关注公众号不迷路:DumpStack
扫码加关注

目录
- 一、前言
- 二、PELT负载计算原理
- 三、PELT原理的代码实现
- 四、时间和权重
- 五、更新se的负载
- 六、更新blocked_se的负载
- 七、更新cfs_rq队列的负载
- 八、更新rt_rq队列的负载,记录在rq结构中:rq->avg_rt
- 九、更新dl_rq队列的负载,记录在rq结构中:rq->avg_dl
- 十、更新irq的负载,记录在rq结构中:rq->avg_irq
- 十一、更新group的负载
- 十二、负载更新流程
- 十三、负载更新时机
- 十四、se的负载信息和cfs_rq的关系
- 十五、cpu负载发生变化时触发调频
- 十六、本章涉及函数
- 十七、参考文档
- 关注公众号不迷路:DumpStack
PELT,是per-entity load tracking的缩写,也就是以entity为单位进行负载跟踪,与之相对的是per-rq load tracking,即以rq为单位进行负载跟踪
注:本文分析基于Linux 5.10.61
一、前言
注:本章摘自蜗窝科技
1.1 为何要进行负载跟踪?
对于Linux内核而言,做一款好的进程调度器是一项非常具有挑战性的任务,主要原因是在进行CPU资源分配的时候必须满足如下的需求:
-
它必须是公平的
-
快速响应
-
系统的throughput(吞吐量)要高
-
功耗要小
其实你仔细分析上面的需求,这些目标其实是相互冲突的,但是用户在提需求的时候就是这么任性,他们期望所有的需求都满足,而且不管系统中的负荷情况如何。因此,纵观Linux内核调度器这些年的发展,各种调度器算法在内核中来来去去,这也就不足为奇了。当然,2007年,2.6.23版本引入"完全公平调度器"(CFS)之后,调度器相对变得稳定一些。最近一个最重大的变化是在3.8版中合并的Per-entity load tracking。
完美的调度算法需要一个能够预知未来的水晶球:只有当内核准确地推测出每个进程对系统的需求,她才能最佳地完成调度任务。不幸的是,硬件制造商推出各种性能强劲的处理器,但从来也不考虑预测进程负载的需求,在没有硬件支持的情况下,调度器只能祭出通用的预测大法:用"过去"预测"未来",也就是说调度器是基于过去的调度信息来预测未来该进程对CPU的需求。而在这些过去的调度信息中,每一个进程过去的"性能"信息是核心要考虑的因素
1.2 为何是per-entity,而不是以per-rq的方式进行负载跟踪
3.8版本之前的内核CFS调度器在计算CPU load的时候采用的是跟踪每个运行队列上的负载(per-rq load tracking)。但是CFS中的"运行队列"实际上是有多个,至少每个CPU就有一个runqueue,而且,当使用"按组调度"(group scheduling)功能时,每个控制组(control group)都有自己的per-CPU运行队列。对于per-rq的负载跟踪方法,调度器可以了解到每个运行队列对整个系统负载的贡献,这样的统计信息足以帮助组调度器(group scheduler)在控制组之间分配CPU时间,但从整个系统的角度看,per-rq跟踪的方法存在如下两个问题:
-
并不知道当前负载来自哪一个线程;
-
即使在工作负载相对稳定的情况下,跟踪到的运行队列的负载值也会变化很大;
pelt解决了这些问题,这是通过把负载跟踪从per-rq推进到per-entity的层次
1.3 其他子系统可以利用pelt值做些什么呢?
我们可以通过跟踪的per entity负载值做一些有用的事情,最明显的使用场景可能是用于负载均衡:即把running+runnable进程平均分配到系统的CPU上,使每个CPU承载大致相同的负载。如果内核知道每个进程对系统负载有多大贡献,它可以很容易地计算迁移到另一个CPU的效果。这样进程迁移的结果应该更准确,从而使得负载平衡不易出错。
small-task packing patch的目标是将"小"进程收集到系统中的部分CPU上,从而允许系统中的其他处理器进入低功耗模式。在这种情况下,显然我们需要一种方法来计算得出哪些进程是"小"的进程。利用per-entity load tracking,内核可以轻松的进行识别。
内核中的其他子系统也可以使用per entity负载值做一些文章。CPU频率调节器(CPU frequency governor)和功率调节器(CPU power governor)可以利用per entity负载值来猜测在不久的将来,系统需要提供多少的CPU计算能力。
既然有了pelt这样的基础设施,我们期待看到开发人员可以使用per-entity负载信息来优化系统的行为。虽然pelt仍然不是一个能够预测未来的水晶球,但至少我们对当前的系统中的进程对CPU资源的需求有了更好的理解。
1.4 usage和load的差异
有人可能会问:"消耗的CPU时间"和"负载(load)"是否有区别?
是的,当然有区别,Paul Turner在提交per-entity load tracking补丁集的时候对这个问题做了回答。一个进程即便当前没有在cpu上运行,例如该进程仅仅是挂入runqueue等待执行,它也能够对cpu负载作出贡献。"负载"是一个瞬时量,表示当前时刻进程对系统产生的"压力"是怎样的,显然runqueue中有10个等待运行的进程对系统造成的"压力"要大于一个runqueue中只有1个等待进程的场景。与之相对的是"CPU使用率(usage)",它是一个累积量。有一个长时间运行的进程,它可能在很久以前曾经占用大量的处理器时间,但是现在可能占用很少的cpu时间,尽管它过去曾经"辉煌"过(占用大量CPU时间),但这对现在的系统负荷贡献很小。
因此,笔者认为usage和load至少有下面几个差异:
-
usage是时间的累加,不需要考虑衰减,而load需要衰减
-
uasge只关注线程的running状态,不关注runnable,而load需要同时running+runnable状态
我们之前在排查问题的时候经常会用下面的方式计算整机负载,实际上下面计算出来的是这段时间内的usage,load和usage还是有较大的差异的
二、PELT负载计算原理
2.1 pelt负载计算原理
一个pelt周期为1024us,即1ms
在pelt中,entity的运行时间,按照1024us的大小被分为一个个小的周期,例如这个entity在一个周期中处于running+runnable状态(正在cpu上运行或者等待运行)的时间为x,那么他在这个周期中对系统负载的贡献就是x
上面仅考虑当前周期,在计算过去某个周期的负载对当前周期的贡献时,需要乘以一个衰减因子y,例如过去第i个周期的运行时间为Li,则这个周期对当前周期的负载带来的贡献为:
|
Li*y^i |
那么这个entity在过去所有周期中,对当前系统负载的贡献如下:
|
L = L0 + L1*y + L2*y^2 + L3*y^3 + ... + Ln*y^n |
这里需要注意两点:
-
上式仅仅是一个entity对系统的负载贡献,如果需要计算当前时刻整个系统的负载贡献,则需要将所有entity的贡献都加起来;
-
因为我们在计算这个entity对当前周期的负载贡献时,会累积在过去所有周期中的负载贡献,所以这个entity对当前周期的负载贡献可能会超过1024us;
那么衰减因子y是多少呢?我们约定:一个周期的负载在经历32个周期后(即32ms),对当前周期的负载的贡献减半,即y^32=0.5,这样y的值就固定了,如下:
注意:因为当周期超过32*63之后,贡献就会清零,所以可以理解pelt只关注最近的32*63周期的运行状态
|
y^32= 0.5, y = 0.97857206 |
举个例子,如果有一个task,从第一次加入rq后开始一直运行4096us后一直睡眠,那么它在经历1023us、2047us、3071us、4095us、5119us、6143us、7167us和8191us后的负载贡献分别是多少呢?
|
1023us: L0 = 1023 2047us: L1 = 1023 + 1024 * y = 1023 + (L0 + 1) * y = 2025 3071us: L2 = 1023 + 1024 * y + 1024 * y^2 = 1023 + (L1 + 1) * y = 3005 4095us: L3 = 1023 + 1024 * y + 1024 * y^2 + 1024 * y^3 = 1023 + (L2 + 1) * y = 3963 5119us: L4 = 0 + 1024 * y + 1024 * y^2 + 1024 * y^3 + 1024 * y^4 = 0 + (L3 + 1) * y = 3877 6143us: L5 = 0 + 0 * y + 1024 * y^2 + 1024 * y^3 + 1024 * y^4 + 1024 * y^5 = 0 + L4 * y = 3792 7167us: L6 = 0 + L5 * y = L4 * y^2 = 3709 8191us: L7 = 0 + L6 * y = L5 * y^2 = L4 * y^3 = 3627 |
通过上面的公式可以看出:
-
调度实体对系统的负载贡献是一个等比数列之和
-
周期最近的贡献拥有最大的权重
-
过去周期的负载贡献也会被累计,但是其影响随着时间的增加而衰减
使用这样序列的好处是计算简单,我们不需要使用数组来记录过去的所有周期的负载贡献,只要把上一个周期总的负载贡献值乘以y再加上新的L0负载贡献就OK了。即在当前时刻,计算一个任务的所有运行时间,对系统负载的贡献,只需要将"上个周期及其之前的负载贡献"乘以衰减系数y,并加上当前时间点所在的周期的负载即可。具体如下:
|
L = 上一个周期对系统的总的负载贡献*y + 本周期的系统负载 |
一旦我们有了计算running+runnable调度实体负载贡献值的方法,那么这个贡献值可以向上传递,通过累加control group中的每一个调度实体贡献值可以得到该control group对应的调度实体的贡献值。这样的算法不断的向上推进,可以得到整个系统的负载
2.2 情景分析:计算一个task的负载贡献
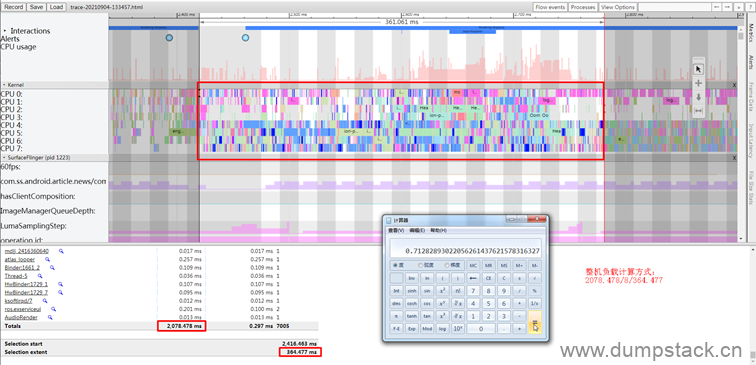
假设一个task开始从0时刻运行,那么1022us后的负载贡献自然就是1022,当task再经过10us之后,此时(现在时刻是1032us)的负载贡献又是多少呢?
很简单,我们把这次运行的10us分成两个部分:
-
2us补齐上一时刻不足1024us部分,凑成一个周期,即上面的B部分;
-
当前时刻不足一个周期的剩余8us部分,即上面的C部分;
B和A可以凑成一个周期1024us,这个1024us需要进行一次衰减;而C在本周期之内,因此不需要衰减。这时候,这个task的整个运行过程中,对当前周期系统负载的贡献为:
|
(A+B)y + C = [1022 + (1024 - 1022)]y + [10 - (1024 - 1022)] = 1022y + 2y + 8 = 1010 |
上面1022y + 2y + 8可以这样理解成:
-
A由于在上一个周期,因此需要衰减1次;
-
B由于也在上一个周期,因此也需要衰减1次;
-
C由于在当前周期,因此不需要衰减;
注意:上面计算得到的1010是t2时刻的负载情况,之后我们在计算负载的时候,只需要在t2时刻的基础上进行衰减即可,无需再关注t2时刻之前的详细细节;
笔者注:是不是很难接受,连续运行的10ms被分成了两个部分,并且有一部分需要衰减,另一部分却不需要衰减!!!但是这个算法就是这样的
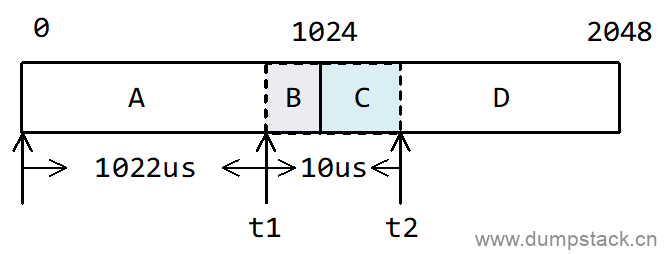
假如在上面的基础上又经过了2124us,即在t3时刻的负载贡献又是多少呢?

