, size_t nbytes, loff_t off) { return cpu_uclamp_write(of, buf, nbytes, off, UCLAMP_MAX); } |
3.2.3 cpu_uclamp_write
|
static ssize_t cpu_uclamp_write( struct kernfs_open_file *of, char *buf, size_t nbytes, loff_t off, enum uclamp_id clamp_id) //标记是写min还是max { struct uclamp_request req; struct task_group *tg;
//1.解析用户空间的输入 // 得到百分比,并计算得到对应的util值 req = capacity_from_percent(buf); if (req.ret) return req.ret;
//2.使能 static_branch_enable(&sched_uclamp_used);
mutex_lock(&uclamp_mutex); rcu_read_lock();
//3.得到是从哪个组的节点下写下来的 tg = css_tg(of_css(of));
//4.更新task_group->uclamp_req值,注意,这里传入的参数为false if (tg->uclamp_req[clamp_id].value != req.util) uclamp_se_set(&tg->uclamp_req[clamp_id], req.util, false);
/* * Because of not recoverable conversion rounding we keep track of the * exact requested value */ //5.更新task_group中记录的uclamp_pct值 tg->uclamp_pct[clamp_id] = req.percent;
/* Update effective clamps to track the most restrictive value */ //6.更新这个group的有效uclamp值 cpu_util_update_eff(of_css(of));
rcu_read_unlock(); mutex_unlock(&uclamp_mutex);
return nbytes; } |
3.2.3.1 capacity_from_percent - 解析用户空间的百分比,并计算得到对应的util值
|
static inline struct uclamp_request capacity_from_percent(char *buf) { //1.100%对应1024,下面的值也是用户空间输入"max"时对应的值 struct uclamp_request req = { .percent = UCLAMP_PERCENT_SCALE, //10000,表示100% .util = SCHED_CAPACITY_SCALE, //1024 .ret = 0, };
//2.去除前面的空格 buf = strim(buf);
//3.如果输入的不是字符串max,则进入该分支,解析用户空间输入的小数 if (strcmp(buf, "max")) { //4.将输入的字符串转化为整形值保存在percent里面 req.ret = cgroup_parse_float(buf, UCLAMP_PERCENT_SHIFT, &req.percent); if (req.ret) return req;
//5.对用户空间的输入的百分比进行有效性检查 if ((u64)req.percent > UCLAMP_PERCENT_SCALE) { req.ret = -ERANGE; return req; }
//6.这里计算得到百分比对应的util值,100%对应的是1024 // 这里的计算是真他娘的巧妙啊 req.util = req.percent << SCHED_CAPACITY_SHIFT; req.util = DIV_ROUND_CLOSEST_ULL(req.util, UCLAMP_PERCENT_SCALE); }
return req; } |
3.2.3.2 cgroup_parse_float - 将字符串转化为一个整数
在@input中解析一个小数浮点数,并将结果存储在@v中,小数点右移@dec_shift时间。例如,@input为"12.3456",@dec_shift为3,则*@v将被设置为12345
具体函数细节我们不分析了
|
/** * cgroup_parse_float - parse a floating number * @input: input string * @dec_shift: number of decimal digits to shift * @v: output * * Parse a decimal floating point number in @input and store the result in * @v with decimal point right shifted @dec_shift times. For example, if * @input is "12.3456" and @dec_shift is 3, *@v will be set to 12345. * Returns 0 on success, -errno otherwise. * * There's nothing cgroup specific about this function except that it's * currently the only user. */ int cgroup_parse_float( const char *input, //要解析的字符串 unsigned dec_shift, //小数点移位的个数 s64 *v) //解析后得到的浮点数 { s64 whole, frac = 0; int fstart = 0, fend = 0, flen;
if (!sscanf(input, "%lld.%n%lld%n", &whole, &fstart, &frac, &fend)) return -EINVAL; if (frac < 0) return -EINVAL;
flen = fend > fstart ? fend - fstart : 0; if (flen < dec_shift) frac *= power_of_ten(dec_shift - flen); else frac = DIV_ROUND_CLOSEST_ULL(frac, power_of_ten(flen - dec_shift));
*v = whole * power_of_ten(dec_shift) + frac; return 0; } |
3.2.4 cpu_uclamp_min_show - 显示cpu.uclamp.min
|
static int cpu_uclamp_min_show(struct seq_file *sf, void *v) { cpu_uclamp_print(sf, UCLAMP_MIN); return 0; } |
3.2.5 cpu_uclamp_max_show - 显示cpu.uclamp.max
|
static int cpu_uclamp_max_show(struct seq_file *sf, void *v) { cpu_uclamp_print(sf, UCLAMP_MAX); return 0; } |
3.2.6 cpu_uclamp_print
|
static inline void cpu_uclamp_print( struct seq_file *sf, enum uclamp_id clamp_id) //标记要显示min还是max { struct task_group *tg; u64 util_clamp; u64 percent; u32 rem;
rcu_read_lock(); //1.获取要读取哪个group中的节点 tg = css_tg(seq_css(sf));
//2.获取这个group中的值 util_clamp = tg->uclamp_req[clamp_id].value; rcu_read_unlock();
//3.如果uclamp达到最大值1024,直接显示max if (util_clamp == SCHED_CAPACITY_SCALE) { seq_puts(sf, "max\n"); return; }
//4.否则按照task_group中的百分比来计算返回的值 percent = tg->uclamp_pct[clamp_id]; percent = div_u64_rem(percent, POW10(UCLAMP_PERCENT_SHIFT), &rem); seq_printf(sf, "%llu.%0*u\n", percent, UCLAMP_PERCENT_SHIFT, rem); } |
3.2.7 cpu_uclamp_ls_write_u64 - 写task_group->latency_sensitive
task_group->latency_sensitive属性主要在下面两处应用:
位置1:在为cfs任务选核时,在find_energy_efficient_cpu中,若判断任务所在组设置了latency_sensitive属性,趋向于选择idle cpu,若是没有idle cpu可选,就选择空余算力最大的CPU;若是没有设置latency_sensitive属性,那就趋向于选择最节能的CPU。
位置2:MTK在find_energy_efficient_cpu中注册了hook,函数为mtk_find_energy_efficient_cpu若是hook中选到核了,位置1就不再生效了。此hook的逻辑为若是perf_ioctl没有设置uclamp_min_ls,那么latency_sensitive的取值和原生的一致,否则取值为 p->uclamp_req[UCLAMP_MIN].value > 0 ? 1 : 0,若是判断为 latency_sensitive 的,就优先选择idle 核,若没有 idle 核就依次选最空闲的具有最大算力的核和有最大空余算力的核,判读时考虑了从idle退出的延迟。
仅从cgroup上,目前有MTK只有神经网络相关的binder线程单独创建了一个group,设置了这个latency_sensitive属性。
|
static int cpu_uclamp_ls_write_u64( struct cgroup_subsys_state *css, struct cftype *cftype, u64 ls) { struct task_group *tg;
if (ls > 1) return -EINVAL;
//直接将用户空间的值写入task_group->latency_sensitive tg = css_tg(css); tg->latency_sensitive = (unsigned int) ls;
return 0; } |
3.2.8 cpu_uclamp_ls_read_u64 - 读task_group->latency_sensitive
|
static u64 cpu_uclamp_ls_read_u64( struct cgroup_subsys_state *css, struct cftype *cft) { struct task_group *tg = css_tg(css);
//读取task_group->latency_sensitive return (u64) tg->latency_sensitive; } |
3.3 示例
3.3.1 设置/dev/cpuctl/<group>/cpu.uclamp.min
|
#define SCHEDTUNE_TOPAPP_CPUCTL_BOOST_PATH "/dev/cpuctl/top-app/cpu.uclamp.min"
int DecisionDriver::setSchedtuneBoost(int index, int boost) { char path[64], buf[128];
if (index >= SCHEDTUNE_BG_MAX_INDEX) return -1;
if (isFileExist(SCHEDTUNE_TOPAPP_CPUCTL_BOOST_PATH)) { DEBUG("set cpuctl enter"); snprintf(path, sizeof(path), SCHEDTUNE_TOPAPP_CPUCTL_BOOST_PATH); } else if (index < 0) // FIXME: only support top_app boostgroup snprintf(path, sizeof(path), SCHEDTUNE_TOPAPP_BOOST_PATH); else snprintf(path, sizeof(path), "/dev/stune/fb%d/schedtune.boost", index);
if (mFpBoost == NULL) { mFpBoost = fopen(path, "w"); if (mFpBoost == NULL) { ERROR("fopen %s failed.(%s)", path, strerror(errno)); return -1; } }
if (fseek(mFpBoost, 0, SEEK_SET) < 0) { ERROR("fseek failed.(%s)\n", strerror(errno)); fclose(mFpBoost); mFpBoost = NULL; return -1; }
snprintf(buf, sizeof(buf), "%d", boost); if (fwrite(buf, sizeof(char), strlen(buf), mFpBoost) == 0) { ERROR("fwrite failed.(%s)\n", strerror(errno)); fclose(mFpBoost); mFpBoost = NULL; return -1; } fflush(mFpBoost);
DEBUG("set schedtune boost %d", boost);
return 0; } |
3.3.2 设置/dev/cpuctl/<group>/cpu.uclamp.latency_sensitive
|
static constexpr char* uclampLatencySensitivePath = \ "/dev/cpuctl/foreground/cpu.uclamp.latency_sensitive";
Return<void> OrmsHalService::ormsWriteUclampLatencySensitive(const hidl_string& stingValue) { int fd = open(uclampLatencySensitivePath, O_WRONLY); if (fd < 0) { ALOGE("open %s failed(%s)", uclampLatencySensitivePath, strerror(errno)); return Void(); } ALOGD("OrmsHalService write file %s - %s.", uclampLatencySensitivePath, stingValue.c_str());
ssize_t len = write(fd, stingValue.c_str(), stingValue.size()); if (len <= 0) { ALOGE("write file %s failed.(%s)", uclampLatencySensitivePath, strerror(errno)); } close(fd); return Void(); } |
3.4 更新指定group的有效uclamp信息
group层的uclamp(不管是uclamp_min还是uclamp_max)有下面两层含义:
-
所有子group的uclamp值,都不得大于这个父group的uclamp值
-
group下的所有task的uclamp值,都都不得大于这个父group的uclamp值
当一个group的uclamp信息发生了变化,需要完成下面三个工作
-
更新这个group下的子group的uclamp信息
-
更新这个group下的task的uclamp信息,包括子group中的task
-
更新这些task所属的rq的uclamp信息,即rq->uclamp[clamp_id]
3.4.1 cpu_util_update_eff - 更新指定group的uclamp
|
static void cpu_util_update_eff( struct cgroup_subsys_state *css) //要更新哪个group { struct cgroup_subsys_state *top_css = css; struct uclamp_se *uc_parent = NULL; struct uclamp_se *uc_se = NULL; unsigned int eff[UCLAMP_CNT]; enum uclamp_id clamp_id; unsigned int clamps;
lockdep_assert_held(&uclamp_mutex); SCHED_WARN_ON(!rcu_read_lock_held());
//遍历这个cgroup下的所有子group css_for_each_descendant_pre(css, top_css) {
//1.第一步:计算子group受父group钳位后的uclamp值 uc_parent = css_tg(css)->parent ? css_tg(css)->parent->uclamp : NULL;
//1.1 不管是uclamp_min还是uclamp_max,子group的 // 有效uclamp值一定小于父group的uclamp值,为啥捏??? for_each_clamp_id(clamp_id) { /* Assume effective clamps matches requested clamps */ eff[clamp_id] = css_tg(css)->uclamp_req[clamp_id].value;
/* Cap effective clamps with parent's effective clamps */ if (uc_parent && eff[clamp_id] > uc_parent[clamp_id].value) { eff[clamp_id] = uc_parent[clamp_id].value; } }
/* Ensure protection is always capped by limit */ //1.2 因为上面都是取最小值,所以有可能算出来的min要大于max,在这里做处理 eff[UCLAMP_MIN] = min(eff[UCLAMP_MIN], eff[UCLAMP_MAX]);
/* Propagate most restrictive effective clamps */ //1.3 将受父group钳位后的新的uclamp值更新进这个group->uclamp里面 // 相等则不用更新,不相等则更新 clamps = 0x0; uc_se = css_tg(css)->uclamp; for_each_clamp_id(clamp_id) { if (eff[clamp_id] == uc_se[clamp_id].value) continue;
uc_se[clamp_id].value = eff[clamp_id]; uc_se[clamp_id].bucket_id = uclamp_bucket_id(eff[clamp_id]); clamps |= (0x1 << clamp_id); } //1.4只有在这个group的uclamp_min和uclamp_max全都没用发生 // 变化时,才执行下面的操作,获取最左侧的cgroup,暂不分析 if (!clamps) { css = css_rightmost_descendant(css); continue; }
/* Immediately update descendants RUNNABLE tasks */ //2.第二步:遍历这个cgroup下的所有task,完成下面工作: // a) 更新task的有效uclamp信息,即task->uclamp[] // b) 更新这些task所属的rq的uclamp信息,即rq->uclamp[clamp_id] uclamp_update_active_tasks(css); } } |
3.4.2 uclamp_update_active_tasks - 更新指定group中的所有task的uclamp
|
static inline void uclamp_update_active_tasks( struct cgroup_subsys_state *css) { struct css_task_iter it; struct task_struct *p;
//遍历这个group中的所有task,挨个设置 css_task_iter_start(css, 0, &it); while ((p = css_task_iter_next(&it))) uclamp_update_active(p); css_task_iter_end(&it); } |
3.4.3 uclamp_update_active - 更新指定task的uclamp
|
static inline void uclamp_update_active(struct task_struct *p) { enum uclamp_id clamp_id; struct rq_flags rf; struct rq *rq;
/* * Lock the task and the rq where the task is (or was) queued. * * We might lock the (previous) rq of a !RUNNABLE task, but that's the * price to pay to safely serialize util_{min,max} updates with * enqueues, dequeues and migration operations. * This is the same locking schema used by __set_cpus_allowed_ptr(). */ rq = task_rq_lock(p, &rf);
/* * Setting the clamp bucket is serialized by task_rq_lock(). * If the task is not yet RUNNABLE and its task_struct is not * affecting a valid clamp bucket, the next time it's enqueued, * it will already see the updated clamp bucket value. */ //前面我们说过:group下的所有task的uclamp值,都不得大于这个父group的uclamp值 //这个group的uclamp信息已经被保存在task_group->uclamp结构中,下面依次执行 //uclamp_rq_dec_id和uclamp_rq_inc_id,在uclamp_rq_inc_id -> uclamp_eff_get中, //group的uclamp信息最终在uclamp_eff_value中被作用在task上
//如果这个task已经在rq链表上,则手动执行下面dec和inc操作,使uclamp信息立刻生效, //如果不在链表上(active为false),则不需要执行,更新工作留到这个task下一次enqueue时完成 for_each_clamp_id(clamp_id) { if (p->uclamp[clamp_id].active) { uclamp_rq_dec_id(rq, p, clamp_id); uclamp_rq_inc_id(rq, p, clamp_id); } }
task_rq_unlock(rq, p, &rf); } |
四、task维度的uclamp信息
task维度的uclamp信息通过sched_setattr系统调用设置下来,用于控制这个task的util值不会超过uclamp的范围,以满足自身的性能/功耗需求,取值范围0~SCHED_CAPACITY_SCALE。但是这个值会同时受system和cgroup两个维度的限制。
通过下面节点,可以查看线程的uclamp值和effective uclamp值
|
/proc/<pid>/task/<tid>/sched |
例如:

其中:
-
uclamp.[min|max]:取自p->uclamp_req[clamp_id].value,来源于用户空间的系统调用
-
effective uclamp.[min|max]:即这个task真正有效的uclamp值,是uclamp_eff_value返回的值,是上面p->uclamp_req[clamp_id].value受system和cgroup限制后的值
这几个节点实现如下:
文件位置:W:\opensource\linux-5.10.61\kernel\sched\debug.c
|
void proc_sched_show_task( struct task_struct *p, struct pid_namespace *ns, struct seq_file *m) { ... #ifdef CONFIG_UCLAMP_TASK __PS("uclamp.min", p->uclamp_req[UCLAMP_MIN].value); __PS("uclamp.max", p->uclamp_req[UCLAMP_MAX].value); __PS("effective uclamp.min", uclamp_eff_value(p, UCLAMP_MIN)); __PS("effective uclamp.max", uclamp_eff_value(p, UCLAMP_MAX)); #endif ... } |
4.1 数据结构
4.1.1 task_struct中对uclamp的支持
|
struct task_struct { ... #ifdef CONFIG_UCLAMP_TASK /* * Clamp values requested for a scheduling entity. * Must be updated with task_rq_lock() held. */ //用户空间请求的clamp值,通过sched_setattr系统调用设置 struct uclamp_se uclamp_req[UCLAMP_CNT];
/* * Effective clamp values used for a scheduling entity. * Must be updated with task_rq_lock() held. */ //这个task最终生效的uclamp信息,也就是是受system和cgroup两个 //维度共同钳制后的值,在enqueue的时候更新,详见uclamp_rq_inc_id struct uclamp_se uclamp[UCLAMP_CNT]; #endif ... } |
4.1.2 uclamp_se - 记录task的uclamp信息,每个se对应一个
每个task对应一个该结构
|
/* * Utilization clamp for a scheduling entity * @value: clamp value "assigned" to a se * @bucket_id: bucket index corresponding to the "assigned" value * @active: the se is currently refcounted in a rq's bucket * @user_defined: the requested clamp value comes from user-space * * The bucket_id is the index of the clamp bucket matching the clamp value * which is pre-computed and stored to avoid expensive integer divisions from * the fast path. * * The active bit is set whenever a task has got an "effective" value assigned, * which can be different from the clamp value "requested" from user-space. * This allows to know a task is refcounted in the rq's bucket corresponding * to the "effective" bucket_id. * * The user_defined bit is set whenever a task has got a task-specific clamp * value requested from userspace, i.e. the system defaults apply to this task * just as a restriction. This allows to relax default clamps when a less * restrictive task-specific value has been requested, thus allowing to * implement a "nice" semantic. For example, a task running with a 20% * default boost can still drop its own boosting to 0%. */ struct uclamp_se { //用来记录这个task的uclamp_[min|max]值,最大值为1024,占11个bit unsigned int value : bits_per(SCHED_CAPACITY_SCALE);
//标记这个task的uclamp_[min|max]值落在rq的bucket的那个桶里面 unsigned int bucket_id : bits_per(UCLAMP_BUCKETS);
//标记这个task对应的uclamp_se是否已经被规划进rq的bucket中 //enqueue此task时写1,dequeue此task时写0,线程刚fork的时候写0 unsigned int active : 1;
//标记这个task的clamp值是否是来源于用户空间的系统调用 //如果是来源于system和cgroup维度,设置为0 //如果是来源于用户空间的系统调用,设置为1 unsigned int user_defined : 1; }; |
4.1.3 uclamp_id - uclamp种类
其中uclamp_id如下
|
/* * Utilization clamp constraints. * @UCLAMP_MIN: Minimum utilization * @UCLAMP_MAX: Maximum utilization * @UCLAMP_CNT: Utilization clamp constraints count */ enum uclamp_id { UCLAMP_MIN = 0, UCLAMP_MAX, UCLAMP_CNT }; |
4.2 sched_setattr系统调用
4.2.1 函数原型
函数原型如下,该系统调用可用于设置指定task属于哪一个调度类、优先级是多少、以及uclamp信息
|
int sched_setattr(pid_t pid, struct sched_attr *attr, unsigned int flags); |
参数flags没啥用,参数sched_attr如下
|