这里我们继续将2124us分解成3个部分:
-
1016us补齐上一时刻不足1024us部分,凑成一个周期,即上面的D部分;
-
1024us一个整周期,即上面的E部分;
-
当前时刻不足一个周期的剩余84us部分,即上面的F部分;
因为上面我们已经计算出了t2时刻的负载贡献,就不需要再关注t2之前的详细运行情况了,因此t3时刻的负载贡献应该为:t2*y^2 + D*y^2 + E*y + F,各个部分解释如下:
-
t2之前的负载贡献,完全由t2时刻的负载贡献表示,不用再重复计算t2之前的负载贡献
-
t2时刻,由于相对于t3时刻,是在上上个周期里面,也就是在t3的前面第二个周期,因此需要衰减两次,即t2*y^2
-
D相对于t3时刻,也是在上上个周期里面,也就是在t3的前面第二个周期,因此也需要衰减两次,即D*y^2
-
E相对于t3时刻,是在上一个周期里面,也就是在t3的前面第一个周期,因此只需要衰减一次,即E*y
-
F就是在本周期内,不需要衰减,直接加上F就可以了
因此,t3时刻,这个任务对系统负载的贡献为:
|
1010*y^2 + (1024 - 8)*y^2 + 1024*y + [2124 - 1024 - (1024 - 8)] = 1010*y^2 + 1016*y^2 + 1024*y + 84 = 3024 |
2.3 通用方法
针对以上示例,我们可以得到一个更通用情况下的计算公式:
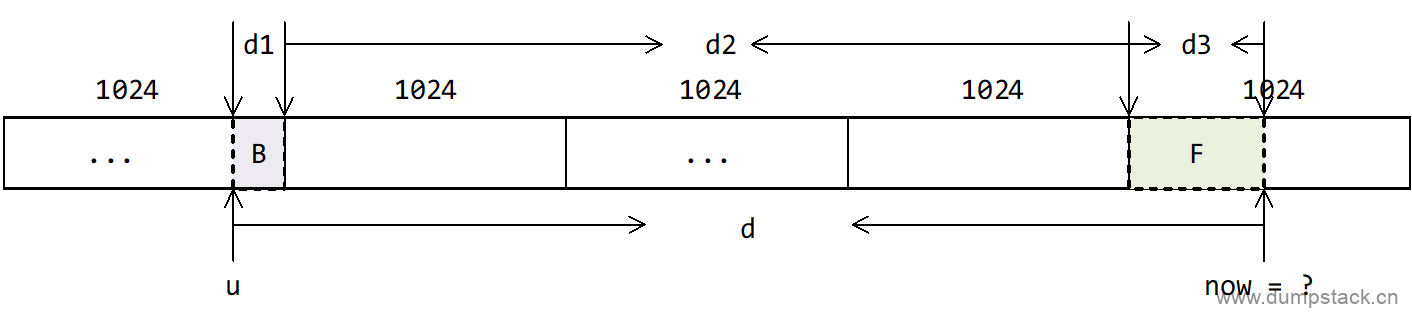
假设上一个统计时刻负载贡献是u,经历d时间后的负载贡献如何计算呢?根据上面的例子,我们可以把时间d分成3和部分:
-
d1是离当前时刻最远(不完整的)period的剩余部分
-
d2是完整period时间
-
而d3是(不完整的)当前period的剩余部分
由上图我们知道,u在当前时刻now前面的第p个周期里面,则有
|
p = 1 + (d2/1024) |
则由之前的结论,可知在当前时刻now,这个task的负载对当前系统的负载的贡献为:
|
L = u*y^p + d1*y^p + [1024*y^(p-1) + 1024*y^(p-2) + ... + 1024*y] + d3 = u*y^p + d1*y^p + 1024*[y^(p-1) + y^(p-2) + ... + y] + d3 p-1 = u*y^p + d1*y^p + 1024*\Sum y^i + d3 i=1 |
之前的例子现在就可以套用上面的公式计算,例如,上一次的负载贡献u=1010,经过时间d=2124us,可以分解成3部分,d1=1016us,d2=1024,d3=84,经历的周期p=2,所以这个任务对当前时刻的系统负载的贡献为:L=1010y^2 + 1016y^2+ 1024y + 84,与上面计算结果一致。
三、PELT原理的代码实现
3.1 数据结构
3.1.1 sched_avg - 记录se或cfs_rq的负载信息
Linux中使用sched_avg结构体记录调度实体se或cfs_rq负载信息,每个调度实体se以及cfs_rq结构体中都包含一个sched_avg结构体用于记录负载信息。
sum关键字的含义是:在task的整个生命周期中,负载的总和
avg关键字的含义是:在task的整个生命周期中,平均每个us该task的负载的值
|
/* * The load/runnable/util_avg accumulates an infinite geometric series * (see __update_load_avg_cfs_rq() in kernel/sched/pelt.c). * * [load_avg definition] * * load_avg = runnable% * scale_load_down(load) * * [runnable_avg definition] * * runnable_avg = runnable% * SCHED_CAPACITY_SCALE * * [util_avg definition] * * util_avg = running% * SCHED_CAPACITY_SCALE * * where runnable% is the time ratio that a sched_entity is runnable and * running% the time ratio that a sched_entity is running. * * For cfs_rq, they are the aggregated values of all runnable and blocked * sched_entities. * * The load/runnable/util_avg doesn't directly factor frequency scaling and CPU * capacity scaling. The scaling is done through the rq_clock_pelt that is used * for computing those signals (see update_rq_clock_pelt()) * * N.B., the above ratios (runnable% and running%) themselves are in the * range of [0, 1]. To do fixed point arithmetics, we therefore scale them * to as large a range as necessary. This is for example reflected by * util_avg's SCHED_CAPACITY_SCALE. * * [Overflow issue] * * The 64-bit load_sum can have 4353082796 (=2^64/47742/88761) entities * with the highest load (=88761), always runnable on a single cfs_rq, * and should not overflow as the number already hits PID_MAX_LIMIT. * * For all other cases (including 32-bit kernels), struct load_weight's * weight will overflow first before we do, because: * * Max(load_avg) <= Max(load.weight) * * Then it is the load_weight's responsibility to consider overflow * issues. */ struct sched_avg { //上一次负载更新的时间戳,以ns为单位的时间戳,这个时间一定是1024边界对齐的, //注意:初始化和线程迁移时,该标记会被清零 u64 last_update_time;
//整个生命周期负载总和 u64 load_sum; u64 runnable_sum; u32 util_sum;
//上次更新时,未满一个pelt周期的部分,单位us u32 period_contrib;
//整个生命周期,平均每个ns负载的值 unsigned long load_avg; //running+runnable状态,向权重做归一化 unsigned long runnable_avg; //running+runnable状态,向1024做归一化,不考虑权重 unsigned long util_avg; //仅running状态,向1024做归一化,不考虑权重
//保存cfs线程上一次在睡眠时的util值(这个值是经过滑动平均后的值) struct util_est util_est; } ____cacheline_aligned; |
3.1.2 sched_entity - 调度实体
一个调度实体se对应一个task或group
|
struct sched_entity { /* For load-balancing: */ //这个se的权重 struct load_weight load; struct rb_node run_node; struct list_head group_node; unsigned int on_rq;
u64 exec_start; u64 sum_exec_runtime; u64 vruntime; u64 prev_sum_exec_runtime;
u64 nr_migrations;
struct sched_statistics statistics;
#ifdef CONFIG_FAIR_GROUP_SCHED int depth; struct sched_entity *parent; /* rq on which this entity is (to be) queued: */ struct cfs_rq *cfs_rq; /* rq "owned" by this entity/group: */ struct cfs_rq *my_q;
//runnable_weight称作可运行权重,该概念主要针对group se提出 //对于task se来说,runnable_weight的值就是和进程权重weight相等 //对于group se来说,runnable_weight的值h_nr_running /* cached value of my_q->h_nr_running */ unsigned long runnable_weight; #endif
#ifdef CONFIG_SMP /* * Per entity load average tracking. * * Put into separate cache line so it does not * collide with read-mostly values above. */ //记录当前se的负载信息 struct sched_avg avg; #endif }; |
3.1.3 load_weight - 权重
对于task来说,表示这个task的权重,对于group来说,表示这个group下所有task的权重之和
|
struct load_weight { unsigned long weight; //权重 u32 inv_weight; //inv_weight等于2^32/weight,为了方便后面的计算 }; |
3.2 PELT的算法基础
一个算法即使再牛逼,如果算法的引进会带来太多的开销的话,也很难落地到真正的项目中去,下面介绍PELT算法在实现时用到的两个技巧,这对我们下面理解pelt算法或以后自己编码均有一定的启发作用
3.2.1 将"浮点运算"转化为"乘法+移位"操作
为什么要转化,原因如下:
-
CPU执行乘法和移位操作要比浮点操作快得多,开销也更低
-
有的处理器可能都不支持浮点操作
例如我们的代码中需要实现两个数相除,推导过程如下:
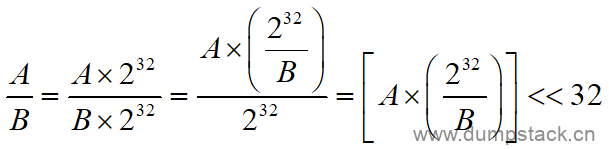
举例:
-
小数小于1,例如A*0.12
我们将0.12乘以2^32,然后在右移32bit,而0.12乘以2^32可在编程的之前完成,数值作为一个常量记录在一个全局变量N中,N = 0.12*(2^32) = 515396075.52 ≈ 515396076 = 0x1EB8_51EC
则A*0.12 = (A*N)>>32
-
小数大于1,例如A*12.34
这时候再按照上面的方法,计算得到的N = 12.34*2^32 = 52999896432.64 ≈ 52999896433 = 0xC_570A_3D71,注意到,这里的N大于32bit了,怎么办呢?有两种方法:
-
乘以2^20,然后右移20位;
-
将小数缩小,此处缩小100倍,用0.1234计算N,计算得到的最终结果再乘以100即可;
3.2.2 PELT中的查表操作
PELT中有一个衰减系数y,并且需要保证y^32=0.5,这样y的值实际上是固定的,即y≈0.97857206,注意到,y是一个小于0的小数。考虑到浮点数计算太慢,而且有的CPU甚至没有浮点单元,因此我们要使用上面的方法将浮点运算转化为"乘法+移位"操作。
使用PELT算法,计算一个task在过去连续n个周期的负载的公式如下:
|
L = L0 + L1*y + L2*y^2 + L3*y^3 + ... + Ln*y^n |
由上面的公式可知,在计算负载的时候,我们需要频繁的使用y^0,y^1,y^2,...,y^n,因此我们可以做下面这样的一个表:
|
float f_table[] = { y^0, y^1, y^2, y^3, y^4, y^5, ... ... y^30, y^31 } = { 0.999, 0.978, 0.957, 0.937, 0.917, 0.897, ... ... 0.522, 0.510 }; |
注意到,上面表格中只有y^31,这是因为y^32=0.5,因此,当n大于32的时候可以直接除以2,即:
|
y^35 = y^32 * y^3 = 0.5 * y^3 y^77 = y^32 * y^32 * y^13 = 0.5 * 0.5 * y^13 |
另外,上面表格中的值都是小数,由上面将"浮点运算"转化为"乘法+移位"操作的原理,我们得到下面的一个表格。
需要说明的是,如果你使用y≈0.97857206手动计算下面的表格的话,会发现得到的结果和表格中的数据会存在误差,这是因为y是一个无线循环小数,因此你手动计算的时候,不管取多少位,都会存在误差,一般下面表格中的数据是代码跑出来的,因此更精确。具体计算方法可以参考内核文档/Documentation/scheduler/sched-pelt.c
|
u32 runnable_avg_yN_inv[i] = f_table[i] * (2^32) = { 0xffffffff, 0xfa83b2da, 0xf5257d14, 0xefe4b99a, 0xeac0c6e6, 0xe5b906e6, 0xe0ccdeeb, 0xdbfbb796, 0xd744fcc9, 0xd2a81d91, 0xce248c14, 0xc9b9bd85, 0xc5672a10, 0xc12c4cc9, 0xbd08a39e, 0xb8fbaf46, 0xb504f333, 0xb123f581, 0xad583ee9, 0xa9a15ab4, 0xa5fed6a9, 0xa2704302, 0x9ef5325f, 0x9b8d39b9, 0x9837f050, 0x94f4efa8, 0x91c3d373, 0x8ea4398a, 0x8b95c1e3, 0x88980e80, 0x85aac367, 0x82cd8698, }; |
这样,上面的计算公式可以转化如下,直接查表就可以了:
|
L = L0 + L1*y + L2*y^2 + L3*y^3 + ... + Ln*y^n = (L0*runnable_avg_yN_inv[0] + L1*runnable_avg_yN_inv[1] + ... + Ln*runnable_avg_yN_inv[n]) >> 32 |
3.3 再看"负载贡献"的计算原理
所谓"负载贡献"实际上就是一段时间,只不过会对过去的周期做衰减。
如下图所示,已知一个task在之前某个时刻的负载贡献为u,则在经历delta微秒后,这个task对当前时刻的系统负载的贡献是多少呢?
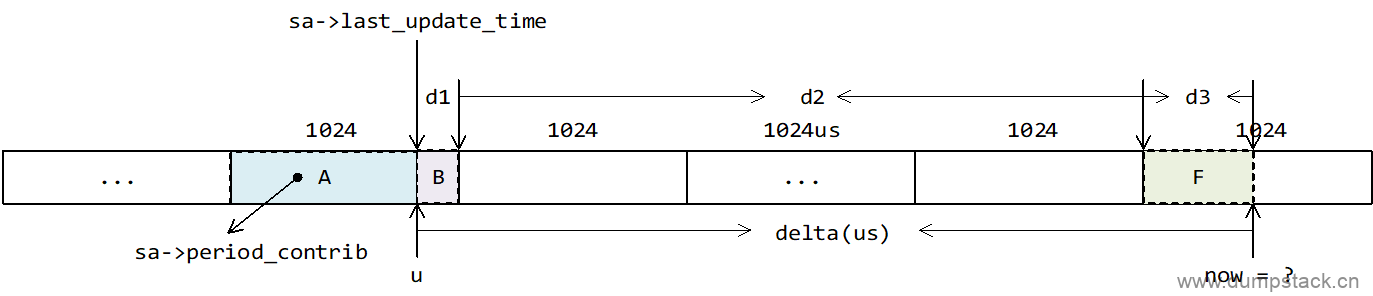
由上面分析可知,这个task在经历delta微秒后,对当前系统负载的贡献计算公式如下:
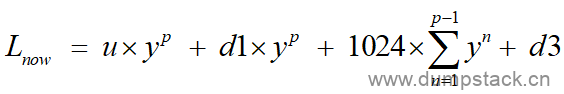 (式1)
(式1)
其中p表示在d2阶段存在多少个整数周期,具体值如下:
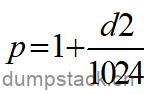
要计算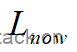 ,我们分两步来计算:
,我们分两步来计算:
第一步计算下面式2,也就是考虑历史负载的贡献,即已知过去的一段时间u,在经历过p个pelt周期后的功效,该操作可以通过调用decay_load(u, p)实现
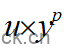 (式2)
(式2)
第二步计算下面式3,也就是d1到d3之间的新增负载的贡献:
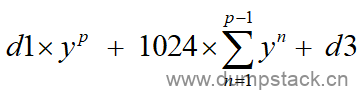 (式3)
(式3)
为了完成该操作,我们需要先对中间的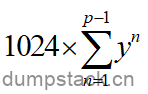 进行展开,具体如下:
进行展开,具体如下:
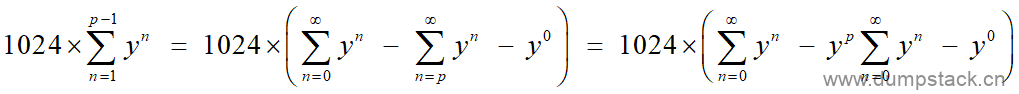 (式4)
(式4)
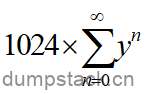 是一个等比数列,由于衰减系数y<1,因此
是一个等比数列,由于衰减系数y<1,因此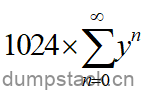 是收敛的,内核将该收敛值提前计算好,并记录在宏LOAD_AVG_MAX中,该值为47742。
是收敛的,内核将该收敛值提前计算好,并记录在宏LOAD_AVG_MAX中,该值为47742。
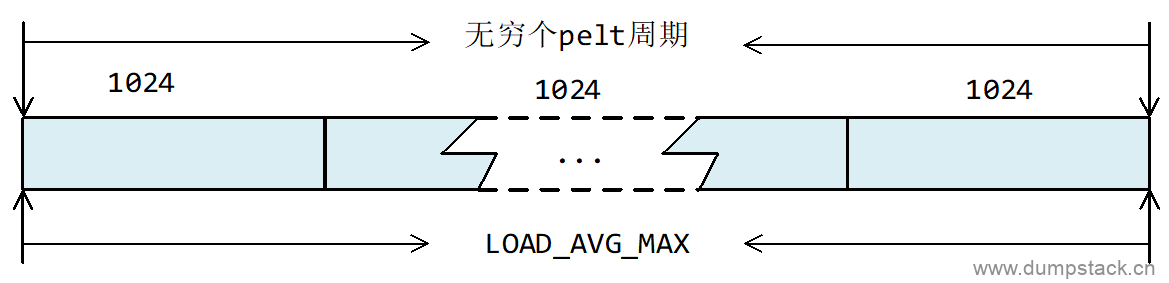
怎样理解LOAD_AVG_MAX这个值呢?LOAD_AVG_MAX表示一个task在连续运行无穷个完整的pelt周期(1024us)后,他对当前系统负载的贡献的最大值。如下图所示:
LOAD_AVG_MAX的值与科学计算的值有所偏差,原因是该值是通过程序计算出来的,存在取整与浮点运算的误差,LOAD_AVG_MAX值的计算程序如下,感兴趣的可以看一下。
|
void calc_converged_max(void) { int n = -1; long max = 1024; long last = 0, y_inv = ((1UL << 32) - 1) * y;
for (; ; n++) { if (n > -1) max = ((max * y_inv) >> 32) + 1024; /* * This is the same as: * max = max*y + 1024; */ if (last == max) break; last = max; } printf("#define LOAD_AVG_MAX %ld\n", max); } |
因此,式4可继续简化为:
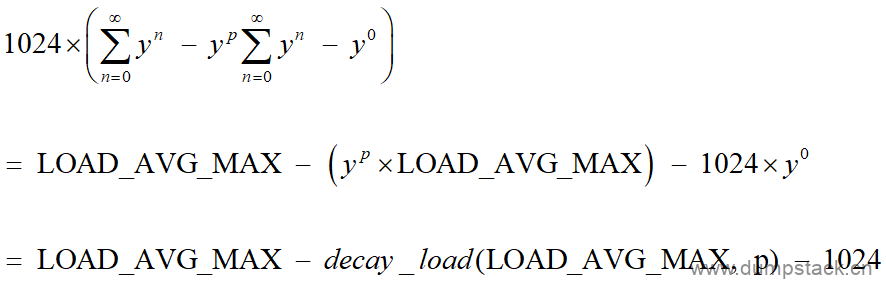 (式5)
(式5)
下面介绍各个公式的函数实现
3.4 decay_load(val, n) - 计算val*y^n
decay的英文翻译为"衰减",该函数实际上仅仅是完成数学公式val*y^n的计算,但是我们可以根据传进来的val值的不同,对该函数可有不同的理解:
-
当传进来的val表示时间时,表示一段时间val,在经历过n个周期后的功效
-
当传进来的val表示负载时,表示历史负载在经历过n个周期后,对当前系统负载的影响
由上面分析可知,使用PELT算法,计算一个task在过去连续n个周期的负载的公式如下
|
L = L0 + L1*y + L2*y^2 + L3*y^3 + ... + Ln*y^n |
从上面的计算公式我们也可以看出,经常需要计算val*y^n的值,这个值可以这样理解:即已知一个任务在n个周期之前的负载的贡献为val,计算这个val对当前系统负载的贡献。需要注意的是,这里是计算在第n个周期之后,该负载的贡献,而不是连续n个周期的贡献,连续n个周期的贡献则需要累加操作
内核提供decay_load函数用于计算第n个周期的衰减值,也就是计算val*y^n的值,为了避免浮点数运算,采用"乘法+移位"操作提高计算速度,decay_load(val, n)的计算结果如下,关于runnable_avg_yN_inv[]的推导过程,我们在上面已经分析过,此处不再赘述。
|
decay_load(val, n) = [val * (y^n * 2^32)] >> 32 = (val * runnable_avg_yN_inv[n]) >> 32 |
decay_load函数实现如下
|
/* * Approximate: * val * y^n, where y^32 ~= 0.5 (~1 scheduling period) */ static u64 decay_load(u64 val, u64 n) { unsigned int local_n;
//1.经过2016个周期后,负载的影响衰减为0 // 其中:#define LOAD_AVG_PERIOD 32 if (unlikely(n > LOAD_AVG_PERIOD * 63)) return 0;
/* after bounds checking we can collapse to 32-bit */ local_n = n;
/* * As y^PERIOD = 1/2, we can combine * y^n = 1/2^(n/PERIOD) * y^(n%PERIOD) * With a look-up table which covers y^n (n<PERIOD) * * To achieve constant time decay_load. */ //2.每经过32个周期,负载的影响衰减一半,牛逼的逻辑啊 if (unlikely(local_n >= LOAD_AVG_PERIOD)) { val >>= local_n / LOAD_AVG_PERIOD; local_n %= LOAD_AVG_PERIOD; }