/* * Extended scheduling parameters data structure. * * This is needed because the original struct sched_param can not be * altered without introducing ABI issues with legacy applications * (e.g., in sched_getparam()). * * However, the possibility of specifying more than just a priority for * the tasks may be useful for a wide variety of application fields, e.g., * multimedia, streaming, automation and control, and many others. * * This variant (sched_attr) allows to define additional attributes to * improve the scheduler knowledge about task requirements. * * Scheduling Class Attributes * =========================== * * A subset of sched_attr attributes specifies the * scheduling policy and relative POSIX attributes: * * @size size of the structure, for fwd/bwd compat. * * @sched_policy task's scheduling policy * @sched_nice task's nice value (SCHED_NORMAL/BATCH) * @sched_priority task's static priority (SCHED_FIFO/RR) * * Certain more advanced scheduling features can be controlled by a * predefined set of flags via the attribute: * * @sched_flags for customizing the scheduler behaviour * * Sporadic Time-Constrained Task Attributes * ========================================= * * A subset of sched_attr attributes allows to describe a so-called * sporadic time-constrained task. * * In such a model a task is specified by: * - the activation period or minimum instance inter-arrival time; * - the maximum (or average, depending on the actual scheduling * discipline) computation time of all instances, a.k.a. runtime; * - the deadline (relative to the actual activation time) of each * instance. * Very briefly, a periodic (sporadic) task asks for the execution of * some specific computation --which is typically called an instance-- * (at most) every period. Moreover, each instance typically lasts no more * than the runtime and must be completed by time instant t equal to * the instance activation time + the deadline. * * This is reflected by the following fields of the sched_attr structure: * * @sched_deadline representative of the task's deadline * @sched_runtime representative of the task's runtime * @sched_period representative of the task's period * * Given this task model, there are a multiplicity of scheduling algorithms * and policies, that can be used to ensure all the tasks will make their * timing constraints. * * As of now, the SCHED_DEADLINE policy (sched_dl scheduling class) is the * only user of this new interface. More information about the algorithm * available in the scheduling class file or in Documentation/. * * Task Utilization Attributes * =========================== * * A subset of sched_attr attributes allows to specify the utilization * expected for a task. These attributes allow to inform the scheduler about * the utilization boundaries within which it should schedule the task. These * boundaries are valuable hints to support scheduler decisions on both task * placement and frequency selection. * * @sched_util_min represents the minimum utilization * @sched_util_max represents the maximum utilization * * Utilization is a value in the range [0..SCHED_CAPACITY_SCALE]. It * represents the percentage of CPU time used by a task when running at the * maximum frequency on the highest capacity CPU of the system. For example, a * 20% utilization task is a task running for 2ms every 10ms at maximum * frequency. * * A task with a min utilization value bigger than 0 is more likely scheduled * on a CPU with a capacity big enough to fit the specified value. * A task with a max utilization value smaller than 1024 is more likely * scheduled on a CPU with no more capacity than the specified value. */ struct sched_attr { //该数据结构的大小 __u32 size;
//指定调度策略,可取值为: //#define SCHED_NORMAL 0 //#define SCHED_FIFO 1 //#define SCHED_RR 2 //#define SCHED_BATCH 3 //#define SCHED_IDLE 5 //#define SCHED_DEADLINE 6 __u32 sched_policy;
//给调度器使用的一些flag,可取值如下 //#define SCHED_FLAG_RESET_ON_FORK 0x01 //#define SCHED_FLAG_RECLAIM 0x02 //#define SCHED_FLAG_DL_OVERRUN 0x04 //#define SCHED_FLAG_KEEP_POLICY 0x08 //#define SCHED_FLAG_KEEP_PARAMS 0x10 //#define SCHED_FLAG_UTIL_CLAMP_MIN 0x20 //#define SCHED_FLAG_UTIL_CLAMP_MAX 0x40 __u64 sched_flags;
/* SCHED_NORMAL, SCHED_BATCH */ __s32 sched_nice; //指定nice值
/* SCHED_FIFO, SCHED_RR */ __u32 sched_priority; //指定优先级
/* SCHED_DEADLINE */ __u64 sched_runtime; __u64 sched_deadline; __u64 sched_period;
/* Utilization hints */ __u32 sched_util_min; //uclamp相关 __u32 sched_util_max;
}; |
4.2.2 sched_setattr系统调用实现
4.2.2.1 sys_sched_setattr - sched_setattr系统调用实现
该系统调用在内核中的响应函数如下,目前flags暂时还没有使用
|
/** * sys_sched_setattr - same as above, but with extended sched_attr * @pid: the pid in question. * @uattr: structure containing the extended parameters. * @flags: for future extension. */ SYSCALL_DEFINE3(sched_setattr, pid_t, pid, struct sched_attr __user *, uattr, unsigned int, flags) { struct sched_attr attr; struct task_struct *p; int retval;
//1.参数有效性判断 if (!uattr || pid < 0 || flags) return -EINVAL;
//2.获取用户空间的attr数据 retval = sched_copy_attr(uattr, &attr); if (retval) return retval;
//3.参数有效性判断:调度策略 if ((int)attr.sched_policy < 0) return -EINVAL;
//4.sched_flags参数处理 if (attr.sched_flags & SCHED_FLAG_KEEP_POLICY) attr.sched_policy = SETPARAM_POLICY;
//6.由pid找到对应的task结构 rcu_read_lock(); retval = -ESRCH; p = find_process_by_pid(pid); if (likely(p)) get_task_struct(p); rcu_read_unlock();
//7.设置用户空间的attr if (likely(p)) { retval = sched_setattr(p, &attr); put_task_struct(p); }
return retval; } |
4.2.2.2 sched_copy_attr - 拷贝用户空间的sched_attr参数
|
/* * Mimics kernel/events/core.c perf_copy_attr(). */ static int sched_copy_attr(struct sched_attr __user *uattr, struct sched_attr *attr) { u32 size; int ret;
/* Zero the full structure, so that a short copy will be nice: */ memset(attr, 0, sizeof(*attr));
//1.先从用户空间的uattr中拷贝出size信息 ret = get_user(size, &uattr->size); if (ret) return ret;
/* ABI compatibility quirk: */ //2.校验size if (!size) size = SCHED_ATTR_SIZE_VER0; if (size < SCHED_ATTR_SIZE_VER0 || size > PAGE_SIZE) goto err_size;
//3.拷贝用户空间的attr信息 ret = copy_struct_from_user(attr, sizeof(*attr), uattr, size); if (ret) { if (ret == -E2BIG) goto err_size; return ret; }
//4.参数校验,当支持SCHED_FLAG_UTIL_CLAMP时,这个数据结构的大小必定为56 if ((attr->sched_flags & SCHED_FLAG_UTIL_CLAMP) && size < SCHED_ATTR_SIZE_VER1) return -EINVAL;
/* * XXX: Do we want to be lenient like existing syscalls; or do we want * to be strict and return an error on out-of-bounds values? */ //5.nice值的范围为[-20, 19] attr->sched_nice = clamp(attr->sched_nice, MIN_NICE, MAX_NICE);
return 0;
err_size: put_user(sizeof(*attr), &uattr->size); return -E2BIG; } |
attr数据结构有下面两种大小
|
#define SCHED_ATTR_SIZE_VER0 48 /* sizeof first published struct */ #define SCHED_ATTR_SIZE_VER1 56 /* add: util_{min,max} */ |
4.2.2.3 sched_setattr - 对指定的task,使能用户空间传入的attr
|
int sched_setattr(struct task_struct *p, const struct sched_attr *attr) { return __sched_setscheduler(p, attr, true, true); } |
4.2.2.4 __sched_setscheduler - 对指定的task,使能用户空间传入的attr
__sched_setscheduler这个函数太大了,我们这里只关注和uclamp相关的操作
|
static int __sched_setscheduler(struct task_struct *p, const struct sched_attr *attr, bool user, bool pi) { ... /* Update task specific "requested" clamps */ //1.参数有效性判断 if (attr->sched_flags & SCHED_FLAG_UTIL_CLAMP) { retval = uclamp_validate(p, attr); if (retval) return retval; } ...
/* * If not changing anything there's no need to proceed further, * but store a possible modification of reset_on_fork. */ //2.下面几种情况会跳转到change标签,才会执行到__setscheduler_uclamp if (unlikely(policy == p->policy)) { //2.1 cfs线程修改了优先级 if (fair_policy(policy) && attr->sched_nice != task_nice(p)) goto change;
//2.2 rt线程修改了优先级 if (rt_policy(policy) && attr->sched_priority != p->rt_priority) goto change;
//2.3 dl类线程修改了参数 if (dl_policy(policy) && dl_param_changed(p, attr)) goto change;
//2.4 线程修改了uclamp信息 if (attr->sched_flags & SCHED_FLAG_UTIL_CLAMP) goto change;
p->sched_reset_on_fork = reset_on_fork; retval = 0; goto unlock; }
change: ...
//3.设置uclamp值生效 __setscheduler_uclamp(p, attr);
unlock: ... } |
4.2.2.5 uclamp_validate - 校验用户空间设置的uclamp值的有效性
|
static int uclamp_validate( struct task_struct *p, const struct sched_attr *attr) { //1.先读取这个task的旧的uclamp值 unsigned int lower_bound = p->uclamp_req[UCLAMP_MIN].value; unsigned int upper_bound = p->uclamp_req[UCLAMP_MAX].value;
//2.从用户空间获取新的值 if (attr->sched_flags & SCHED_FLAG_UTIL_CLAMP_MIN) lower_bound = attr->sched_util_min; if (attr->sched_flags & SCHED_FLAG_UTIL_CLAMP_MAX) upper_bound = attr->sched_util_max;
//3.有效性判断 if (lower_bound > upper_bound) return -EINVAL; if (upper_bound > SCHED_CAPACITY_SCALE) return -EINVAL;
/* * We have valid uclamp attributes; make sure uclamp is enabled. * * We need to do that here, because enabling static branches is a * blocking operation which obviously cannot be done while holding * scheduler locks. */ static_branch_enable(&sched_uclamp_used);
return 0; } |
4.2.2.6 __setscheduler_uclamp - 系统调用设置的值记录在task->uclamp_req中
注意:代码走到这里表示这个task的调度类或者uclamp发生了变化
|
static void __setscheduler_uclamp( struct task_struct *p, const struct sched_attr *attr) { enum uclamp_id clamp_id;
/* * On scheduling class change, reset to default clamps for tasks * without a task-specific value. */ //1.先恢复默认的uclamp信息 // 如果这个task的uclamp信息是用户空间通过系统调用主动设置下来的, // 则保留,毕竟只有用户自己最了解自己的程序。否则,我们在这里将这个 // task的uclamp信息恢复成默认值,即uclamp_min为0,uclamp_max为1024 for_each_clamp_id(clamp_id) { struct uclamp_se *uc_se = &p->uclamp_req[clamp_id];
/* Keep using defined clamps across class changes */ //1.1 如果这个task的uclamp值是用户通过系统调用主动设置下来的,则保留 if (uc_se->user_defined) continue;
/* * RT by default have a 100% boost value that could be modified * at runtime. */ //1.2 rt和cfs线程的默认uclamp值是不同的 if (unlikely(rt_task(p) && clamp_id == UCLAMP_MIN)) //1.2.1 rt线程的UCLAMP_MIN值需要拉满 // 这个是为了rt运行时能够获得更高的性能 __uclamp_update_util_min_rt_default(p); else { //1.2.2 对于普通的cft线程和rt的UCLAMP_MAX,通过uclamp_none设置默认值 // uclamp_none表示没有钳位时的uclamp值,此时mix为0,max为1024 uclamp_se_set(uc_se, uclamp_none(clamp_id), false); } }
//2.如果没有设置该标记位,则表示用户空间并没有通过sched_setattr系统调用 // 设置task的uclamp值,也就不需要执行下面的逻辑了,则直接退出 if (likely(!(attr->sched_flags & SCHED_FLAG_UTIL_CLAMP))) return;
//3.下面根据用户空间指定的flag,设置线程的uclamp_req值 // 注意: // a) 这里并不是更新task的有效uclamp,而是task->uclamp_req // 这个task的有效uclamp在enqueue的时候更新,详见uclamp_rq_inc_id // b) 这里在调用函数时,传入的user_defined参数为true, // 表示这个uclamp是来源于用户空间的系统调用 if (attr->sched_flags & SCHED_FLAG_UTIL_CLAMP_MIN) { uclamp_se_set(&p->uclamp_req[UCLAMP_MIN], attr->sched_util_min, true); }
if (attr->sched_flags & SCHED_FLAG_UTIL_CLAMP_MAX) { uclamp_se_set(&p->uclamp_req[UCLAMP_MAX], attr->sched_util_max, true); } } |
其中
|
#define SCHED_FLAG_UTIL_CLAMP \ (SCHED_FLAG_UTIL_CLAMP_MIN | SCHED_FLAG_UTIL_CLAMP_MAX) |
4.2.2.7 for_each_clamp_id - 遍历每一个类型的uclamp
|
#define for_each_clamp_id(clamp_id) \ for ((clamp_id) = 0; (clamp_id) < UCLAMP_CNT; (clamp_id)++) |
4.2.2.8 uclamp_se_set - 设置uclamp值
|
static inline void uclamp_se_set( struct uclamp_se *uc_se, unsigned int value, //要设置的uclamp值,实际就是util值 bool user_defined) //标记这个值是都是来源于用户空间的系统调用 { //1.uclamp值 uc_se->value = value;
//2.得到对应的桶编号 uc_se->bucket_id = uclamp_bucket_id(value);
//3.标记这个uclamp值是否来源于用户空间,只有task维度 // 的uclamp信息才是通过用户空间系统调用设置下来的 uc_se->user_defined = user_defined; } |
4.2.3 示例
下面举个设置uclamp信息的例子:
|
#define SCHED_FLAG_UTIL_CLAMP \ (SCHED_FLAG_UTIL_CLAMP_MIN | SCHED_FLAG_UTIL_CLAMP_MAX)
status_t SurfaceFlinger::setSchedAttr(bool enabled) { static const unsigned int kUclampMin = base::GetUintProperty<unsigned int>("ro.surface_flinger.uclamp.min", 0U);
//1.uclamp.min set to 0 (default), skip setting if (!kUclampMin) return NO_ERROR;
//2.Currently, there is no wrapper in bionic: b/183240349. struct sched_attr { uint32_t size; uint32_t sched_policy; uint64_t sched_flags; int32_t sched_nice; uint32_t sched_priority; uint64_t sched_runtime; uint64_t sched_deadline; uint64_t sched_period; uint32_t sched_util_min; uint32_t sched_util_max; };
//3.参数初始化,设置task的min和max sched_attr attr = {}; attr.size = sizeof(attr);
attr.sched_flags = (SCHED_FLAG_KEEP_ALL | SCHED_FLAG_UTIL_CLAMP); attr.sched_util_min = enabled ? kUclampMin : 0; attr.sched_util_max = 1024;
//4.执行系统调用 if (syscall(__NR_sched_setattr, 0, &attr, 0)) return -errno;
return NO_ERROR; } |
4.3 计算task的util值
4.3.1 uclamp_task_util - 计算task的util
task的util值,不能超过其uclamp范围
|
static inline unsigned long uclamp_task_util(struct task_struct *p) { return clamp(task_util_est(p), uclamp_eff_value(p, UCLAMP_MIN), uclamp_eff_value(p, UCLAMP_MAX)); } |
4.3.2 uclamp_eff_value - 获取task的有效uclamp值,也就是受system和group共同钳制后的值
|
unsigned long uclamp_eff_value(struct task_struct *p, enum uclamp_id clamp_id) { struct uclamp_se uc_eff;
/* Task currently refcounted: use back-annotated (effective) value */ //1.这个task的有效uclamp信息记录在task->uclamp中,在task执行enqueue // 的时候更新,如果这个task已经被添加进rq的某个桶中(这个task已经在rq上, // 已经执行过enqueue操作),那么task->uclamp中记录的就是有效的uclamp信 // 息,否则就需要通过下面的uclamp_eff_get重新计算 if (p->uclamp[clamp_id].active) return (unsigned long)p->uclamp[clamp_id].value;
//2.代码走到这里,表示这个task并没有加到这个rq上,也就是说不是处于RUNNABLE // 状态,此时这个task的有效uclamp可能很久没有更新了,调用下面函数获取当前这 // 个task的有效uclamp值 uc_eff = uclamp_eff_get(p, clamp_id);
return (unsigned long)uc_eff.value; } |
4.3.3 uclamp_eff_get - 计算task的有效uclamp值,也就是受system和group共同限制后的值
所谓这个task的有效uclamp值,就是这个task的uclamp受system和group两个维度共同钳制后的uclamp值。由下面函数最前面的注释可知,task最终有效的uclamp最终有下面几个维度共同决定,按优先级从低到高依次为:
-
用户空间通过系统调用的方式为这个task设置下来的uclamp值
-
这个task所属group的uclamp值,(对于在根组或autogroup中的task不受影响)
-
system维度的uclamp值
system和cgroup维度的uclamp对task的uclamp的影响如下:
-
system维度:任何task的uclamp值,不管是uclamp_min还是uclamp_max,都不得大于system维度指定的uclamp值(实现参见uclamp_eff_get)。system维度的uclamp值可通过procfs中的节点设置
-
cgroup维度:任何task的uclamp值,不管是uclamp_min还是uclamp_max,都必须落在所属group指定的uclamp_min ~ uclamp_max之间(这个和system有差异,task的uclamp必须小于system维度的uclamp_min,具体实现参见uclamp_tg_restrict),group维度的uclamp信息可通过cgroup中的节点设置
|
/* * The effective clamp bucket index of a task depends on, by increasing * priority: * - the task specific clamp value, when explicitly requested from userspace * - the task group effective clamp value, for tasks not either in the root * group or in an autogroup * - the system default clamp value, defined by the sysadmin */ static inline struct uclamp_se uclamp_eff_get( struct task_struct *p, enum uclamp_id clamp_id) { //1.返回task的uclamp受group的uclamp钳位后的值 struct uclamp_se uc_req = uclamp_tg_restrict(p, clamp_id);
//2.获取system维度的uclamp信息,记录在全局变量uclamp_default[]中 // 该全局变量可通过/proc/sys/kernel/sched_util_clamp_[min|max]设置的 struct uclamp_se uc_max = uclamp_default[clamp_id];
/* System default restrictions always apply */ //3.注意: // 在计算受system维度的钳位值时,不管是uclamp_min还是uclamp_max, // 均取最小值,也就是说系统中任何task的uclamp值,不管是uclamp_min // 还是uclamp_max,都不会超过system维度的uclamp_min和uclamp_max的值 if (unlikely(uc_req.value > uc_max.value)) return uc_max;