//3.通过查表,计算在n个周期前负载的值val,对当前负载的贡献 // 这里只计算了一个任务的指定周期,(即n个周期之前,所有周期需要累加) val = mul_u64_u32_shr(val, runnable_avg_yN_inv[local_n], 32); return val; } |
3.5 __accumulate_pelt_segments - 计算式3
该函数是完成上面式3的计算,只计算d1+d2+d3阶段新增的负载的贡献,并没有加上历史负载的贡献
注意:
-
此时还没有考虑到历史负载贡献u的影响
-
该函数并没有传进来负载结构体sched_avg,是因为,pelt中的负载贡献,实际上就是时间,换句话说,负载贡献就是时间
一个pelt周期为1024us,即1ms
|
static u32 __accumulate_pelt_segments( u64 periods, //d2阶段,占几个pelt周期 u32 d1, //对应上图d1阶段,单位us u32 d3) //对应上图d3阶段,单位us { u32 c1, c2, c3 = d3; /* y^0 == 1 */
/* * c1 = d1 y^p */ //1.完成第一步d1*y^p的计算 c1 = decay_load((u64)d1, periods);
/* * p-1 * c2 = 1024 \Sum y^n * n=1 * * inf inf * = 1024 ( \Sum y^n - \Sum y^n - y^0 ) * n=0 n=p */ //2.完成上面式5的计算 c2 = LOAD_AVG_MAX - decay_load(LOAD_AVG_MAX, periods) - 1024;
//3.三个部分相加,得到式3 return c1 + c2 + c3; } |
3.6 accumulate_sum - 计算式1
考虑历史负载,加上新增负载,得到这个任务整个运行过程中总的负载
accumulate表示求和的意思,如果delta不足一个pelt周期,则返回0,注意,这里的delta并不是输入的参数delta,而是已经加上了上一次统计时不满足一个周期的部分。
|
/* * Accumulate the three separate parts of the sum; d1 the remainder * of the last (incomplete) period, d2 the span of full periods and d3 * the remainder of the (incomplete) current period. * * d1 d2 d3 * ^ ^ ^ * | | | * |<->|<----------------->|<--->| * ... |---x---|------| ... |------|-----x (now) * * p-1 * u' = (u + d1) y^p + 1024 \Sum y^n + d3 y^0 * n=1 * * = u y^p + (Step 1) * * p-1 * d1 y^p + 1024 \Sum y^n + d3 y^0 (Step 2) * n=1 */ static __always_inline u32 accumulate_sum( u64 delta, //在now到上一次更新时刻之间的时间差,单位us struct sched_avg *sa, //要更新的负载的数据结构 unsigned long load, //这三个参数暂且理解有下面两个含义,具体后面分析: unsigned long runnable, // a) 相当于一个开关 int running) // b) 作为一个缩放系数 { u32 contrib = (u32)delta; /* p == 0 -> delta < 1024 */ u64 periods;
//注意,这里的delta来源于rq->clock_pelt,已经是向最大核的最高频做scale处理后的值
//1.加上上一次计算负载的时候不足一个pelt周期的时间 // 加完后的delta就不再是上图中的delta了,而是delta+A部分 delta += sa->period_contrib;
//2.结合上一步的加操作,这里得到的periods实际上是d2之间有多少个完整的pelt周期 periods = delta / 1024; /* A period is 1024us (~1ms) */
/* * Step 1: decay old *_sum if we crossed period boundaries. */ //3.若periods不为0,表示距离上一次更新的时间已经过去了好几个完整的周期, // 这时候需要对"上一次"统计出来的负载做衰减 if (periods) { //3.1 对历史负载进行衰减 sa->load_sum = decay_load(sa->load_sum, periods); sa->runnable_sum = decay_load(sa->runnable_sum, periods); sa->util_sum = decay_load((u64)(sa->util_sum), periods);
/* * Step 2 */ //3.2 计算d1到d3之间新增负载 // 下面的delta值对应上图中的d3 delta %= 1024; if (load) { /* * This relies on the: * * if (!load) * runnable = running = 0; * * clause from ___update_load_sum(); this results in * the below usage of @contrib to dissapear entirely, * so no point in calculating it. */ contrib = __accumulate_pelt_segments(periods, 1024 - sa->period_contrib, delta); } } //4.更新period_contrib为本次不足pelt周期的部分, // 此时的delta实际上是上面d3所表示的部分 sa->period_contrib = delta;
//5.下面逻辑决定向谁做归一化 // load_avg: task的负载,是向权重做归一化,一个task的load_avg不会超过其权 // 重,这里传入的load一般为task的权重,cfs_rq时,传入的表示整个 // cfs_rq的权重 // runnable_sum: task的负载贡献,可理解为过去总共已经运行了多长时间了,当然, // 这个时间是经过衰减后的值,左移表示向1024做归一化;这里乘以 // 系数,task为1,cfs_rq表示task的个数,具体参见后面分析 // util_sum: task的负载,这个值是向1024做归一化后的值 if (load) sa->load_sum += load * contrib; if (runnable) sa->runnable_sum += runnable * contrib << SCHED_CAPACITY_SHIFT; if (running) sa->util_sum += contrib << SCHED_CAPACITY_SHIFT;
//6.返回d2之间占用几个完整的pelt周期,也就是完整的窗口的个数, // 用于指示后续的操作:只要存在完整pelt周期,就需要对过去的时间执行衰减操作 return periods; } |
3.7 ___update_load_sum - 更新{load|runnable|util}_sum
该函数完成下面两个重要工作:
-
对历史贡献进行衰减;
-
根据函数的传参,决定要更新哪些参数,并乘以相应的系数,这个系数实际就是决定了要向谁做归一化操作;
{load|runnable|util}_sum更新的最小周期为1us,{load|runnable|util}_avg更新的最小周期为1个pelt周期,即1ms,___update_load_sum函数返回值用于指示后面是否需要调用___update_load_sum完成对{load|runnable|util}_avg进行更新,具体如下:
-
当距离上一次更新不足1us时,该函数返回0,表示{load|runnable|util}_sum没有更新,后面也不需要对{load|runnable|util}_avg进行更新
-
当距离上一次更新不足1个pelt周期时,该函数也返回0,表示已经对{load|runnable|util}_sum进行更新,但是后面不需要对{load|runnable|util}_avg进行更新
-
当距离上一次更新超过一个pelt周期,则返回pelt周期个数,之后也需要对{load|runnable|util}_avg进行更新
___update_load_sum和___update_load_avg两者总是成对出现,传参很有讲究
load,runnable,running这三个参数有两个含义:
-
相当于一个开关,控制是否要更新对应的负载贡献
-
作为一个缩放系数,一方面因为不同的进程的重要性不同,运行相同的时间造成的负载也应该有所差异;另一方面对于task和group来说,同样是一个se在队列上等待了1ms,如果这个se表示一个group,则其下面有若干个task一起在队列上等待了1ms,那么其造成的压力应该是成倍的
|
/* * We can represent the historical contribution to runnable average as the * coefficients of a geometric series. To do this we sub-divide our runnable * history into segments of approximately 1ms (1024us); label the segment that * occurred N-ms ago p_N, with p_0 corresponding to the current period, e.g. * * [<- 1024us ->|<- 1024us ->|<- 1024us ->| ... * p0 p1 p2 * (now) (~1ms ago) (~2ms ago) * * Let u_i denote the fraction of p_i that the entity was runnable. * * We then designate the fractions u_i as our co-efficients, yielding the * following representation of historical load: * u_0 + u_1*y + u_2*y^2 + u_3*y^3 + ... * * We choose y based on the with of a reasonably scheduling period, fixing: * y^32 = 0.5 * * This means that the contribution to load ~32ms ago (u_32) will be weighted * approximately half as much as the contribution to load within the last ms * (u_0). * * When a period "rolls over" and we have new u_0`, multiplying the previous * sum again by y is sufficient to update: * load_avg = u_0` + y*(u_0 + u_1*y + u_2*y^2 + ... ) * = u_0 + u_1*y + u_2*y^2 + ... [re-labeling u_i --> u_{i+1}] */ static __always_inline int ___update_load_sum( u64 now, //当前时刻的时间戳,单位ns,不一定是1024ns边界对齐 struct sched_avg *sa, //要更新的负载的数据结构 unsigned long load, //这三个参数暂且理解有下面两个含义,具体后面分析: unsigned long runnable, // a) 相当于一个开关 int running) // b) 作为一个缩放系数 { u64 delta;
//注意:这里的now来源于rq->clock_pelt,也就是向最大核最高频做scale后的时间
//1.首先计算距上一次负载更新,已经过去了多少ns // 注意sa->last_update_time是1024ns边界对齐的, // 这一点可以从本函数下面的第4点看出 delta = now - sa->last_update_time;
/* * This should only happen when time goes backwards, which it * unfortunately does during sched clock init when we swap over to TSC. */ //2.该分支考虑了ns时钟溢出的情况,如果恰好溢出,我们不做更新 if ((s64)delta < 0) { sa->last_update_time = now; return 0; }
/* * Use 1024ns as the unit of measurement since it's a reasonable * approximation of 1us and fast to compute. */ //3.单位转换,ns -> us,不足一个1us不更新 // 如果距离上一次更新不足1us,则没必要进行负载更新,直接返回0 // 注意:这里先将单位转为us,在__update_load_avg的地方又转化回ns了 delta >>= 10; if (!delta) return 0;
//4.记录上一次更新的时间戳 // 因为sa->last_update_time的初值为0,因此该值一定是1024ns边界对齐的 sa->last_update_time += delta << 10;
/* * running is a subset of runnable (weight) so running can't be set if * runnable is clear. But there are some corner cases where the current * se has been already dequeued but cfs_rq->curr still points to it. * This means that weight will be 0 but not running for a sched_entity * but also for a cfs_rq if the latter becomes idle. As an example, * this happens during idle_balance() which calls * update_blocked_averages(). * * Also see the comment in accumulate_sum(). */ //5.下面这个处理表示,如果load=0,那么runnable/running也设置为0, // 即,若不统计load_sum,则其他两个值{runnable|util}_sum也都不统计 // load_sum被load控制,用于统计进程处于running+runnable状态时的负载 // runnable_sum被runnable控制,用于统计进程处于running+runnable状态的负载 // util_sum被running控制,用于统计进程处于running状态的负载 if (!load) runnable = running = 0;
/* * Now we know we crossed measurement unit boundaries. The *_avg * accrues by two steps: * * Step 1: accumulate *_sum since last_update_time. If we haven't * crossed period boundaries, finish. */ //6.更新{load|runnable|util}_sum // __update_load_sum和__update_load_avg总是成对出现,前者用于更新*_sum, // 后者用于更新*_avg,为了防止频繁更新带来的开销,我们这里需要一个返回值来控 // 制是否需要更新*_avg,accumlate_sum返回0表示sched_avg距离上一次更新不 // 足一个pelt周期,这时候函数返回0,表示这里我们只更新*_sum,*_avg暂时不 // 需要更新,也就是说,*_avg更新的最小粒度为1ms if (!accumulate_sum(delta, sa, load, runnable, running)) return 0;
//7.*_sum更新成功返回1,之后需要更新*_avg return 1; } |
3.8 ___update_load_avg - 更新{load|runnable|util}_avg
{load|runnable|util}_sum表示这个se在过去无穷个pelt周期中累积的负载贡献总和,{load|runnable|util}_avg相当于做了平均,表示这个se在整个生命周期中,每一个时刻的负载贡献
|
/* * When syncing *_avg with *_sum, we must take into account the current * position in the PELT segment otherwise the remaining part of the segment * will be considered as idle time whereas it's not yet elapsed and this will * generate unwanted oscillation in the range [1002..1024[. * * The max value of *_sum varies with the position in the time segment and is * equals to : * * LOAD_AVG_MAX*y + sa->period_contrib * * which can be simplified into: * * LOAD_AVG_MAX - 1024 + sa->period_contrib * * because LOAD_AVG_MAX*y == LOAD_AVG_MAX-1024 * * The same care must be taken when a sched entity is added, updated or * removed from a cfs_rq and we need to update sched_avg. Scheduler entities * and the cfs rq, to which they are attached, have the same position in the * time segment because they use the same clock. This means that we can use * the period_contrib of cfs_rq when updating the sched_avg of a sched_entity * if it's more convenient. */ static __always_inline void ___update_load_avg( struct sched_avg *sa, unsigned long load) //调度实体se的权重weight { //1.求负载贡献的极值 // 一个task连续运行无数个pelt周期,他的负载贡献都不会超过这个极限值 u32 divider = get_pelt_divider(sa);
/* * Step 2: update *_avg. */ //2.更新{load|runnable|util}_avg sa->load_avg = div_u64(load * sa->load_sum, divider); sa->runnable_avg = div_u64(sa->runnable_sum, divider); WRITE_ONCE(sa->util_avg, sa->util_sum / divider); } |
3.9 get_pelt_divider - 等比数列求和极限值
该函数返回:divider = LOAD_AVG_MAX - 1024 + sa->period_contrib