return uc_req; } |
4.3.4 uclamp_tg_restrict - 返回task的uclamp受group钳位后的值
task的uclamp信息,不能超过这个task所属的group的uclamp范围,注意和system维度的区分。
|
static inline struct uclamp_se uclamp_tg_restrict( struct task_struct *p, enum uclamp_id clamp_id) { /* Copy by value as we could modify it */ //1.先获取task的uclamp_req值,uclamp_req来源于用户空间的系统调用,不是最终有效的uclamp struct uclamp_se uc_req = p->uclamp_req[clamp_id];
#ifdef CONFIG_UCLAMP_TASK_GROUP unsigned int tg_min, tg_max, value;
/* * Tasks in autogroups or root task group will be * restricted by system defaults. */ //2.由上面的注释可知,如果这个task位于autogroup或者在根组, // 则这个task的uclamp值只受system层约束,因此就直接返回 // autogroup表示根据线程的特性,决定将task放到哪个group中 if (task_group_is_autogroup(task_group(p))) return uc_req; if (task_group(p) == &root_task_group) return uc_req;
//3.获取这个task所在group的钳位值 tg_min = task_group(p)->uclamp[UCLAMP_MIN].value; tg_max = task_group(p)->uclamp[UCLAMP_MAX].value;
//4.干他 // 一个task的uclamp值(不管是min还是max),都不能超出其所在group限定的uclamp范围 value = uc_req.value; value = clamp(value, tg_min, tg_max);
//5.返回的这个uclamp是搜task和group维度共同影响的uclamp // 注意:此时只是记录在局部变量中,还没有设置进task的uclamp里面 uclamp_se_set(&uc_req, value, false); #endif
return uc_req; } |
4.4 rt线程的uclamp信息
4.4.1 uclamp_sync_util_min_rt_default - 对系统中的每一个rt线程设置uclamp
|
static void uclamp_sync_util_min_rt_default(void) { struct task_struct *g, *p;
/* * copy_process() sysctl_uclamp * uclamp_min_rt = X; * write_lock(&tasklist_lock) read_lock(&tasklist_lock) * // link thread smp_mb__after_spinlock() * write_unlock(&tasklist_lock) read_unlock(&tasklist_lock); * sched_post_fork() for_each_process_thread() * __uclamp_sync_rt() __uclamp_sync_rt() * * Ensures that either sched_post_fork() will observe the new * uclamp_min_rt or for_each_process_thread() will observe the new * task. */ read_lock(&tasklist_lock); smp_mb__after_spinlock(); read_unlock(&tasklist_lock);
//遍历系统中的每一个进程的每一个线程 rcu_read_lock(); for_each_process_thread(g, p) uclamp_update_util_min_rt_default(p); rcu_read_unlock(); } |
4.4.1.1 for_each_process_thread - 遍历系统中每一个进程下的每一个线程
系统中所有的进程都组织在全局链表init_task的tasks链表下面,每个进程的线程组织在每个进程task_sturct->signal的链表下,如下图所示
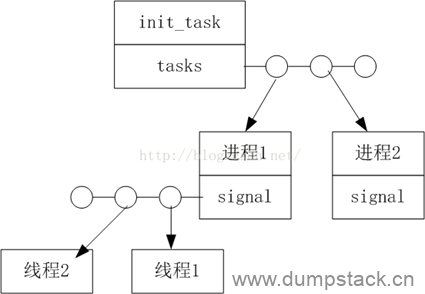
|
/* Careful: this is a double loop, 'break' won't work as expected. */ #define for_each_process_thread(p, t) \ for_each_process(p) for_each_thread(p, t) |
4.4.2 uclamp_update_util_min_rt_default - 对指定的rt线程设置
|
static void uclamp_update_util_min_rt_default(struct task_struct *p) { struct rq_flags rf; struct rq *rq;
//1.只设置rt线程,不是rt直接返回 if (!rt_task(p)) return;
/* Protect updates to p->uclamp_* */ rq = task_rq_lock(p, &rf); __uclamp_update_util_min_rt_default(p); task_rq_unlock(rq, p, &rf); } |
4.4.3 __uclamp_update_util_min_rt_default - 设置rt线程的uclamp_min值
|
static void __uclamp_update_util_min_rt_default(struct task_struct *p) { unsigned int default_util_min; struct uclamp_se *uc_se;
lockdep_assert_held(&p->pi_lock);
//1.注意: // 设置的是uclamp_req,不是有效的uclamp,有效uclamp在enqueue的时候更新 uc_se = &p->uclamp_req[UCLAMP_MIN];
/* Only sync if user didn't override the default */ //2.如果这个rt线程的uclamp值是用户通过系统调用设置下来的,则跳过 // 注意:用户空间系统调用设置下来的比system维度的权限更高 if (uc_se->user_defined) return;
//3.否则将rt线程的uclamp_min值拉倒最大,下面这个全局变量也是都用户 // 空间控制的,表示系统中所有的rt线程的uclamp_min的值应该设置多大, // 默认是1024 // 之所以要将rt线程uclamp_min拉倒最大值1024,主要是处于对性能的 // 考虑,高的util是可以将频率拉满,并且选核时可能上大核 default_util_min = sysctl_sched_uclamp_util_min_rt_default; uclamp_se_set(uc_se, default_util_min, false); } |
五、cpu维度的uclamp信息
5.1 桶算法简介
对于一个cpu来说,其运行队列rq上可能存多个task(处于running/runnable状态),那么如何计算cpu的util_min和util_max则非常关键,uclmap使用桶化算法实现这种计算。先看下面原理图:
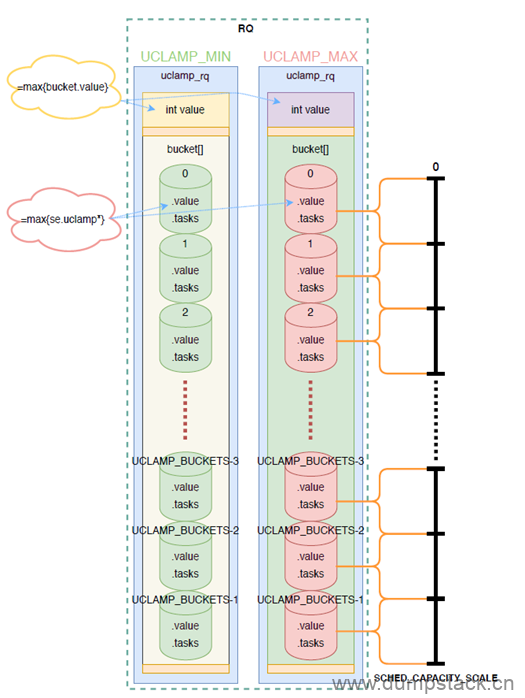
如上图所示,桶算法管理uclamp有下面特点:
在rq中通过嵌入两组uclamp_rq实现对cpu的util进行clamp(一组表示uclamp_min,另一组表示uclamp_max)。每组uclamp_rq中的value表示rq当前生效的clamp值,取值范围[0, SCHED_CAPACITY_SCALE],每组uclamp_rq默认划分为20个buckets,bucket的个数可以通过CONFIG_UCLAMP_BUCKETS_COUNT配置
每个bucket表示一定范围的util值,以系统默认的5个buckets为例,每个bucket的范围是cpu最大capacity的20%(SCHED_CAPACITY_SCALE/UCLAMP_BUCKETS_COUNT,即1024/5)
多个任务位于同一个桶内,桶的值按最大值聚合原则,即不管是UCLAMP_MIN还是UCLAMP_MAX桶,都取这个桶内所有task的uclamp的最大值作为桶的value值。桶与桶之间同样按最大值聚合原则,即cpu的uclamp值由value值最大的桶决定。这样可以保证高性能任务其性能需求始终能够得到满足,也就是说不会因为某些任务的uclamp值很低,导致cpu的uclamp值很低,也就不会造成性能问题了。但是这个最大聚合的原则导致uclamp小的task将受益于桶内uclamp大的task,这可能会引入功耗问题。
rq上的task会根据他的ucalmp值将其规划到对应的bucket中。比如taskA在cpu0上运行,要求25%的util值,会被规划到bucket[1]中,则bucket[1]::value=25%,tasks计数加1,表示规划到当前bucket中task又多了一个。如果同时要求35% util值的taskB被调度到cpu0上,则此时bucket[1]::value=35%,tasks计数加1。此时taskA将受益于taskB 35%的util值,直到taskA退出rq,需要注意的是,即使taskB先退出,taskA仍将继续受益于曾经taskB的高uclamp,被继续boost,详见后面对uclamp_rq_dec_id的分析。
如果系统对taskA受益taskB更高的boot util不能接受(10%),比如对功耗和续航带来恶化,可以增加bucket数量,这样就减少了每个bucket对应的util范围,提高了bucket util的统计精度,代价是使用更多的memory分配buckets。当bucket中没有task时,value被设置成默认的bucket范围的最小值,bucket[1]中没有task时,bucket[1]::value=%20。
可通过uclamp_bucket_id函数,计算指定clamp值对应的桶编号
|
static inline unsigned int uclamp_bucket_id(unsigned int clamp_value) { //默认分20个桶,将1024均分到[0, 19],两个宏分别为 51, 20 return min_t(unsigned int, clamp_value / UCLAMP_BUCKET_DELTA, UCLAMP_BUCKETS - 1); } |
其中UCLAMP_BUCKET_DELTA实现如下,表示每个桶中的util值的增量是多少,该值为51,另一方面也表示每个桶中uclamp的增量为cpu算力的100/20=5%
|
/* Integer rounded range for each bucket */ #define UCLAMP_BUCKET_DELTA DIV_ROUND_CLOSEST(SCHED_CAPACITY_SCALE, UCLAMP_BUCKETS) |
UCLAMP_BUCKETS在menuconfig中配置,默认为20,即默认20个桶
|
/* Number of utilization clamp buckets (shorter alias) */ #define UCLAMP_BUCKETS CONFIG_UCLAMP_BUCKETS_COUNT |
关于桶算法的引入,参见下面patch
https://lore.kernel.org/lkml/20190402104153.25404-2-patrick.bellasi@arm.com/
|
Utilization clamping allows to clamp the CPU's utilization within a [util_min, util_max] range, depending on the set of RUNNABLE tasks on that CPU. Each task references two "clamp buckets" defining its minimum and maximum (util_{min,max}) utilization "clamp values". A CPU's clamp bucket is active if there is at least one RUNNABLE tasks enqueued on that CPU and refcounting that bucket.
When a task is {en,de}queued {on,from} a rq, the set of active clamp buckets on that CPU can change. If the set of active clamp buckets changes for a CPU a new "aggregated" clamp value is computed for that CPU. This is because each clamp bucket enforces a different utilization clamp value.
Clamp values are always MAX aggregated for both util_min and util_max. This ensures that no task can affect the performance of other co-scheduled tasks which are more boosted (i.e. with higher util_min clamp) or less capped (i.e. with higher util_max clamp).
A tasks has: task_struct::uclamp[clamp_id]::bucket_id to track the "bucket index" of the CPU's clamp bucket it refcounts while enqueued, for each clamp index (clamp_id).
A runqueue has: rq::uclamp[clamp_id]::bucket[bucket_id].tasks to track how many RUNNABLE tasks on that CPU refcount each clamp bucket (bucket_id) of a clamp index (clamp_id). It also has a: rq::uclamp[clamp_id]::bucket[bucket_id].value to track the clamp value of each clamp bucket (bucket_id) of a clamp index (clamp_id).
The rq::uclamp::bucket[clamp_id][] array is scanned every time it's needed to find a new MAX aggregated clamp value for a clamp_id. This operation is required only when it's dequeued the last task of a clamp bucket tracking the current MAX aggregated clamp value. In this case, the CPU is either entering IDLE or going to schedule a less boosted or more clamped task. The expected number of different clamp values configured at build time is small enough to fit the full unordered array into a single cache line, for configurations of up to 7 buckets.
Add to struct rq the basic data structures required to refcount the number of RUNNABLE tasks for each clamp bucket. Add also the max aggregation required to update the rq's clamp value at each enqueue/dequeue event.
Use a simple linear mapping of clamp values into clamp buckets. Pre-compute and cache bucket_id to avoid integer divisions at enqueue/dequeue time. |
5.2 数据结构
5.2.1 rq中对uclamp的扩展
|
struct rq { ... #ifdef CONFIG_UCLAMP_TASK /* Utilization clamp values based on CPU's RUNNABLE tasks */ //两组uclamp,分别对应min和max struct uclamp_rq
//目前只有UCLAMP_FLAG_IDLE这一个标记,用于标记当前cpu是不是idle状态 unsigned int uclamp_flags; #define UCLAMP_FLAG_IDLE 0x01 #endif ... }; |
5.2.2 uclamp_rq - 记录cpu的uclamp值,每个rq对应一个
cpu的uclamp,不管是uclamp_min还是uclamp_max,都是取最大值,详见uclamp_rq_inc_id实现。
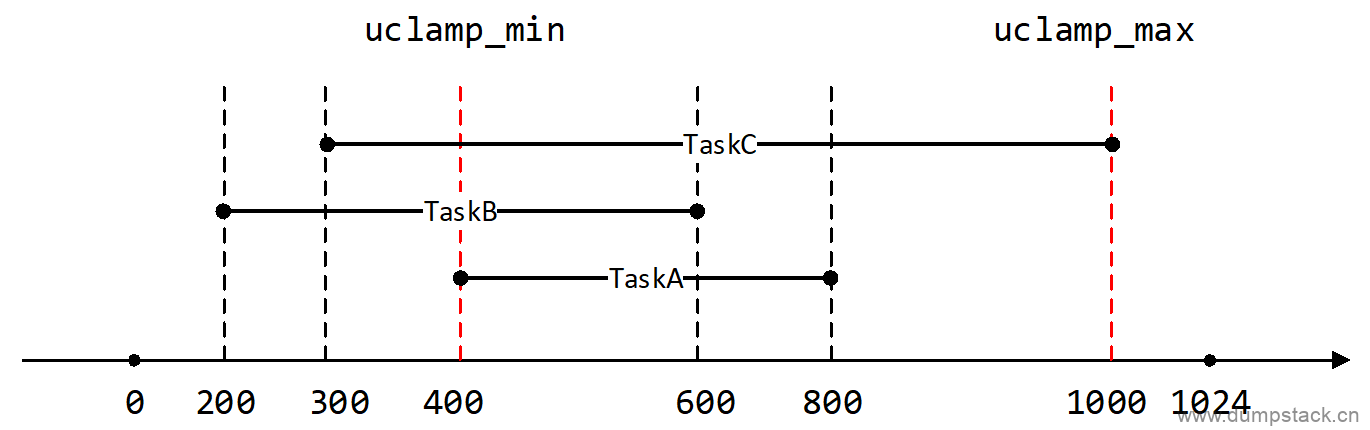
这个cpu的uclamp_min,是这个cpu上所有runnable状态的task中uclamp_min的最大值。如果不是最大值的话,则在计算cpu的util时,则很可能出现cpu的util值比某个task的uclamp_min的值还要小,那么拿这个值去调频的话,必然会造成这个task性能不足。下面举个栗子,下图各个task的uclamp范围依次为:TaskA[400, 800], TaskB[200, 600], TaskC[300, 1000],则这个cpu的uclamp_min为400而不是200。那么我们假设这个cpu的uclamp_min为200会发生什么呢?在计算cpu的util时可能为250,这个值显然是小于TaskA和TaskC的util值的,那么用这个值去调频的话,可能会造成TaskA和TaskC的性能不足
这个cpu的uclamp_max,是这个cpu上所有runnable状态的task中uclamp_max的最大值。同样是下面这个例子,这个cpu的uclamp_max值应该是1000而不是600。我们同样假设是600看看会出现什么问题,cpu在调频的时候计算出来的cpu的util值不能超过600,导致频率拉不起来,TaskA和TaskC的性能得不到满足。
数据结构定义如下:
|
/* * struct uclamp_rq - rq's utilization clamp * @value: currently active clamp values for a rq * @bucket: utilization clamp buckets affecting a rq * * Keep track of RUNNABLE tasks on a rq to aggregate their clamp values. * A clamp value is affecting a rq when there is at least one task RUNNABLE * (or actually running) with that value. * * There are up to UCLAMP_CNT possible different clamp values, currently there * are only two: minimum utilization and maximum utilization. *
* - for util_min: we want to run the CPU at least at the max of the minimum * utilization required by its currently RUNNABLE tasks. * - for util_max: we want to allow the CPU to run up to the max of the * maximum utilization allowed by its currently RUNNABLE tasks. * * Since on each system we expect only a limited number of different * utilization clamp values (UCLAMP_BUCKETS), use a simple array to track * the metrics required to compute all the per-rq utilization clamp values. */ struct uclamp_rq { //当前rq生效的clamp值 unsigned int value;
//每个cpu上有两个桶,分别是min和max struct uclamp_bucket bucket[UCLAMP_BUCKETS]; }; |
5.2.3 uclamp_bucket - 描述一个bucket
下面结构体只占用一个long型空间
|
/* * struct uclamp_bucket - Utilization clamp bucket * @value: utilization clamp value for tasks on this clamp bucket * @tasks: number of RUNNABLE tasks on this clamp bucket * * Keep track of how many tasks are RUNNABLE for a given utilization * clamp value. */ struct uclamp_bucket { //value表示此bucket中所有task生效clamp的最大值 //实际上就是enqueue到rq上的线程,也就是runnable的线程 unsigned long value : bits_per(SCHED_CAPACITY_SCALE);
//记录当前bucket内有多少个task unsigned long tasks : BITS_PER_LONG - bits_per(SCHED_CAPACITY_SCALE); }; |
上面bits_per实现如下,函数含义表示:至少需要多少个bit位,才能描述一个0~n之间的常数,实际就是求2的对数,bits_per(1023)=10, bits_per(1024)=11
文件位置位于:W:\opensource\linux-5.10.61\include\linux\log2.h
|
/** * bits_per - calculate the number of bits required for the argument * @n: parameter * * This is constant-capable and can be used for compile time * initializations, e.g bitfields. * * The first few values calculated by this routine: * bf(0) = 1 * bf(1) = 1 * bf(2) = 2 * bf(3) = 2 * bf(4) = 3 * ... and so on. */ #define bits_per(n) \ ( \ __builtin_constant_p(n) ? ( \ ((n) == 0 || (n) == 1) \ ? 1 : ilog2(n) + 1 \ ) : \ __bits_per(n) \ ) |
5.2.4 sched_class中对uclamp的支持
调度类sched_class中对uclamp的支持
|
struct sched_class {
#ifdef CONFIG_UCLAMP_TASK //标记这个调度类是否使能了uclamp机制,cfs和rt调度类默认是使能的 int uclamp_enabled; #endif ... } |
5.3 cpu的uclamp和task的uclamp的关系
关于cpu的uclamp值,需要注意下面两点:
a) 一个bucket的value,是这个bucket中所有task的uclamp值的最大值(不管是uclamp_min还是uclamp_max都是最大值),这也是上面为什么说,uclamp小的task将会受益于uclamp大的task
b) 这个cpu的rq->uclamp[clamp_id].value值始终记录着这个cpu上所有task中uclamp的最大值(不管是uclamp_min还是uclamp_max都是取最大值),这个在后面uclamp_rq_util_with中计算cpu的util的时候,这个cpu上所有uclamp较低的task,都将受益于这个uclamp最高的task,例如这个cpu上有一个任务的uclamp_min值设置为1024,那么在获取cpu的util值的时候会得到1024,拿他去调频将会把cpu的频率拉满,这可能会对功耗造成影响,但是这个boost的时间并不会持续太长,并且是有必要的。之所以说这个boost时间不会太长,是因为当rq->uclamp[clamp_id].value对应的桶中所有task都dequeue时,会重新从rq的桶中重新找一个新的最大值,这个最大值一定会比前一个要小一点,详见uclamp_rq_dec_id。之所以说这个boost过程很有必要,是因为当存在一个uclamp值较大的task在rq上时,说明这个rq上有一个很急迫的任务,如果cpu的频率拉不起来的话,会导致调度延迟很大,所以拉高频率可以确保这个很急迫的线程很快得到运行。
下面我们就来看一下,当一个task执行enqueue和dequeue操作时,这个rq的uclamp的变化
5.3.1 enqueue时
5.3.1.1 uclamp_rq_inc
调用路径:enqueue_task -> uclamp_rq_inc
|
static inline void uclamp_rq_inc( struct rq *rq, struct task_struct *p) //要enqueue到上面rq上的task { enum uclamp_id clamp_id;
/* * Avoid any overhead until uclamp is actually used by the userspace. * * The condition is constructed such that a NOP is generated when * sched_uclamp_used is disabled. */ //1.由上面的注释可知,static_key可以避免用户空间的任何开销,直到该 // 功能被真正的使能,当uclamp被禁用时,下面的语句实际上就是一句NOP // 好牛逼的样子,下次一定出一篇文章好好研究研究 if (!static_branch_unlikely(&sched_uclamp_used)) return;
//2.目前cfs和rt调度类默认都是使能了该标记的 if (unlikely(!p->sched_class->uclamp_enabled)) return;
//3.遍历每一个uclamp,执行加操作 for_each_clamp_id(clamp_id) uclamp_rq_inc_id(rq, p, clamp_id);
/* Reset clamp idle holding when there is one RUNNABLE task */ //4.UCLAMP_FLAG_IDLE标记这个cpu当前是不是处于idle状态,也就是这个 // cpu对应的rq上是不是没有任何task。上面刚enqueue一个task上来, // 这个cpu也就不再是idle了,如果设置了该标记,则取消 if (rq->uclamp_flags & UCLAMP_FLAG_IDLE) rq->uclamp_flags &= ~UCLAMP_FLAG_IDLE; } |
5.3.1.2 uclamp_rq_inc_id - 将task的uclamp规划进rq的桶中
由下面的注释可知,当一个task被enqueue到一个rq上时,这个task的uclamp信息也会被应用到这个rq上,调用路径:enqueue_task -> uclamp_rq_inc -> uclamp_rq_inc_id
|