怎样理解这个值呢?我们已经知道LOAD_AVG_MAX的含义为:一个task在经历连续运行(或者仅仅是被挂在队列上)无穷个完整的pelt周期(1024us)后,他对当前系统负载的贡献的最大值。我们将上式的divider转化一下,会更容易看出他所表示的含义:
|
divider = LOAD_AVG_MAX - (1024 - sa->period_contrib) |
如下图所示,因为now不一定是在pelt周期边界对其,1024 - sa->period_contrib表示在当前的pelt周期里面,后面不满足一个pelt周期的部分,即图中B部分,确切的说,这部分还没有到来,该部分将会在下一次计算负载贡献的时候计算,所以我们需要将这部分从LOAD_AVG_MAX中扣除。
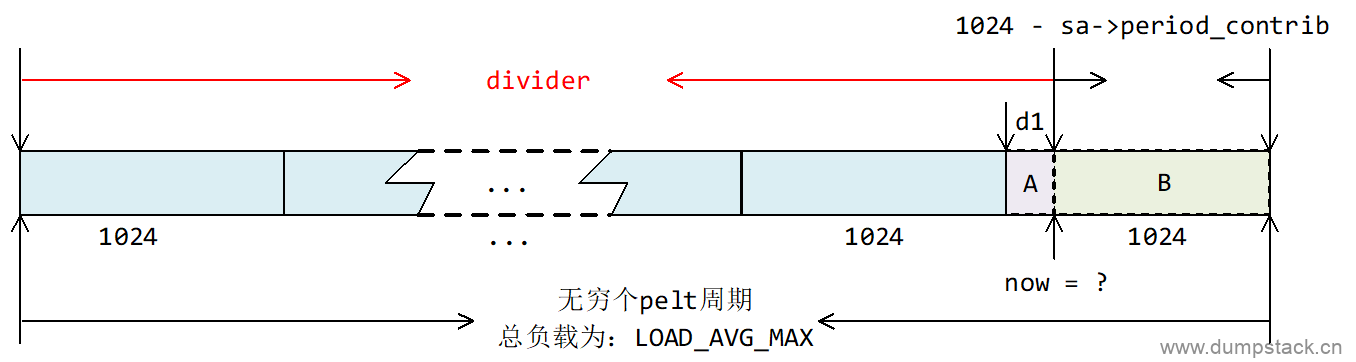
|
static inline u32 get_pelt_divider(struct sched_avg *avg) { //计算等比数列极值,不管一个task运行了少个pelt周期,其负载贡献都不可能超过这个值 return LOAD_AVG_MAX - 1024 + avg->period_contrib; } |
四、时间和权重
4.1 时钟rq->clock_pelt - 对齐到最大核最高频
在SMP系统中有大小核之分,同一个cpu上还有不同的频点,一个task同样是运行1ms的时间,其在大核上运行1ms和在小核上运行1ms,贡献肯定不一样;在同一个cpu上运行,cpu工作在1GHz和工作在3GHz,这个task的贡献也不一样
考虑到这个,内核提供了rq_clock_pelt时钟,将时间向最大核的最高频率做scale处理
4.1.1 update_rq_clock - 更新rq->clock,基于sched_clock
|
void update_rq_clock(struct rq *rq) { s64 delta;
lockdep_assert_held(&rq->lock);
if (rq->clock_update_flags & RQCF_ACT_SKIP) return;
#ifdef CONFIG_SCHED_DEBUG if (sched_feat(WARN_DOUBLE_CLOCK)) SCHED_WARN_ON(rq->clock_update_flags & RQCF_UPDATED); rq->clock_update_flags |= RQCF_UPDATED; #endif //1.rq->clock基于sched_clock delta = sched_clock_cpu(cpu_of(rq)) - rq->clock; if (delta < 0) return; rq->clock += delta;
//2.更新clock_task update_rq_clock_task(rq, delta); } |
4.1.2 update_rq_clock_task - clock_task只有在运行task的时候才更新
更新rq->clock_task的方法如下
|
static void update_rq_clock_task( struct rq *rq, s64 delta) //这个时间来源于rq->clock,未向最大核最高频做scale处理 { /* * In theory, the compile should just see 0 here, and optimize out the call * to sched_rt_avg_update. But I don't trust it... */ s64 __maybe_unused steal = 0, irq_delta = 0;
#ifdef CONFIG_IRQ_TIME_ACCOUNTING //1.得到在中断中的耗时 irq_delta = irq_time_read(cpu_of(rq)) - rq->prev_irq_time;
/* * Since irq_time is only updated on {soft,}irq_exit, we might run into * this case when a previous update_rq_clock() happened inside a * {soft,}irq region. * * When this happens, we stop ->clock_task and only update the * prev_irq_time stamp to account for the part that fit, so that a next * update will consume the rest. This ensures ->clock_task is * monotonic. * * It does however cause some slight miss-attribution of {soft,}irq * time, a more accurate solution would be to update the irq_time using * the current rq->clock timestamp, except that would require using * atomic ops. */ if (irq_delta > delta) irq_delta = delta;
rq->prev_irq_time += irq_delta;
//2.减去在中断中的耗时 delta -= irq_delta; #endif #ifdef CONFIG_PARAVIRT_TIME_ACCOUNTING if (static_key_false((¶virt_steal_rq_enabled))) { steal = paravirt_steal_clock(cpu_of(rq)); steal -= rq->prev_steal_time_rq;
if (unlikely(steal > delta)) steal = delta;
rq->prev_steal_time_rq += steal; delta -= steal; } #endif
//3.注意,rq->clock_task这个时间来源于rq->clock,不包括中断处理的时间 // 也就是说只有在有task运行时才会向前走,并且没有向最大核最高频做归一化 rq->clock_task += delta;
#ifdef CONFIG_HAVE_SCHED_AVG_IRQ if ((irq_delta + steal) && sched_feat(NONTASK_CAPACITY)) update_irq_load_avg(rq, irq_delta + steal); #endif //4.更新clock_pelt update_rq_clock_pelt(rq, delta); } |
4.1.3 update_rq_clock_pelt - clock_pelt基于clock_task,并且scale到最大核最高频
一个task在小核上某个频率运行了10ms,但是scale到最大核最高频后相当于运行1ms,这里的10ms就是rq->clock,而1ms就是rq->clock_pelt
|
/* * The clock_pelt scales the time to reflect the effective amount of * computation done during the running delta time but then sync back to * clock_task when rq is idle. * * * absolute time | 1| 2| 3| 4| 5| 6| 7| 8| 9|10|11|12|13|14|15|16 * @ max capacity ------******---------------******--------------- * @ half capacity ------************---------************--------- * clock pelt | 1| 2| 3| 4| 7| 8| 9| 10| 11|14|15|16 * */ static inline void update_rq_clock_pelt( struct rq *rq, s64 delta) //这里的delta来源于rq->clock_task { //已经扣除了在中断中的时间 //1.如果当前cpu进入idle,可以将clock_pelt同步到clock_task if (unlikely(is_idle_task(rq->curr))) { /* The rq is idle, we can sync to clock_task */ rq->clock_pelt = rq_clock_task(rq); return; }
/* * When a rq runs at a lower compute capacity, it will need * more time to do the same amount of work than at max * capacity. In order to be invariant, we scale the delta to * reflect how much work has been really done. * Running longer results in stealing idle time that will * disturb the load signal compared to max capacity. This * stolen idle time will be automatically reflected when the * rq will be idle and the clock will be synced with * rq_clock_task. */
/* * Scale the elapsed time to reflect the real amount of * computation */ //2.向最大核的最高频做归一化处理 // 第一步是向这个cpu的最高频做归一化处理 // 第二步是向最大核的最高频做归一化处理 delta = cap_scale(delta, arch_scale_cpu_capacity(cpu_of(rq))); delta = cap_scale(delta, arch_scale_freq_capacity(cpu_of(rq)));
//3.得到对齐后的时间 rq->clock_pelt += delta; } |
4.1.4 update_idle_rq_clock_pelt - 更新rq->lost_idle_time
|
/* * When rq becomes idle, we have to check if it has lost idle time * because it was fully busy. A rq is fully used when the /Sum util_sum * is greater or equal to: * (LOAD_AVG_MAX - 1024 + rq->cfs.avg.period_contrib) << SCHED_CAPACITY_SHIFT; * For optimization and computing rounding purpose, we don't take into account * the position in the current window (period_contrib) and we use the higher * bound of util_sum to decide. */ static inline void update_idle_rq_clock_pelt(struct rq *rq) { u32 divider = ((LOAD_AVG_MAX - 1024) << SCHED_CAPACITY_SHIFT) - LOAD_AVG_MAX;
//1.sum包括在运行cfs,rt,dl线程所消耗的时间 u32 util_sum = rq->cfs.avg.util_sum; util_sum += rq->avg_rt.util_sum; util_sum += rq->avg_dl.util_sum;
/* * Reflecting stolen time makes sense only if the idle * phase would be present at max capacity. As soon as the * utilization of a rq has reached the maximum value, it is * considered as an always runnig rq without idle time to * steal. This potential idle time is considered as lost in * this case. We keep track of this lost idle time compare to * rq's clock_task. */ //2.rq->clock_task只有在这个rq上有task在运行时,才会累加 if (util_sum >= divider) rq->lost_idle_time += rq_clock_task(rq) - rq->clock_pelt; } |
4.1.5 rq_clock_pelt - 负载跟踪时使用的时钟
这个接口获取到的时钟基于clock_pelt,负载跟踪就是基于这个时钟,有如下特性:
-
已经向最大核最高频做scale处理
-
仅在真正运行task的时候,该时钟才更新
-
不包含在中断中的时间
-
不包含在idle中的时间
|
static inline u64 rq_clock_pelt(struct rq *rq) { lockdep_assert_held(&rq->lock); assert_clock_updated(rq);
return rq->clock_pelt - rq->lost_idle_time; } |
4.2 se的权重和cfs_rq的关系
当se被加入/移出cfs_rq队列时,会同时将se的权重加入/移出cfs_rq的权重,所以,cfs_rq的权重可以看做是队列上所有se的权重之和,具体如下:
4.2.1 account_entity_dequeue - 将se的权重从cfs_rq中移除
调用关系:dequeue_entity -> account_entity_dequeue
|
static void account_entity_dequeue ( struct cfs_rq *cfs_rq, struct sched_entity *se) { //1.将se的权重从cfs_rq中移除 update_load_sub(&cfs_rq->load, se->load.weight); #ifdef CONFIG_SMP if (entity_is_task(se)) { account_numa_dequeue(rq_of(cfs_rq), task_of(se)); list_del_init(&se->group_node); } #endif //2.计数减1 cfs_rq->nr_running--; } |
4.1.2 account_entity_enqueue - 将se的权重累加进cfs_rq
调用关系:enqueue_entity -> account_entity_enqueue
|
static void account_entity_enqueue ( struct cfs_rq *cfs_rq, struct sched_entity *se) { //1.将se的权重累加进cfs_rq update_load_add(&cfs_rq->load, se->load.weight); #ifdef CONFIG_SMP if (entity_is_task(se)) { struct rq *rq = rq_of(cfs_rq);
account_numa_enqueue(rq, task_of(se)); list_add(&se->group_node, &rq->cfs_tasks); } #endif //2.计数加1 cfs_rq->nr_running++; } |
4.1.3 update_load_{add|sub|set} - 权重操作
当一个se被添加进或者移出cfs_rq时,会将其权重也从cfs_rq中移除
|
static inline void update_load_add(struct load_weight *lw, unsigned long inc) { lw->weight += inc; lw->inv_weight = 0; }
static inline void update_load_sub(struct load_weight *lw, unsigned long dec) { lw->weight -= dec; lw->inv_weight = 0; }
static inline void update_load_set(struct load_weight *lw, unsigned long w) { lw->weight = w; lw->inv_weight = 0; } |
五、更新se的负载
为了分析各种不同的负载的值,我在内核里面加了一些调试信息,patch和对应的log信息如下:


5.1 更新接口
5.1.1 __update_load_avg_se - 更新se的{load|runnable|util}_{avg|sum}
|
int __update_load_avg_se( u64 now, //时间来源于rq->clock_pelt,也就是向最大核最高频做scale后的值 struct cfs_rq *cfs_rq, struct sched_entity *se) { //1.更新{load|runnable|util}_sum if (___update_load_sum(now, &se->avg, !!se->on_rq, se_runnable(se), cfs_rq->curr == se)) {
//2.更新{load|runnable|util}_avg ___update_load_avg(&se->avg, se_weight(se));
//3.与sa->util_est成员有关,和cfs进程的利用率相关,暂不讨论 cfs_se_util_change(&se->avg);
//4.打印trace信息 trace_pelt_se_tp(se);
//5.成功更新负载返回1,未更新返回0 return 1; }
return 0; } |
5.2 参数含义
5.2.1 更新load_{sum|avg} - 向权重做归一化,和running+runnable时间有关
在更新load_{sum|avg}时,传入的参数分别为!!se->on_rq和se_weight(se),含义如下
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
!!se->on_rq:只有当这个se被挂在队列上,(处于running或runnable状态),才会带来新增的负载贡献,已经进入sleep或D状态se,因为其已经不在队列上,所以其在休眠期间经历的时间不会被累加进负载贡献,只对过去历史负载贡献进行衰减
-
se_weight(se):load_avg向这个se的权重做归一化。需要注意的是,当这个se表示一个group时,其权重表示这个group下所有se的权重之和。显然,同样是一个se在队列中等待了10ms,一个task和一个有100个task的group,两者造成的压力是不一样的
load_avg计算公式如下:
|
contrib load_avg = --------------------------------------------- * se_weight(se) LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,对历史贡献的衰减不受参数影响,而只有哪些被挂在队列上等待或者正在running的se才会考虑新增的贡献
|
if (se->on_rq) contrib = decay(history_contrib) + new_contrib else contrib = decay(history_contrib) |
因为上式的分子是始终小于分母的,所以一个se的load_avg是始终小于se_weight(se)的,并且随着这个se累计的运行时间(或挂在队列上的时间)越来越长,load_avg会越来越接近se_weight(se),即se的load_avg是向其权重做归一化
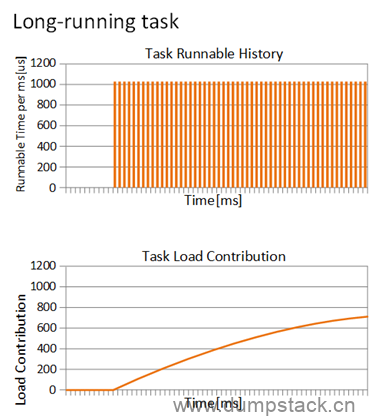
PS:下面摘自窝窝科技
例如,有一个权重为1024的进程长时间运行,其负载贡献曲线如下,上面的表格是进程运行的时间,下表是负载贡献曲线,从某一时刻进程开始运行,负载贡献就开始一直增加,然后稳定在一个值,即se_weight(se)。
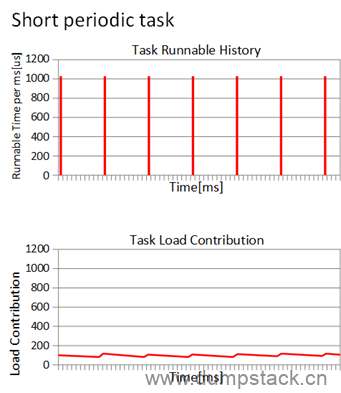
如果是一个周期运行的进程(每次运行1ms,睡眠9ms),那么负载贡献曲线图如何呢?