/* * When a task is enqueued on a rq, the clamp bucket currently defined by the * task's uclamp::bucket_id is refcounted on that rq. This also immediately * updates the rq's clamp value if required. * * Tasks can have a task-specific value requested from user-space, track * within each bucket the maximum value for tasks refcounted in it. * This "local max aggregation" allows to track the exact "requested" value * for each bucket when all its RUNNABLE tasks require the same clamp. */ static inline void uclamp_rq_inc_id( struct rq *rq, struct task_struct *p, //要enqueue到上面rq上的task enum uclamp_id clamp_id) //标记min还是max { struct uclamp_rq *uc_rq = &rq->uclamp[clamp_id]; struct uclamp_se *uc_se = &p->uclamp[clamp_id]; struct uclamp_bucket *bucket;
lockdep_assert_held(&rq->lock);
/* Update task effective clamp */ //1.在enqueue的时候更新这个task的有效uclamp值,即task->uclamp // 这个task的有效uclamp,是uclamp_req受group和system共同嵌制后的值 p->uclamp[clamp_id] = uclamp_eff_get(p, clamp_id);
//2.根据这个task最终有效的uclamp信息,将这个task规划进rq对应的桶中 bucket = &uc_rq->bucket[uc_se->bucket_id]; bucket->tasks++; uc_se->active = true;
//3.通过UCLAMP_FLAG_IDLE标记,判断rq是否是刚从idle中退出,如果刚刚退出idle, // 说明rq上当前只有这一个task,则设置rq->uclamp[clamp_id].value为这个刚 // enqueue进来的task的有效uclamp值,即p->uclamp[clamp_id] uclamp_idle_reset(rq, clamp_id, uc_se->value);
/* * Local max aggregation: rq buckets always track the max * "requested" clamp value of its RUNNABLE tasks. */
//4.注意: // 一个bucket的value,是这个bucket中所有task的uclamp值的 // 最大值(不管是uclamp_min还是uclamp_max都是最大值),这也 // 是上面为什么说,uclamp小的task将会受益于uclamp大的task if (bucket->tasks == 1 || uc_se->value > bucket->value) bucket->value = uc_se->value;
//5.注意: // 这里修改了rq->uclamp[clamp_id].value,这个值始终记录着这个 // cpu上所有task中uclamp的最大值(不管是uclamp_min还是uclamp_max // 都是取最大值),这个在后面uclamp_rq_util_with中计算cpu的util // 的时候,这个cpu上所有uclamp较低的task,都将受益于这个uclamp // 最高的task,例如这个cpu上有一个任务的uclamp_min值设置为1024, // 那么在获取cpu的util值的时候会得到1024,拿他去调频将会把cpu的 // 频率拉满,这可能会对功耗造成影响 if (uc_se->value > READ_ONCE(uc_rq->value)) WRITE_ONCE(uc_rq->value, uc_se->value); } |
5.3.1.3 uclamp_idle_reset - enqueue第一个task时设置rq的uclamp信息
当rq从idle中退出时,使用第一个enqueue进来的task的uclamp信息作为这个rq的uclamp信息
|
static inline void uclamp_idle_reset( struct rq *rq, //这个task刚被enqueue到那个cpu上 enum uclamp_id clamp_id, unsigned int clamp_value) //刚enqueue上来的task对应的uclamp值 { /* Reset max-clamp retention only on idle exit */ //1.如果在这个task的uclamp被规划进来之前,这个cpu是处于idle // 状态,也就是这个刚enqueue进来的task是这个rq上第一个task, // 此时将这个task的uclamp赋值给rq->uclamp[clamp_id].value, // 因为老子是第一个task,否则直接返回 if (!(rq->uclamp_flags & UCLAMP_FLAG_IDLE)) return;
//2.代码走到这里,表示这个rq之前还是处于idle状态,但是刚queue上来 // 一个task后,这个rq便从idle状态中退出,此时这个rq上也只有 // 这么一个task,此时这个rq的uclamp就是这个task的uclamp信息 WRITE_ONCE(rq->uclamp[clamp_id].value, clamp_value); } |
5.3.2 dequeue时
5.3.2.1 uclamp_rq_dec
调用路径:enqueue_task -> uclamp_rq_dec
|
static inline void uclamp_rq_dec(struct rq *rq, struct task_struct *p) { enum uclamp_id clamp_id;
/* * Avoid any overhead until uclamp is actually used by the userspace. * * The condition is constructed such that a NOP is generated when * sched_uclamp_used is disabled. */ //1.超级牛逼的static_key if (!static_branch_unlikely(&sched_uclamp_used)) return;
//2.cfs和rt默认是使能的 if (unlikely(!p->sched_class->uclamp_enabled)) return;
//3.依次设置min和max for_each_clamp_id(clamp_id) uclamp_rq_dec_id(rq, p, clamp_id); } |
5.3.2.2 uclamp_rq_dec_id - 将task的uclamp信息从rq的桶中解除规划
调用路径:enqueue_task -> uclamp_rq_dec -> uclamp_rq_dec_id
|
/* * When a task is dequeued from a rq, the clamp bucket refcounted by the task * is released. If this is the last task reference counting the rq's max * active clamp value, then the rq's clamp value is updated. * * Both refcounted tasks and rq's cached clamp values are expected to be * always valid. If it's detected they are not, as defensive programming, * enforce the expected state and warn. */ static inline void uclamp_rq_dec_id( struct rq *rq, struct task_struct *p, //要从上面rq中dequeue的task enum uclamp_id clamp_id) //要dequeue的task对应的uclamp { struct uclamp_rq *uc_rq = &rq->uclamp[clamp_id]; struct uclamp_se *uc_se = &p->uclamp[clamp_id]; struct uclamp_bucket *bucket; unsigned int bkt_clamp; unsigned int rq_clamp;
lockdep_assert_held(&rq->lock);
/* * If sched_uclamp_used was enabled after task @p was enqueued, * we could end up with unbalanced call to uclamp_rq_dec_id(). * * In this case the uc_se->active flag should be false since no uclamp * accounting was performed at enqueue time and we can just return * here. * * Need to be careful of the following enqeueue/dequeue ordering * problem too * * enqueue(taskA) * // sched_uclamp_used gets enabled * enqueue(taskB) * dequeue(taskA) * // Must not decrement bukcet->tasks here * dequeue(taskB) * * where we could end up with stale data in uc_se and * bucket[uc_se->bucket_id]. * * The following check here eliminates the possibility of such race. */ //1.如果active没有被置位,则表示这个task的uclamp根本就 // 没有被加到rq的规划中去,也就不需要执行后面的移除动作 if (unlikely(!uc_se->active)) return;
//2.将这个task的uclamp信息从rq的桶中移除,并将uc_se->active设置为false bucket = &uc_rq->bucket[uc_se->bucket_id];
SCHED_WARN_ON(!bucket->tasks); if (likely(bucket->tasks)) bucket->tasks--;
uc_se->active = false;
/* * Keep "local max aggregation" simple and accept to (possibly) * overboost some RUNNABLE tasks in the same bucket. * The rq clamp bucket value is reset to its base value whenever * there are no more RUNNABLE tasks refcounting it. */ //3.如果从bucket中解除该task的规划后,bucket中还有其它task,直接返回 // 需要注意的是,这里直接退出时并没有更新bucket->value和rq->uclamp[clamp_id].value // 理论上确实应该更新这两个值,但是由上面的注释可知,这里是为了简化代码逻辑,即使是一个 // 较大的uclamp值从rq的规划中移除也不会更新这两个值,造成的影响是这个已经被移除的大 // uclamp值将会继续影响着这个cpu上RUNNABLE状态的task,也就是继续overboost着,但是 // patch设计者认为这是可以接受的,因为这个overboost过程不会持续太久,当这个rq上没有 // 任何任务时,即将进入idle时,会更新bucket->value和rq->uclamp[clamp_id].value, // 这也是下面第4步代码逻辑了。另一方面,bucket->value和rq->uclamp[clamp_id].value // 记录的最大值对应的task可能已经出列了,并不一定在rq上 if (likely(bucket->tasks)) return;
rq_clamp = READ_ONCE(uc_rq->value); /* * Defensive programming: this should never happen. If it happens, * e.g. due to future modification, warn and fixup the expected value. */
//4.bucket->value应该永远不可能大于rq->uclamp[clamp_id].value, // 如果出现大于的情况,打印调试信息 SCHED_WARN_ON(bucket->value > rq_clamp);
//5.虽然不太可能出现大于的情况,但还是有可能出现等于的情况的,当uclamp // 值最大对应的那个bucket中的所有task全部死绝了会出现等于的情况,此 // 时需要从rq的其他的buctek(其他bucket中可能还有task)中重新选出 // 一个uclamp最大值,并将其赋值给rq->uclamp[clamp_id]。 // 如果这个rq上的所有的task全部dequeue了,这个rq即将进入idle状态, // 此时会将rq的uclamp_min设置为0,uclamp_max设置为最后退出rq的task // 对应的uclamp_max,详见uclamp_rq_max_value的实现 if (bucket->value >= rq_clamp) { bkt_clamp = uclamp_rq_max_value(rq, clamp_id, uc_se->value); WRITE_ONCE(uc_rq->value, bkt_clamp); } } |
5.3.2.3 uclamp_rq_max_value - 遍历rq的所有bucket,得到uclamp的最大值
|
static inline unsigned int uclamp_rq_max_value( struct rq *rq, //从哪个cpu上dequeue enum uclamp_id clamp_id, unsigned int clamp_value) //要dequeue的task对应的uclamp值 { struct uclamp_bucket *bucket = rq->uclamp[clamp_id].bucket; int bucket_id = UCLAMP_BUCKETS - 1;
/* * Since both min and max clamps are max aggregated, find the * top most bucket with tasks in. */ //1.反向遍历这个rq上的所有bucket,直到找到一个里面有task的bucket // 那么这个bucket中记录的uclamp值就是这个rq上的最大值 for ( ; bucket_id >= 0; bucket_id--) { if (!bucket[bucket_id].tasks) continue; return bucket[bucket_id].value; }
/* No tasks -- default clamp values */ //2.当这个rq上没有任何任务时,会走到这里,这时候这个cpu即将进入idle状态 // 此时将rq->uclamp[clamp_id].values设置为默认值,即uclamp_min为0, // uclamp_max设置为最后一个退出的task的uclamp_max return uclamp_idle_value(rq, clamp_id, clamp_value); } |
5.3.2.4 uclamp_idle_value - rq进入idle时,uclamp恢复默认值
|
static inline unsigned int uclamp_idle_value( struct rq *rq, enum uclamp_id clamp_id, unsigned int clamp_value) //最后一个dequeue的task对应的uclamp { /* * Avoid blocked utilization pushing up the frequency when we go * idle (which drops the max-clamp) by retaining the last known * max-clamp. */ //1.注意,执行到这个函数表示这个task是rq上最后一个task,被dequeue后 // 这个rq上就没有任何task了,即将进入idle状态。此时对应uclamp_min // 设置为0,对于uclamp_max做如下处理: // a) 打上UCLAMP_FLAG_IDLE标签 // b) 这个最后dequeue的task的uclamp_max作为rq->uclamp[UCLAMP_MAX].value // 为啥捏???这里笔者没有想明白! if (clamp_id == UCLAMP_MAX) { rq->uclamp_flags |= UCLAMP_FLAG_IDLE; return clamp_value; }
//2.对uclamp_min恢复默认值0 // 在调频时,如果某个cluster中有一个cpu已经进入idle,因为这个idle // 的cpu获取到的uclamp_min为0,并且已经idle的cpu在调用uclamp_rq_util_with // 时传入的util值也为0,经过clamp后的util还是0,所以这个已经进入 // idle的cpu不会对调频有贡献 // 详见:sugov_next_freq_shared -> sugov_get_util -> // schedutil_cpu_util -> uclamp_rq_util_with return uclamp_none(UCLAMP_MIN); } |
5.3.2.5 uclamp_none - 表示没有uclamp是的min和max钳位值
|
static inline unsigned int uclamp_none(enum uclamp_id clamp_id) { if (clamp_id == UCLAMP_MIN) return 0; return SCHED_CAPACITY_SCALE; } |
5.4 计算cpu的util值
cpu的util值主要有两个用途,所以为了保证这个cpu上所有RUNNABLE状态的task的性能,这个cpu的uclamp_min和uclamp_max值均取最大值
调频:在调频点在计算cpu的util的时候,需要保证cpu的util值落在uclamp_min ~ uclamp_max之间,详见sugov_get_util -> schedutil_cpu_util -> uclamp_rq_util_with
选核:当一个新的任务p即将放到这个cpu上来时,会先判断如果将这个task的util累加到cpu上,会不会导致cpu的util溢出(预留20%的余量,详见find_energy_efficient_cpu -> uclamp_rq_util_with实现)
5.4.1 schedutil_cpu_util - 计算cpu的util值
该函数用于获取指定cpu的util值,用于调频,调用路径:
sugov_next_freq_shared -> sugov_get_util -> schedutil_cpu_util -> uclamp_rq_util_with
W:\opensource\linux-5.10.61\kernel\sched\cpufreq_schedutil.c
|
/* * This function computes an effective utilization for the given CPU, to be * used for frequency selection given the linear relation: f = u * f_max. * * The scheduler tracks the following metrics: * * cpu_util_{cfs,rt,dl,irq}() * cpu_bw_dl() * * Where the cfs,rt and dl util numbers are tracked with the same metric and * synchronized windows and are thus directly comparable. * * The cfs,rt,dl utilization are the running times measured with rq->clock_task * which excludes things like IRQ and steal-time. These latter are then accrued * in the irq utilization. * * The DL bandwidth number otoh is not a measured metric but a value computed * based on the task model parameters and gives the minimal utilization * required to meet deadlines. */ unsigned long schedutil_cpu_util( int cpu, //要获取哪个cpu的util unsigned long util_cfs, unsigned long max, enum schedutil_type type, struct task_struct *p) //在获取cpu的util时加上这个p的util值 { //因为在选核时这个p还没有放到这个cpu上 unsigned long dl_util, util, irq; struct rq *rq = cpu_rq(cpu);
//1.如果不需要进行uclamp操作,则在调频的时候,只要有rt任务,就将频率拉满 if (!uclamp_is_used() && type == FREQUENCY_UTIL && rt_rq_is_runnable(&rq->rt)) { return max; }
...
//2.cpu的util值为这个cpu上所有cfs和rt任务的util值之和 util = util_cfs + cpu_util_rt(rq);
//3.对上面这个util值进行clamp操作 // 在为p选核时,这个p还没有被放到这个cpu上,所以上面 // 第二步中计算出来的util值还没有包括这个p的util值 if (type == FREQUENCY_UTIL) util = uclamp_rq_util_with(rq, util, p);
... } |
5.4.2 uclamp_rq_util_with - 对指定util值,返回rq的util值
我们最终会用util值去选核或者调频,util值大就有可能选上大核,就有可能调到更高的频率
|
/** * uclamp_rq_util_with - clamp @util with @rq and @p effective uclamp values. * @rq: The rq to clamp against. Must not be NULL. * @util: The util value to clamp. * @p: The task to clamp against. Can be NULL if you want to clamp against @rq only. * * Clamps the passed @util to the max(@rq, @p) effective uclamp values. * * If sched_uclamp_used static key is disabled, then just return the util * without any clamping since uclamp aggregation at the rq level in the fast * path is disabled, rendering this operation a NOP. * * Use uclamp_eff_value() if you don't care about uclamp values at rq level. It * will return the correct effective uclamp value of the task even if the * static key is disabled. */ static __always_inline unsigned long uclamp_rq_util_with( struct rq *rq, //受到那个rq的影响 unsigned long util, //要进行uclamp的值,即pelt跟踪得到的cpu的util struct task_struct *p) //调频时传入NULL,选核时不为NULL { unsigned long min_util = 0; unsigned long max_util = 0;
//1.钳位机制没有被使能,则返回 if (!static_branch_likely(&sched_uclamp_used)) return util;
//2.先计算出这个即将enqueue的task的有效uclamp信息 // 调频时传入的p为NULL,选核时传入的p不为NULL if (p) { //2.1 计算task有效uclamp,即group, system共同作用的uclamp范围 min_util = uclamp_eff_value(p, UCLAMP_MIN); max_util = uclamp_eff_value(p, UCLAMP_MAX);
/* * Ignore last runnable task's max clamp, as this task will * reset it. Similarly, no need to read the rq's min clamp. */ //2.2 下面场景表示为p选核时选到了一个idle的cpu,当前rq上没有 // 任何task,这个即将enqueue的task将会是这个rq上第一个task, // 这个task的uclamp也就是这个rq的uclamp,直接使用这个task // 的有效uclamp去约束这个util即可 // 另一方面,由上面对uclamp_rq_dec_id的分析可知,已经idle的rq, // 他的rq->uclamp[UCLAMP_MAX].value中记录的是上一次最后一个退出 // rq的task对应的uclamp_max值,这个值是没有意义的 if (rq->uclamp_flags & UCLAMP_FLAG_IDLE) goto out; }
//2.3 得到rq的uclamp信息 // 调频时传入的p为NULL时,下面得到的就是rq的uclamp_min和uclamp_max // 选核时传入的p不为NULL时,下面得到uclamp表示:将这个p添加进rq之后, // rq的uclamp_min和uclamp_max min_util = max_t(unsigned long, min_util, READ_ONCE(rq->uclamp[UCLAMP_MIN].value)); max_util = max_t(unsigned long, max_util, READ_ONCE(rq->uclamp[UCLAMP_MAX].value)); out: /* * Since CPU's {min,max}_util clamps are MAX aggregated considering * RUNNABLE tasks with _different_ clamps, we can end up with an * inversion. Fix it now when the clamps are applied. */ //2.4 由上面的注释可知,cpu维度的uclamp_min和uclamp_max是MAX aggregated的, // 也就是取最大值,所以这里有可能会出现uclamp_min大于uclamp_max的情况,在这 // 里做调整 if (unlikely(min_util >= max_util)) return min_util;
//3.使用最终的uclamp范围钳他狗日的 return clamp(util, min_util, max_util); } |
六、参考文档
https://lwn.net/Articles/762043/
https://blog.csdn.net/liglei/article/details/103659689
https://www.cnblogs.com/hellokitty2/p/15636035.html
https://blog.csdn.net/qq_52358151/article/details/112558800

文章评论
123321
456654
258
669
kernel 5.4上设置 cpu.uclamp.max 50不生效,怎么排查哪里的问题呢,有开关吗?