负载贡献的值基本维持在最小值和最大值两个峰值之间,这也符合我们的预期,我们认为负载就是反应进程运行的频繁程度。因此,基于PELT算法,我们在负载均衡的时候,可以更清楚的计算一个进程迁移到其他CPU的影响。
5.2.2 更新runnable_{sum|avg} - 向1024做归一化,和running+runnable时间有关,和权重无关
在更新runnable_{sum|avg}时,仅在调用___update_load_sum时传入参数se_runnable(se),调用___update_load_avg无需参数影响,参数se_runnable(se)含义如下:
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
对于task,se_runnable(se)值为!!se->on_rq,表示只有当这个se被挂在链表上时,(处于running或runnable状态),runnable_sum才会考虑新增的负载贡献,也就是说,如果这个task已经sleep或进D状态,runnable_sum是不会有新增的贡献的,只会对历史贡献进行衰减
-
对于group,se_runnable(se)值为se->my_q->h_nr_running,表示这个group下有多少个task,显然,同样是一个se在队列中等待了10ms,一个task和一个有100个task的group,两者造成的压力是不一样的
对于一个task来说,runnable_avg计算公式如下:
|
contrib runnable_avg = --------------------------------------------- * 1024 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中contrib如下,因为上式的分子是始终小于分母的,所以一个task的runnable_avg是始终小于1024的,并且随着这个task累计的运行时间(或挂在队列上的时间)越来越长,runnable_avg会越来越接近1024
|
if (se->on_rq) contrib = decay(history_contrib) + new_contrib else contrib = decay(history_contrib) |
对于一个group来说,runnable_avg计算公式如下:
|
contrib runnable_avg = --------------------------------------------- * 1024 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中contrib如下,需要注意的是,此时的contrib是有可能大于分母的,所以对于group来说,runnable_avg是有可能大于1024的
|
contrib = decay(history_contrib) + new_contrib * h_nr_running |
下面推导过程解释了为什么group的runnable_avg会大于1024
|
因为: contrib = decay(history_contrib) + new_contrib * h_nr_running <= (decay(history_contrib) + new_contrib) * h_nr_running
所以 contrib runnable_avg = --------------------------------------------- * 1024 LOAD_AVG_MAX - (1024 - sa->period_contrib)
(decay(history_contrib) + new_contrib) * h_nr_running <= ---------------------------------------------------------- * 1024 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
5.2.3 更新util_{sum|avg} - 向1024做归一化,仅和running时间有关,和权重无关
在更新util_{sum|avg}时,仅在调用___update_load_sum时传入参数为cfs_rq->curr == se,调用___update_load_avg无需参数影响,参数cfs_rq->curr == se含义如下:
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
只有当这个se正在处于running状态时,util_{sum|avg}才会有新增负载贡献,而哪些仅仅是挂在链表上等待运行的se,即处于runnable状态的se,util_{sum|avg}是不会增加的,只会衰减
-
需要注意的是:一个se在队列中等待了10ms,不管这个se表示一个task或是一个有100个task的group,两者的util_{sum|avg}是一样的
util_avg计算公式如下:
|
contrib util_avg = --------------------------------------------- * 1024 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,对历史贡献的衰减不受参数影响,而只有哪些正在运行的se才会考虑新增的贡献,仅仅是挂在链表上处于runnable状态的se不会新增负载贡献,仅会衰减
|
if (cfs_rq->curr == se) contrib = decay(history_contrib) + new_contrib else contrib = decay(history_contrib) |
不管这个se表示一个task或是group,上式的分子都是始终小于分母的,所以一个se的util_avg是始终小于1024的,并且随着这个task累计的运行时间越来越长,util_avg会越来越接近1024
需要注意的是:util_avg值和se的权重无关,仅和线程running时间有关
5.3 更新时机
负载更新时机如下图所示,但是我们目前只关注下面三个时机
-
enqueue_task_fair/dequeue_task_fair/enqueue_entity/dequeue_entity:
task从睡眠中退出或者即将进入睡眠时更新
-
set_next_entity/put_prev_entity:
task从runnable状态变为running,或者从running状态变为runnable时更新
-
entity_tick:
在tick中对命中的线程进行更新

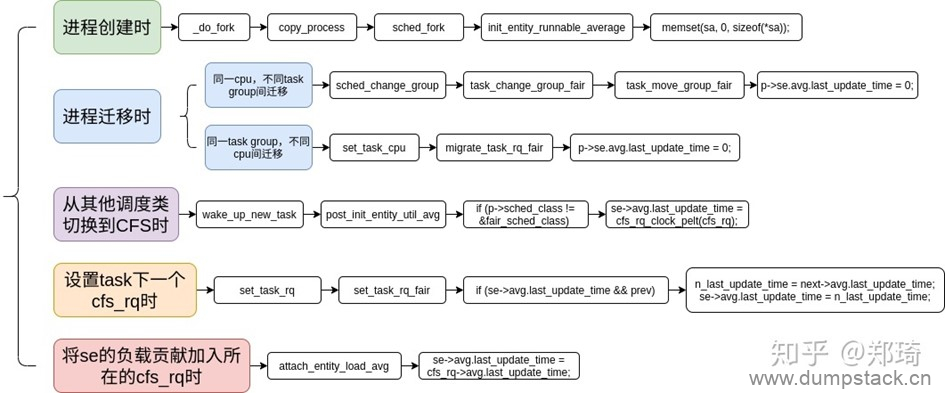
se上次更新的时间记录在se->avg.last_update_time中,该成员的赋值情况如下:
5.4 对外接口
5.4.1 task_util - 获取task的util值
|
static inline unsigned long task_util(struct task_struct *p) { return READ_ONCE(p->se.avg.util_avg); } |
5.5 init_entity_runnable_average - se的初始化对负载的赋值
一个调度实体se可能属于task,也有可能属于group,因此调度实体se的初始化针对tse和gse也就有所区别。调度实体se初始化函数是init_entity_runnable_average,代码如下
|
#ifdef CONFIG_SMP /* Give new sched_entity start runnable values to heavy its load in infant time */ void init_entity_runnable_average(struct sched_entity *se) { struct sched_avg *sa = &se->avg;
//1.注意,这里将所有成员清零,所有gse的所有负载信息全部清零 memset(sa, 0, sizeof(*sa));
/* * Tasks are initialized with full load to be seen as heavy tasks until * they get a chance to stabilize to their real load level. * Group entities are initialized with zero load to reflect the fact that * nothing has been attached to the task group yet. */ //2.当调度实体是一个task时,执行下面的if分支 // 侧面也说明,当se是一个group时,初始化的load_avg为0
// 如果这个se表示一个task,则load_avg被初始化为se的权重, // 这表示这个task被认为是一个重载task,(因为load_avg的最大值 // 就是se的权重),这样,进程被创建后就能立刻被调度到 // 如果这个se表示一个group,则load_avg初始化的值为0, // 这意味着这个group中没有任何task需要调度 if (entity_is_task(se)) sa->load_avg = scale_load_down(se->load.weight);
/* when this task enqueue'ed, it will contribute to its cfs_rq's load_avg */ } #else /* !CONFIG_SMP */ void init_entity_runnable_average(struct sched_entity *se) { } #endif |
5.6 用户空间查看se的负载信息
命令如下
|
OP5285:/ $ cat /proc/3808/task/3808/sched ndroid.launcher (3808, #threads: 66) ------------------------------------------------------------------- se.exec_start : 11632575.807018 se.vruntime : 20469.807223 se.sum_exec_runtime : 6715.492754 se.nr_migrations : 6017 se.statistics.sum_sleep_runtime : 11612296.141359 se.statistics.wait_start : 0.000000 se.statistics.sleep_start : 11642677.835913 se.statistics.block_start : 0.000000 se.statistics.sleep_max : 60050.469245 se.statistics.block_max : 33.051510 se.statistics.exec_max : 4.662500 se.statistics.slice_max : 2.255209 se.statistics.wait_max : 74.996094 se.statistics.wait_sum : 5056.303100 se.statistics.wait_count : 16167 se.statistics.iowait_sum : 115.568020 se.statistics.iowait_count : 88 se.statistics.nr_migrations_cold : 0 se.statistics.nr_failed_migrations_affine : 0 se.statistics.nr_failed_migrations_running : 9 se.statistics.nr_failed_migrations_hot : 5 se.statistics.nr_forced_migrations : 0 se.statistics.nr_wakeups : 9988 se.statistics.nr_wakeups_sync : 953 se.statistics.nr_wakeups_migrate : 3622 se.statistics.nr_wakeups_local : 1097 se.statistics.nr_wakeups_remote : 8891 se.statistics.nr_wakeups_affine : 0 se.statistics.nr_wakeups_affine_attempts : 0 se.statistics.nr_wakeups_passive : 0 se.statistics.nr_wakeups_idle : 0 avg_atom : 0.418567 avg_per_cpu : 1.116086 nr_switches : 16044 nr_voluntary_switches : 9987 nr_involuntary_switches : 6057 se.load.weight : 1048576 se.avg.load_sum : 601 se.avg.runnable_sum : 615844 se.avg.util_sum : 191530 se.avg.load_avg : 10 se.avg.runnable_avg : 10 se.avg.util_avg : 1 se.avg.last_update_time : 11627031569424 se.avg.util_est.ewma : 17 se.avg.util_est.enqueued : 4 uclamp.min : 0 uclamp.max : 1024 effective uclamp.min : 0 effective uclamp.max : 1024 policy : 0 prio : 120 clock-delta : 105 OP5285:/ $ |
六、更新blocked_se的负载
6.1 更新接口
6.1.1 __update_load_avg_blocked_se - 更新blocked_se的{load|runnable|util}_{avg|sum}
已经block的se,已经不再挂在cfs_rq链表上了,此时不考虑新增的周期带来的负载,因为此时任务已经不运行了,只考虑历史负载的衰减
|
int __update_load_avg_blocked_se(u64 now, struct sched_entity *se) { //1.更新{load|runnable|util}_sum // 对已经block的se,仅对历史负载进行衰减,不记录新增的时间内产生 // 的负载贡献。因为此时task都已经进入D状态,不运行啦 if (___update_load_sum(now, &se->avg, 0, 0, 0)) {
//2.更新{load|runnable|util}_avg // 在计算load_avg的时候,需要对新增的负载贡献乘以权重 ___update_load_avg(&se->avg, se_weight(se));
//3.打印trace信息 trace_pelt_se_tp(se);
//4.成功更新返回1,未更新返回0 return 1; }
return 0; } |
6.2 参数含义
6.2.1 更新load_{sum|avg} - 向权重做归一化,对历史负载进行衰减,无新增负载贡献
在更新load_{sum|avg}时,传入的参数分别为0和se_weight(se),含义如下
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
0:因为这个se已经处于blocked状态,不会带来新增的负载贡献,只会对历史负载贡献进行衰减
-
se_weight(se):load_avg向这个se的权重做归一化。需要注意的是,当这个se表示一个group时,其权重表示这个group下所有se的权重之和。显然,同样是一个se在队列中等待了10ms,一个task和一个有100个task的group,两者造成的压力是不一样的
load_avg计算公式如下:
|
contrib load_avg = --------------------------------------------- * se_weight(se) LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,对于已经blocked的se,没有新增的负载贡献,只对历史负载贡献进行衰减。
|
contrib = decay(history_contrib) |
因为上式的分子是始终小于分母的,所以一个bloacked_se的load_avg是始终小于se_weight(se)的,并且随着这个bloacked_se阻塞的时间越来越长,load_avg会越来越小
6.2.2 更新runnable_{sum|avg} - 向1024做归一化,对历史负载进行衰减,无新增负载贡献,和权重无关
在更新runnable_{sum|avg}时,仅在调用___update_load_sum时传入参数0,调用___update_load_avg无需参数影响,含义如下:
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
0:因为这个se已经处于blocked状态,不会带来新增的负载贡献,只会对历史负载贡献进行衰减
runnable_avg计算公式如下:
|
contrib runnable_avg = --------------------------------------------- * 1024 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,对于已经blocked的se,没有新增的负载贡献,只对历史负载贡献进行衰减。
|
contrib = decay(history_contrib) |
因为上式的分子是始终小于分母的,所以一个bloacked_se的runnable_avg是始终小于1024的,并且随着这个bloacked_se阻塞的时间越来越长,runnable_avg会越来越小
6.2.3 更新util_{sum|avg} - 向1024做归一化,对历史负载进行衰减,无新增负载贡献,和权重无关
在更新util_{sum|avg}时,仅在调用___update_load_sum时传入参数为0,调用___update_load_avg无需参数影响,参数含义如下:
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
0:因为这个se已经处于blocked状态,不会带来新增的负载贡献,只会对历史负载贡献进行衰减
util_avg计算公式如下:
|
contrib util_avg = --------------------------------------------- * 1024 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,对于已经blocked的se,没有新增的负载贡献,只对历史负载贡献进行衰减。
|
contrib = decay(history_contrib) |
因为上式的分子是始终小于分母的,所以一个bloacked_se的util_avg是始终小于1024的,并且随着这个bloacked_se阻塞的时间越来越长,util_avg会越来越小
6.3 更新时机
待补充。。。
6.4 对外接口
通过task_util获取,不再赘述
七、更新cfs_rq队列的负载
7.1 更新接口
7.1.1 __update_load_avg_cfs_rq - 更新cfs_rq的{load|runnable|util}_{avg|sum}
注意下面几点:
cfs_rq的权重是指cfs就绪队列上所有就绪态调度实体权重之和
cfs_rq平均负载贡献是指所有调度实体平均负载之和
在每次更新se的负载信息时,也会同步更新se依附的cfs就绪队列负载信息
|
int __update_load_avg_cfs_rq(u64 now, struct cfs_rq *cfs_rq) { //1.更新{load|runnable|util}_sum if (___update_load_sum(now, &cfs_rq->avg, scale_load_down(cfs_rq->load.weight), cfs_rq->h_nr_running, cfs_rq->curr != NULL)) {
//2.更新{load|runnable|util}_avg,注意传入的参数为1 ___update_load_avg(&cfs_rq->avg, 1);
//3.打印trace信息 trace_pelt_cfs_tp(cfs_rq);
//4.成功更新返回1,未更新返回0 return 1; }
return 0; } |
7.1.2 update_cfs_rq_load_avg - 更新cfs_rq的负载信息
这里有个removed机制,简单了解一下:当线程迁移或者dead时,因为没有持有rq_lock锁,所有并不会将这个se的负载信息立刻从cfs_rq中扣除,而是将将这些要removed的task的负载信息累加到cfs_rq的removed成员中,等待下一次更新这个cfs_rq的负载信息时,再将removed中累加的负载信息从cfs_rq中扣除。具体实现逻辑请参见update_cfs_rq_load_avg和remove_entity_load_avg的实现,引入的patch如下:

返回值:当cfs_rq的负载发生变化,函数返回true
|
/** * update_cfs_rq_load_avg - update the cfs_rq's load/util averages * @now: current time, as per cfs_rq_clock_pelt() * @cfs_rq: cfs_rq to update * * The cfs_rq avg is the direct sum of all its entities (blocked and runnable) * avg. The immediate corollary is that all (fair) tasks must be attached, see * post_init_entity_util_avg(). * * cfs_rq->avg is used for task_h_load() and update_cfs_share() for example. * * Returns true if the load decayed or we removed load. * * Since both these conditions indicate a changed cfs_rq->avg.load we should * call update_tg_load_avg() when this function returns true. */ static inline int update_cfs_rq_load_avg( u64 now, struct cfs_rq *cfs_rq) { unsigned long removed_load = 0, removed_util = 0, removed_runnable = 0; struct sched_avg *sa = &cfs_rq->avg; int decayed = 0;
//1.nr表示这个removed成员中已经累积了几个task的负载信息 if (cfs_rq->removed.nr) { unsigned long r; u32 divider = get_pelt_divider(&cfs_rq->avg);
//2.取出哪些已经被removed的负载信息,并清零 raw_spin_lock(&cfs_rq->removed.lock); swap(cfs_rq->removed.util_avg, removed_util); swap(cfs_rq->removed.load_avg, removed_load); swap(cfs_rq->removed.runnable_avg, removed_runnable); cfs_rq->removed.nr = 0; raw_spin_unlock(&cfs_rq->removed.lock);
//3.直接将removed累积的负载信息从cfs_rq中扣除 // 注意下面更新*_sum负载信息的方式, r = removed_load; sub_positive(&sa->load_avg, r); sa->load_sum = sa->load_avg * divider;
r = removed_util; sub_positive(&sa->util_avg, r); sa->util_sum = sa->util_avg * divider;
r = removed_runnable; sub_positive(&sa->runnable_avg, r); sa->runnable_sum = sa->runnable_avg * divider;
/* * removed_runnable is the unweighted version of removed_load so we * can use it to estimate removed_load_sum. */ add_tg_cfs_propagate(cfs_rq, -(long)(removed_runnable * divider) >> SCHED_CAPACITY_SHIFT);
decayed = 1; }
//4.最主要是这里的更新cfs_rq的负载信息 decayed |= __update_load_avg_cfs_rq(now, cfs_rq);
#ifndef CONFIG_64BIT smp_wmb(); cfs_rq->load_last_update_time_copy = sa->last_update_time; #endif
return decayed; } |
7.1.3 remove_entity_load_avg
将要移除的se的负载信息先保存进一个removed成员里面,等到更新cfs_rq的负载时,再将其从cfs_rq的负载信息中扣除
|
/* * Task first catches up with cfs_rq, and then subtract * itself from the cfs_rq (task must be off the queue now). */ static void remove_entity_load_avg(struct sched_entity *se) { struct cfs_rq *cfs_rq = cfs_rq_of(se); unsigned long flags;
/* * tasks cannot exit without having gone through wake_up_new_task() -> * post_init_entity_util_avg() which will have added things to the * cfs_rq, so we can remove unconditionally. */
sync_entity_load_avg(se);
raw_spin_lock_irqsave(&cfs_rq->removed.lock, flags); ++cfs_rq->removed.nr; cfs_rq->removed.util_avg += se->avg.util_avg; cfs_rq->removed.load_avg += se->avg.load_avg; cfs_rq->removed.runnable_avg += se->avg.runnable_avg; raw_spin_unlock_irqrestore(&cfs_rq->removed.lock, flags); } |
7.2 参数说明
7.2.1 更新load_{sum|avg} - 向cfs_rq的权重做归一化
在更新load_{sum|avg}时,传入的参数分别为cfs_rq->load.weight和1,含义如下
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
cfs_rq->load.weight:这个cfs_rq的权重,也就是这个cfs_rq上所有task的权重
-
1:因为在调用__update_load_sum的时候,已经乘以cfs_rq->load.weight,这里传入1,表示cfs_rq的load_avg已经向cfs_rq->load.weight做了归一化处理
load_avg计算公式如下:
|
contrib load_avg = --------------------------------------------- * 1 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,当cfs_rq->load.weight不为0的时候,表示这个cfs_rq上存在等待调度的task,为0则表示这个cfs_rq上已经没有task了
|
if (cfs_rq->load.weight) contrib = decay(history_contrib) + new_contrib * cfs_rq->load.weight else contrib = decay(history_contrib) |
注意到
|
contrib = decay(history_contrib) + new_contrib * cfs_rq->load.weight <= (decay(history_contrib) + new_contrib) * cfs_rq->load.weight |
所以有
|
contrib load_avg = --------------------------------------------- * 1 LOAD_AVG_MAX - (1024 - sa->period_contrib)
(decay(history_contrib) + new_contrib) * cfs_rq->load.weight <= ---------------------------------------------------------------- LOAD_AVG_MAX - (1024 - sa->period_contrib)
(decay(history_contrib) + new_contrib) = --------------------------------------------- * cfs_rq->load.weight LOAD_AVG_MAX - (1024 - sa->period_contrib) |
因为负载贡献(decay(history_contrib) + new_contrib)是一定小于LOAD_AVG_MAX - (1024 - sa->period_contrib)的,所以cfs_rq的load_avg是永远不会大于的cfs_rq->load.weight,所以可理解cfs_rq的load_avg是向cfs_rq->load.weight做归一化
7.2.2 更新runnable_{sum|avg} - 可能大于1024,和权重无关
在更新runnable_{sum|avg}时,仅在调用___update_load_sum时传入参数cfs_rq->h_nr_running,调用___update_load_avg无需参数影响,含义如下:
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
cfs_rq->h_nr_running:这个cfs_rq上等待运行的task个数,包括子group里面的task,一个task等待10ms和100个task等10ms,造成的压力肯定是不一样的
runnable_avg计算公式如下:
|
contrib runnable_avg = --------------------------------------------- * 1024 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,只要这个cfs_rq上有等待运行的task,就会有新增的负载信息,并且,一个task等待10ms和100个task等10ms,带来的负载贡献也是不一样的
|
if (cfs_rq->h_nr_running) contrib = decay(history_contrib) + new_contrib * cfs_rq->h_nr_running else contrib = decay(history_contrib) |
由上式可知,cfs_rq的runnable_avg是有可能大于1024的
7.2.3 更新util_{sum|avg} - 向1024做归一化,仅和running时间有关,和权重无关
在更新util_{sum|avg}时,仅在调用___update_load_sum时传入参数为cfs_rq->curr != NULL,调用___update_load_avg无需参数影响,参数含义如下:
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
cfs_rq->curr != NULL:表示该cfs_rq上目前是否有正在运行的task
util_avg计算公式如下:
|
contrib util_avg = --------------------------------------------- * 1024 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,如果这个cfs_rq上没有任何一个task在运行,则不会带来新的负载贡献,只对历史负载贡献进行衰减即可
|
if (cfs_rq->curr != NULL) contrib = decay(history_contrib) + new_contrib else contrib = decay(history_contrib) |
因为上式的分子是始终小于分母的,所以一个cfs_rq的util_avg是始终小于1024的,并且随着这个cfs_rq运行的时间越来越长,util_avg会越来越接近1024
7.3 更新时机
由下图可知,对cfs_rq的负载信息的更新,和se的负载的更新是在同一个时机,都是在update_load_avg中,具体如下,目前只关注下面三个时机
-
enqueue_task_fair/dequeue_task_fair/enqueue_entity/dequeue_entity:
task从睡眠中退出或者即将进入睡眠时更新
这里有一个细节需要注意:一个task在cfs_rq上已经运行一段时间,其对cfs_rq已经造成了一定的压力,但是当这个task睡眠进D状态时,虽然这个task的权重会从这个cfs_rq上扣除(util_est也会被扣除),但是这个task的历史负载贡献并不会从这个cfs_rq上删除,而是继续保留在cfs_rq上随着时间的推移衰减,这一点可以从dequeue_entity实现上看出,具体下面分析
-
set_next_entity/put_prev_entity:
task从runnable状态变为running,或者从running状态变为runnable时更新
-
entity_tick:
在tick中对命中的线程进行更新
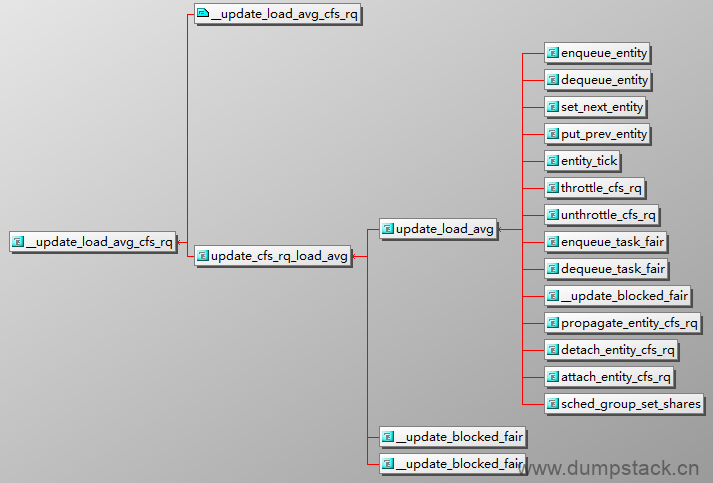
7.4 对外接口
7.4.1 cfs_rq_load_avg
|
static inline unsigned long cfs_rq_load_avg(struct cfs_rq *cfs_rq) { return cfs_rq->avg.load_avg; } |
7.4.2 cfs_rq_runnable_avg
|
static inline unsigned long cfs_rq_runnable_avg(struct cfs_rq *cfs_rq) { return cfs_rq->avg.runnable_avg; } |
7.4.3 cpu_runnable
|
static unsigned long cpu_runnable(struct rq *rq) { return cfs_rq_runnable_avg(&rq->cfs); } |
八、更新rt_rq队列的负载,记录在rq结构中:rq->avg_rt
8.1 更新接口
8.1.1 update_rt_rq_load_avg
|
/* * rt_rq: * * util_sum = \Sum se->avg.util_sum but se->avg.util_sum is not tracked * util_sum = cpu_scale * load_sum * runnable_sum = util_sum * * load_avg and runnable_avg are not supported and meaningless. * */
int update_rt_rq_load_avg( u64 now, struct rq *rq, int running) //标记当前正在运行的任务是否为rt { if (___update_load_sum(now, &rq->avg_rt, running, running, running)) {
___update_load_avg(&rq->avg_rt, 1); trace_pelt_rt_tp(rq); return 1; }
return 0; } |
8.2 参数说明
注意:对于rt_rq来说,runnable_avg和util_avg是相等的,load_avg始终小于0
8.2.1 更新load_{sum|avg} - 始终小于1
在更新load_{sum|avg}时,传入的参数分别为running和1,running标记当前运行的线程是不是rt的,含义如下
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
running:标记这个rq上当前正在运行的线程是不是rt的,例如put_prev_task_rt时,因为可以确定上一个运行的就是rt线程,所以此时传递的running为1,而在set_next_task_rt中,虽然下一个要运行的线程为rt,但是却不能确定上一个prev是不是rt的,所以还要判断,具体参见后面的参对外接口章节
load_avg计算公式如下:
|
contrib load_avg = --------------------------------------------- * 1 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,对历史贡献的衰减不受参数影响,而只有当rq->curr是rt时,才会考虑新增的贡献。
|
if (is_rt(rq->curr)) contrib = decay(history_contrib) + new_contrib else contrib = decay(history_contrib) |
因为上式的分子是始终小于分母的,所以rt_rq的load_avg是始终小于1的,如果你把它打印出来,会发现全是0
8.2.2 更新runnable_{sum|avg} - 向1024做归一化
在更新runnable_{sum|avg}时,仅在调用___update_load_sum时传入参数running,调用___update_load_avg无需参数影响,含义如下:
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
running:标记这个rq上当前正在运行的线程是不是rt的,例如put_prev_task_rt时,因为可以确定上一个运行的就是rt线程,所以此时传递的running为1,而在set_next_task_rt中,虽然下一个要运行的线程为rt,但是却不能确定上一个prev是不是rt的,所以还要判断,具体参见后面的参对外接口章节
runnable_avg计算公式如下:
|
contrib runnable_avg = --------------------------------------------- * 1024 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,对历史贡献的衰减不受参数影响,而只有当rq->curr是rt时,才会考虑新增的贡献。
|
if (is_rt(rq->curr)) contrib = decay(history_contrib) + new_contrib else contrib = decay(history_contrib) |
因为上式的分子是始终小于分母的,所以rt_rq的runnable_avg是向1024归一化,该值始终小于1024
8.2.3 更新util_{sum|avg} - 向1024做归一化
在更新util_{sum|avg}时,仅在调用___update_load_sum时传入参数为running,调用___update_load_avg无需参数影响,参数running含义如下:
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
running:标记这个rq上当前正在运行的线程是不是rt的,例如put_prev_task_rt时,因为可以确定上一个运行的就是rt线程,所以此时传递的running为1,而在set_next_task_rt中,虽然下一个要运行的线程为rt,但是却不能确定上一个prev是不是rt的,所以还要判断,具体参见后面的参对外接口章节
util_avg计算公式如下:
|
contrib util_avg = --------------------------------------------- * 1024 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,对历史贡献的衰减不受参数影响,而只有当rq->curr是rt时,才会考虑新增的贡献。
|
if (is_rt(rq->curr)) contrib = decay(history_contrib) + new_contrib else contrib = decay(history_contrib) |
因为上式的分子是始终小于分母的,所以rt_rq的util_avg是向1024归一化,该值始终小于1024
8.3 更新时机
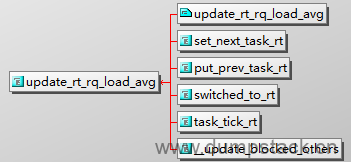
8.3.1 set_next_task_rt
从一个线程(这个线程可能是rt,也可能是非rt的),切到一个rt线程时会调用该这个函数
|
static inline void set_next_task_rt( struct rq *rq, struct task_struct *p, //下一个要运行的rt线程 bool first) { ...
/* * If prev task was rt, put_prev_task() has already updated the * utilization. We only care of the case where we start to schedule a * rt task */ //1.p是下一个被pick出来即将被运行的rt线程,但是无法确定上一次运行的线程是不是rt, // 也就是说无法确定刚刚逝去的那段时间是不是在运行rt线程,因此要做判断 // 满足下面条件,表示prev并不是一个rt线程,也就是说刚刚逝去的那段时间是在运行一 // 个非rt的线程,这时候我们只需要在这里对rt_rq的原有负载信息进行衰减,不用考虑新 // 增的负载贡献,如果当前运行的线程是rt的怎么办呢?由上面的分析可知,由rt切到rt // 线程,负载贡献在put_prev_task中就完成更新了,在这里不需要重复更新了 if (rq->curr->sched_class != &rt_sched_class) update_rt_rq_load_avg(rq_clock_pelt(rq), rq, 0);
... } |
8.3.2 put_prev_task_rt
当一个rt线程运行完毕,被重新放回队列时,会调用到这里
|
static void put_prev_task_rt(struct rq *rq, struct task_struct *p) { ...
//1.一个rt线程运行结束后,释放cpu使用权,重新挂回对应的rt链表时,会调用这个函数 // 因为刚刚逝去的那段时间是在运行rt线程,所以我们需要将这段逝去时间带来的负载贡献 // 累加到rt_rq的负载信息上,所以下面参数传入1 update_rt_rq_load_avg(rq_clock_pelt(rq), rq, 1);
... } |
8.3.4 task_tick_rt
在tick中断中正好命中的是rt线程时,执行下面函数
|
/* * scheduler tick hitting a task of our scheduling class. * * NOTE: This function can be called remotely by the tick offload that * goes along full dynticks. Therefore no local assumption can be made * and everything must be accessed through the @rq and @curr passed in * parameters. */ static void task_tick_rt(struct rq *rq, struct task_struct *p, int queued) { ... //1.命中的线程正是rt,说明刚刚逝去的那段时间是在运行rt线程, // 此时不仅要对旧的负载贡献进行衰减,还要记录新的负载贡献 update_rt_rq_load_avg(rq_clock_pelt(rq), rq, 1); ... } |
8.3.3 switched_to_rt
当从其他调度类切换到rt调度类时,会调用到该函数,具体对应下面两个场景:
-
一个非rt线程,(例如cfs线程),用户空间通过系统调用的方式将其设置为rt线程时
-
rt_mutex中,rt线程在申请锁的时候,发现这把锁已经被非rt线程持有,考虑到优先级翻转的问题,内核会把这个非rt线程临时修改为rt线程
|
/* * When switching a task to RT, we may overload the runqueue * with RT tasks. In this case we try to push them off to * other runqueues. */ static void switched_to_rt( struct rq *rq, struct task_struct *p) //即将切换到的rt线程 { /* * If we are running, update the avg_rt tracking, as the running time * will now on be accounted into the latter. */ //1.判断rq->curr是否就是p,如果满足这个条件,则说明p刚从一个非rt // 属性切换到rt,也就是说刚刚逝去的那段时间实际上是在执行非rt线程, // 这时候需要对rt_rq的负载贡献进行衰减 if (task_current(rq, p)) { update_rt_rq_load_avg(rq_clock_pelt(rq), rq, 0); return; }
... } |
上面switched_to_rt在core层调用的位置如下,check_class_changed的作用是修改某个线程所属的调度类,例如从cfs切到rt,或者从rt切到cfs
|
/* * switched_from, switched_to and prio_changed must _NOT_ drop rq->lock, * use the balance_callback list if you want balancing. * * this means any call to check_class_changed() must be followed by a call to * balance_callback(). */ static inline void check_class_changed ( struct rq *rq, struct task_struct *p, //要切换调度类的线程 const struct sched_class *prev_class, //上一次所属的调度类 int oldprio) { //调度类发送切换就执行下面的分支,分别执行一次switched_from和switched_to if (prev_class != p->sched_class) { if (prev_class->switched_from) prev_class->switched_from(rq, p);
p->sched_class->switched_to(rq, p); } else if (oldprio != p->prio || dl_task(p)) p->sched_class->prio_changed(rq, p, oldprio); } |
那么什么时候会调用check_class_changed呢?如下,可见只有下面两个场景会修改,具体逻辑这里不展开了
-
一个非rt线程,(例如cfs线程),用户空间通过系统调用的方式将其设置为rt线程时
-
rt_mutex中,rt线程在申请锁的时候,发现这把锁已经被非rt线程持有,考虑到优先级翻转的问题,内核会把这个非rt线程临时修改为rt线程
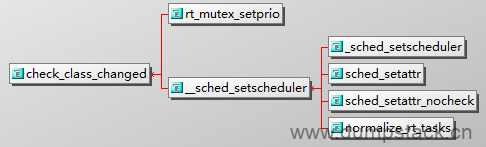
8.4 对外接口
8.4.1 cpu_util_rt - 获取cpu在中断中的负载
|
static inline unsigned long cpu_util_rt(struct rq *rq) { return READ_ONCE(rq->avg_rt.util_avg); } |
九、更新dl_rq队列的负载,记录在rq结构中:rq->avg_dl
9.1 更新接口
9.1.1 update_dl_rq_load_avg
|
/* * dl_rq: * * util_sum = \Sum se->avg.util_sum but se->avg.util_sum is not tracked * util_sum = cpu_scale * load_sum * runnable_sum = util_sum * * load_avg and runnable_avg are not supported and meaningless. * */
int update_dl_rq_load_avg( u64 now, struct rq *rq, int running) //标记当前rq上运行的线程是不是dl的 { if (___update_load_sum(now, &rq->avg_dl, running, running, running)) {
___update_load_avg(&rq->avg_dl, 1); trace_pelt_dl_tp(rq); return 1; }
return 0; } |
9.2 参数说明
9.2.1 更新load_{sum|avg} - 始终小于1
在更新load_{sum|avg}时,传入的参数分别为running和1,含义如下
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
running:标记这个rq上当前正在运行的线程是不是dl的,例如put_prev_task_dl时,因为可以确定上一个运行的就是dl线程,所以此时传递的running为1,而在set_next_task_dl中,虽然下一个要运行的线程为dl,但是却不能确定上一个prev是不是dl的,所以还要判断,具体参见后面的参对外接口章节
load_avg计算公式如下:
|
contrib load_avg = --------------------------------------------- LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,对历史贡献的衰减不受参数影响,而只有当rq->curr是dl时,才会考虑新增的贡献
|
if (is_dl(rq->curr)) contrib = decay(history_contrib) + new_contrib else contrib = decay(history_contrib) |
因为上式的分子是始终小于分母的,所以dl_rq的load_avg是始终小于1的,如果你把它打印出来,会发现全是0
9.2.2 更新runnable_{sum|avg} - 向1024做归一化
在更新runnable_{sum|avg}时,仅在调用___update_load_sum时传入参数running,调用___update_load_avg无需参数影响,含义如下:
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
running:标记这个rq上当前正在运行的线程是不是dl的,例如put_prev_task_dl时,因为可以确定上一个运行的就是dl线程,所以此时传递的running为1,而在set_next_task_dl中,虽然下一个要运行的线程为dl,但是却不能确定上一个prev是不是dl的,所以还要判断,具体参见后面的参对外接口章节
runnable_avg计算公式如下:
|
contrib runnable_avg = --------------------------------------------- * 1024 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,对历史贡献的衰减不受参数影响,而只有当rq->curr是dl时,才会考虑新增的贡献
|
if (is_dl(rq->curr)) contrib = decay(history_contrib) + new_contrib else contrib = decay(history_contrib) |
因为上式的分子是始终小于分母的,所以dl_rq的runnable_avg是向1024归一化,该值始终小于1024
9.2.3 更新util_{sum|avg} - 向1024做归一化
在更新util_{sum|avg}时,仅在调用___update_load_sum时传入参数为running,调用___update_load_avg无需参数影响,参数running含义如下:
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
running:标记这个rq上当前正在运行的线程是不是dl的,例如put_prev_task_dl时,因为可以确定上一个运行的就是dl线程,所以此时传递的running为1,而在set_next_task_dl中,虽然下一个要运行的线程为dl,但是却不能确定上一个prev是不是dl的,所以还要判断,具体参见后面的参对外接口章节
util_avg计算公式如下:
|
contrib util_avg = --------------------------------------------- * 1024 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,对历史贡献的衰减不受参数影响,而只有当rq->curr是dl时,才会考虑新增的贡献
|
if (is_dl(rq->curr)) contrib = decay(history_contrib) + new_contrib else contrib = decay(history_contrib) |
因为上式的分子是始终小于分母的,所以dl_rq的util_avg是向1024归一化,该值始终小于1024
9.3 更新时机
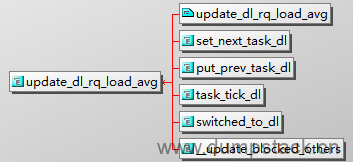
9.3.1 set_next_task_dl
从一个线程(这个线程可能是dl,也可能是非dl)切换到dl运行时,会调用该函数
|
static void set_next_task_dl(struct rq *rq, struct task_struct *p, bool first) { ... //判断上一次运行的线程是不是dl的,如果不是dl的则需要进行衰减 if (rq->curr->sched_class != &dl_sched_class) update_dl_rq_load_avg(rq_clock_pelt(rq), rq, 0); ... } |
9.3.2 put_prev_task_dl
刚运行完一个dl线程,需要将其重新放回队列时,调用该函数
|
static void put_prev_task_dl(struct rq *rq, struct task_struct *p) { ... //一个dl运行完毕,需要将其放回运行队列中去 update_dl_rq_load_avg(rq_clock_pelt(rq), rq, 1); ... } |
9.3.3 task_tick_dl
在tick中命中的线程是dl的
|
/* * scheduler tick hitting a task of our scheduling class. * * NOTE: This function can be called remotely by the tick offload that * goes along full dynticks. Therefore no local assumption can be made * and everything must be accessed through the @rq and @curr passed in * parameters. */ static void task_tick_dl(struct rq *rq, struct task_struct *p, int queued) { ... //刚刚逝去的那段时光是在运行dl线程,此处不仅要衰减,还要考虑新增的负载 update_dl_rq_load_avg(rq_clock_pelt(rq), rq, 1); ... } |
9.3.4 switched_to_dl
一个线程有非dl状态切换到dl状态时,会调用到该函数,具体参考上面switched_to_rt
|
/* * When switching to -deadline, we may overload the rq, then * we try to push someone off, if possible. */ static void switched_to_dl(struct rq *rq, struct task_struct *p) { ...
if (rq->curr != p) { //1.满足该条件表示系统之前并不是运行p这个线程,p切换调度类变为dl后, // 突然就变成最屌的哪一个,立马得到运行了,这里不做负载相关的统计 // 具体原因参见switched_to_rt ... } else { //2.满足该条件表示之前p是作为非dl线程运行,这里需要衰减 update_dl_rq_load_avg(rq_clock_pelt(rq), rq, 0); } } |
9.4 对外接口
9.4.1 cpu_util_dl - 获取cpu在中断中的负载
|
static inline unsigned long cpu_util_dl(struct rq *rq) { return READ_ONCE(rq->avg_dl.util_avg); } |
十、更新irq的负载,记录在rq结构中:rq->avg_irq
10.1 更新接口
10.1.1 update_irq_load_avg
|
/* * irq: * * util_sum = \Sum se->avg.util_sum but se->avg.util_sum is not tracked * util_sum = cpu_scale * load_sum * runnable_sum = util_sum * * load_avg and runnable_avg are not supported and meaningless. * */
int update_irq_load_avg( struct rq *rq, u64 running) //在中断中的时间,这个时间来源于rq->clock, { //未向最大核最高频做scale处理 int ret = 0;
/* * We can't use clock_pelt because irq time is not accounted in * clock_task. Instead we directly scale the running time to * reflect the real amount of computation */ //1.因为传递进来的delta来源于rq->clock,未向最大核最高频做scale处理 // 所以这里向最大核的最高频率做scale处理 running = cap_scale(running, arch_scale_freq_capacity(cpu_of(rq))); running = cap_scale(running, arch_scale_cpu_capacity(cpu_of(rq)));
/* * We know the time that has been used by interrupt since last update * but we don't when. Let be pessimistic and assume that interrupt has * happened just before the update. This is not so far from reality * because interrupt will most probably wake up task and trig an update * of rq clock during which the metric is updated. * We start to decay with normal context time and then we add the * interrupt context time. * We can safely remove running from rq->clock because * rq->clock += delta with delta >= running */ //注意: //1.下面调用两次__update_load_sum,第一次传入0,第二次传入1 // a) 第一次传入0的含义是,先对过去的时间进行衰减,但是不累加, // 不累加的原因是这段时间并不是在执行中断上下文 // b) 第二次传入1的含义是,最running的这段时间,(也就是在中断 // 处理中执行的时间),进行衰减和累加操作 //2.两次传入的now参数不同,一次为rq->clock - running,一次为rq->clock // a) 在第一次传入的参数为rq->clock - running,这个时间点表示刚 // 进入中断处理,在这个时刻之前都是在执行任务,因此只是衰减,但是不累加 // b) 第二次调用该函数传入的参数为rq->clock,表示在rq->clock - running // 到rq->clock这段时间内,(也就是running这段时间内是在处理中断)因此 // 需要把这段时间累加进来 //3.另外需要注意的一点,下面在统计running时间的时候,并没有区分中断的类型, // 即对中断的优先级并没有做区分,可见,所有的中断时平等对待的 ret = ___update_load_sum(rq->clock - running, &rq->avg_irq, 0, 0, 0); ret += ___update_load_sum(rq->clock, &rq->avg_irq, 1, 1, 1);
if (ret) { ___update_load_avg(&rq->avg_irq, 1); trace_pelt_irq_tp(rq); }
return ret; } |
注意,上面在调用update_irq_load_avg中,调用了两次__update_load_sum,为啥捏?
如下图所示,我们将两次更新时机之间的时间划分为下面两个区间,A对应的时间段不是在中断上下文,B是真正的在中断上下文中的时间。
区间A,对应的时间戳就是rq->clock - running,我们在调用__update_load_sum时传入的参数全部为0,表示在这段时间中只对irq的负载贡献进行衰减,没有新增的贡献;
区间B,对应的时间戳为rq->clock,因为这段时间是实实在在的处理中断服务程序,所以此时再小于__update_load_sum时传入的参数为1,表示不仅需要对负载贡献进行衰减,还需要考虑新增的负载贡献
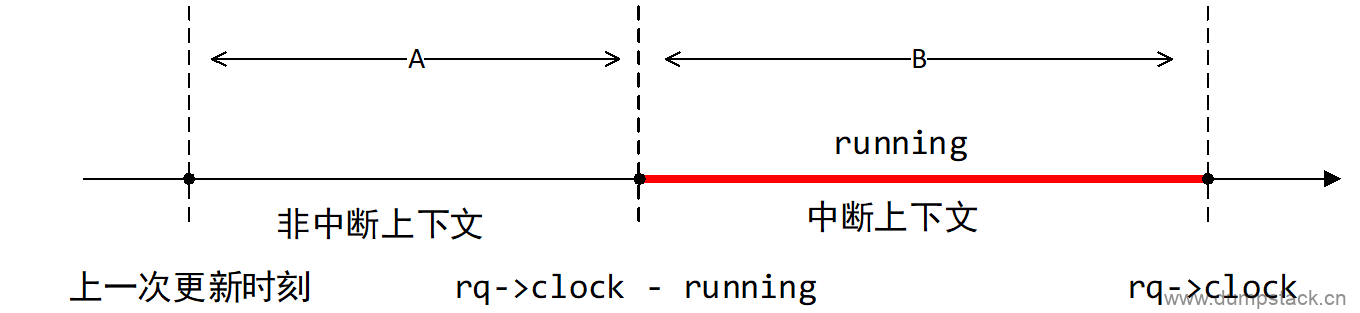
这里有一个遗留的问题:rq->clock和running的单位实际是不一样的,running是已经向最大核的最高频做了scale处理后的结构,两者不在同一个维度,为啥能直接相减呢?这样不是会倒是irq统计出来的负载会偏小吗?
10.2 参数说明
10.2.1 更新load_{sum|avg} - 始终小于1
在更新load_{sum|avg}时,传入的参数分别为0和1,含义如下
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
0:当前这段时间不是在中断上下文,此时只需要对过去的负载贡献进行衰减,无新增的负载贡献
-
1:当前这段时间位于中断上下文,不仅需要对过去负载贡献进行衰减,还需要累加新的负载贡献
load_avg计算公式如下:
|
contrib load_avg = --------------------------------------------- LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,对历史贡献的衰减不受参数影响,而只有在处理中断时,才会考虑新增的贡献
|
if (is_in_irq()) contrib = decay(history_contrib) + new_contrib else contrib = decay(history_contrib) |
因为上式的分子是始终小于分母的,所以irq_rq的load_avg是始终小于1的,如果你把它打印出来,会发现全是0
10.2.2 更新runnable_{sum|avg} - 向1024做归一化
在更新runnable_{sum|avg}时,仅在调用___update_load_sum时传入参数0或1,调用___update_load_avg无需参数影响,含义如下:
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
0:当前这段时间不是在中断上下文,此时只需要对过去的负载贡献进行衰减,无新增的负载贡献
-
1:当前这段时间位于中断上下文,不仅需要对过去负载贡献进行衰减,还需要累加新的负载贡献
runnable_avg计算公式如下:
|
contrib runnable_avg = --------------------------------------------- * 1024 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,对历史贡献的衰减不受参数影响,而只有在处理中断时,才会考虑新增的贡献
|
if (is_in_irq()) contrib = decay(history_contrib) + new_contrib else contrib = decay(history_contrib) |
因为上式的分子是始终小于分母的,所以irq_rq的runnable_avg是向1024归一化,该值始终小于1024
10.2.3 更新util_{sum|avg} - 向1024做归一化
在更新util_{sum|avg}时,仅在调用___update_load_sum时传入参数为0或1,调用___update_load_avg无需参数影响,参数running含义如下:
-
对历史负载贡献{load|runnable|util}_sum的衰减是不受参数的影响的,一定会衰减
-
0:当前这段时间不是在中断上下文,此时只需要对过去的负载贡献进行衰减,无新增的负载贡献
-
1:当前这段时间位于中断上下文,不仅需要对过去负载贡献进行衰减,还需要累加新的负载贡献
util_avg计算公式如下:
|
contrib util_avg = --------------------------------------------- * 1024 LOAD_AVG_MAX - (1024 - sa->period_contrib) |
其中,贡献contrib如下,对历史贡献的衰减不受参数影响,而只有在处理中断时,才会考虑新增的贡献
|
if (is_in_irq()) contrib = decay(history_contrib) + new_contrib else contrib = decay(history_contrib) |
因为上式的分子是始终小于分母的,所以irq_rq的util_avg是向1024归一化,该值始终小于1024
注意:irq_rq的runnable_avg和util_avg是相等的
10.3 更新时机

10.3.1 update_rq_clock_task
|
static void update_rq_clock_task( struct rq *rq, s64 delta) //这个时间来源于rq->clock,未向最大核最高频做scale处理 { /* * In theory, the compile should just see 0 here, and optimize out the call * to sched_rt_avg_update. But I don't trust it... */ s64 __maybe_unused steal = 0, irq_delta = 0;
#ifdef CONFIG_IRQ_TIME_ACCOUNTING //1.通过irq_time_read,得到的是在中断中的耗时 irq_delta = irq_time_read(cpu_of(rq)) - rq->prev_irq_time;
/* * Since irq_time is only updated on {soft,}irq_exit, we might run into * this case when a previous update_rq_clock() happened inside a * {soft,}irq region. * * When this happens, we stop ->clock_task and only update the * prev_irq_time stamp to account for the part that fit, so that a next * update will consume the rest. This ensures ->clock_task is * monotonic. * * It does however cause some slight miss-attribution of {soft,}irq * time, a more accurate solution would be to update the irq_time using * the current rq->clock timestamp, except that would require using * atomic ops. */ if (irq_delta > delta) irq_delta = delta;
rq->prev_irq_time += irq_delta;
//2.减去在中断处理中的时间 delta -= irq_delta; #endif #ifdef CONFIG_PARAVIRT_TIME_ACCOUNTING if (static_key_false((¶virt_steal_rq_enabled))) { steal = paravirt_steal_clock(cpu_of(rq)); steal -= rq->prev_steal_time_rq;
if (unlikely(steal > delta)) steal = delta;
rq->prev_steal_time_rq += steal; delta -= steal; } #endif
//3.注意,rq->clock_task这个时间来源于rq->clock,不包括中断处理的时间 // 也就是说只有在有task运行时才会向前走,并且没有向最大核最高频做归一化 rq->clock_task += delta;
#ifdef CONFIG_HAVE_SCHED_AVG_IRQ if ((irq_delta + steal) && sched_feat(NONTASK_CAPACITY)) update_irq_load_avg(rq, irq_delta + steal); #endif //4.更新clock_pelt update_rq_clock_pelt(rq, delta); } |
10.4 对外接口
10.4.1 cpu_util_irq - 获取cpu在中断中的负载
|
static inline unsigned long cpu_util_irq(struct rq *rq) { return rq->avg_irq.util_avg; } |
十一、更新group的负载
一个group在每个cpu上都对应一个gse个cfs_rq结构
一个group的负载,保存在这个group在各个cpu上的gse结构中,对于一个指定的cpu来说,这个gse的负载信息,等于这个group在这个cpu上的cfs_rq上的所有task的负载信息的和
11.1 update_tg_load_avg - 更新group的负载信息
暂不分析
|
/** * update_tg_load_avg - update the tg's load avg * @cfs_rq: the cfs_rq whose avg changed * * This function 'ensures': tg->load_avg := \Sum tg->cfs_rq[]->avg.load. * However, because tg->load_avg is a global value there are performance * considerations. * * In order to avoid having to look at the other cfs_rq's, we use a * differential update where we store the last value we propagated. This in * turn allows skipping updates if the differential is 'small'. * * Updating tg's load_avg is necessary before update_cfs_share(). */ static inline void update_tg_load_avg(struct cfs_rq *cfs_rq) { long delta = cfs_rq->avg.load_avg - cfs_rq->tg_load_avg_contrib;
/* * No need to update load_avg for root_task_group as it is not used. */ //1.根组不需要更新 // cfs_rq->tg记录这个cfs_rq运行队列所属的任务组 if (cfs_rq->tg == &root_task_group) return;
//2.为了防止频繁更新,只有相差1/64时,才执行下面的更新操作 if (abs(delta) > cfs_rq->tg_load_avg_contrib / 64) { atomic_long_add(delta, &cfs_rq->tg->load_avg); cfs_rq->tg_load_avg_contrib = cfs_rq->avg.load_avg; } } |
11.2 add_tg_cfs_propagate
cfs通过add_tg_cfs_propagate函数传递cfs_rq的load_{sum|avg}的变化,该函数定义如下:
cfs_rq load_{sum|avg}的变化的初始设置入口除了{attach|detach}_entity_load_avg()还有一个remove_entity_load_avg()函数:
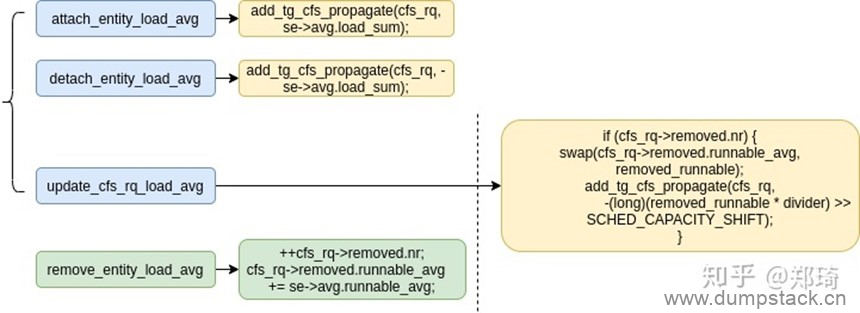
|
static inline void add_tg_cfs_propagate(struct cfs_rq *cfs_rq, long runnable_sum) { cfs_rq->propagate = 1; cfs_rq->prop_runnable_sum += runnable_sum; } |
调用时机如下:
attach_entity_load_avg/detach_entity_load_avg: 将se移入/移出cfs_rq时,这里的cfs_rq不一定是gcfs_rq
update_cfs_rq_load_avg: 更新cfs_rq
propagate_entity_load_avg:
在更新cfs_rq的负载的时候,需要将这个cfs_rq的runnable_sum也从他自己的prop_runnable_sum中移除
|
static inline int update_cfs_rq_load_avg(u64 now, struct cfs_rq *cfs_rq) { unsigned long removed_load = 0, removed_util = 0, removed_runnable = 0; struct sched_avg *sa = &cfs_rq->avg; int decayed = 0;
if (cfs_rq->removed.nr) { ... swap(cfs_rq->removed.runnable_avg, removed_runnable); ...
/* * removed_runnable is the unweighted version of removed_load so we * can use it to estimate removed_load_sum. */ //1.减去runnable的贡献 // 因为上面获取到的是avg,所以在减去sum的时候需要乘以divider // 右移是因为??? add_tg_cfs_propagate(cfs_rq, -(long)(removed_runnable * divider) >> SCHED_CAPACITY_SHIFT);
decayed = 1; }
... } |
将一个se添加进cfs_rq时,将se的load_sum添加进cfs_rq->prop_runnable_sum
|
static void attach_entity_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se) { u32 divider = get_pelt_divider(&cfs_rq->avg);
... se->avg.load_sum = divider; if (se_weight(se)) { se->avg.load_sum = div_u64(se->avg.load_avg * se->avg.load_sum, se_weight(se)); }
... add_tg_cfs_propagate(cfs_rq, se->avg.load_sum); ... } |
将一个se移出cfs_rq时,将se的load_sum移出cfs_rq->prop_runnable_sum
|
static void detach_entity_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se) { ... add_tg_cfs_propagate(cfs_rq, -se->avg.load_sum); ... } |
11.3 propagate_entity_load_avg - 更新gse的负载信息
更新task和cfs_rq的负载信息,暂不分析
propagate机制的实现参见下面patch
负载传播组调度负载的变化

|
/* Update task and its cfs_rq load average */ static inline int propagate_entity_load_avg(struct sched_entity *se) { struct cfs_rq *cfs_rq, *gcfs_rq;
//1.是task直接返回,下面只对gse进行更新 // 只有gse才会有gcfs_rq,才需要传播和更新负载 if (entity_is_task(se)) return 0;
//2.返回se->my_q,即gse对应的gcfs_rq结构 // 因为一个group在每个cpu上都对应一个gse和cfs_rq, // se->my_q记录的是这个group在这个cpu上的cfs_rq结构, // 用于挂在这个group在这个cpu上所有task gcfs_rq = group_cfs_rq(se);
//3.类似开关,防止多次传播 // 判断是否有负载变化需要传播,也就是说是否有新增的负载 if (!gcfs_rq->propagate) return 0; gcfs_rq->propagate = 0;
//4.返回se->cfs_rq,即gse挂在那个cpu上 // 表示这个group在这个cpu上的gse结构,当前是挂在那个cfs_rq下 cfs_rq = cfs_rq_of(se);
//5.将gcfs_rq的prop_runnable_sum,传递到其所依附的cfs_rq上 // 继续置位cfs_rq->propagate,将负载变化传播到这个gcfs_rq的上一级gse中, // 也就是父group的gse结构,当父group的gse作为形参继续调用propagate_entity_load_avg // 函数时,则继续更新父group的gse和其所在的gcfs_rq中的负载,如此循环,直到root cfs_rq add_tg_cfs_propagate(cfs_rq, gcfs_rq->prop_runnable_sum);
//6.更新gse及其所在的cfs_rq中的负载, // 将gcfs_rq下的负载信息,全部传递给gse所挂的cfs_rq上 update_tg_cfs_util(cfs_rq, se, gcfs_rq); update_tg_cfs_runnable(cfs_rq, se, gcfs_rq); update_tg_cfs_load(cfs_rq, se, gcfs_rq);
//7.trace打印相关 trace_pelt_cfs_tp(cfs_rq); trace_pelt_se_tp(se);
return 1; } |
11.4 update_tg_cfs_util
注意:一个group在每个cpu上都对应一个gse个cfs_rq结构
|
static inline void update_tg_cfs_util( struct cfs_rq *cfs_rq, //这个group的gse结构被挂在那个cfs_rq上 struct sched_entity *se, //这个group在某个cpu上的gse结构 struct cfs_rq *gcfs_rq) //这个group在这个cpu上的cfs_rq结构 { //1.计算gcfs_rq和gse中记录的负载差值,这个差值表示???? // a) gcfs_rq中记录的util信息,只有在gcfs_rq->curr != NULL时才会 // 统计,即这个group中某个任务正在运行时才会统计 // b) gse中记录的util信息,只有在cfs_rq->curr == gse时才会统计,也 // 就是说这个group的gse被pick运行时,也就是说group中某个任务正在运行 long delta = gcfs_rq->avg.util_avg - se->avg.util_avg; u32 divider;
/* Nothing to update */ //2.为啥为0就不用更新呢???这个delta究竟是啥意思呢??? if (!delta) return;
/* * cfs_rq->avg.period_contrib can be used for both cfs_rq and se. * See ___update_load_avg() for details. */ //3.计算极限值 divider = get_pelt_divider(&cfs_rq->avg);
/* Set new sched_entity's utilization */ //4.直接将gcfs_rq中记录的负载信息赋值给gse se->avg.util_avg = gcfs_rq->avg.util_avg; se->avg.util_sum = se->avg.util_avg * divider;
/* Update parent cfs_rq utilization */ //5.更新gse所在的cfs_rq的负载信息 // 将util_avg的变化传播并更新到cfs_rq add_positive(&cfs_rq->avg.util_avg, delta); cfs_rq->avg.util_sum = cfs_rq->avg.util_avg * divider; } |
11.5 update_tg_cfs_runnable
注意:一个group在每个cpu上都对应一个gse个cfs_rq结构
|
static inline void update_tg_cfs_runnable( struct cfs_rq *cfs_rq, //这个group的gse结构被挂在那个cfs_rq上 struct sched_entity *se, //这个group在某个cpu上的gse结构 struct cfs_rq *gcfs_rq) //这个group在这个cpu上的cfs_rq结构 { long delta = gcfs_rq->avg.runnable_avg - se->avg.runnable_avg; u32 divider;
/* Nothing to update */ if (!delta) return;
/* * cfs_rq->avg.period_contrib can be used for both cfs_rq and se. * See ___update_load_avg() for details. */ divider = get_pelt_divider(&cfs_rq->avg);
/* Set new sched_entity's runnable */ se->avg.runnable_avg = gcfs_rq->avg.runnable_avg; se->avg.runnable_sum = se->avg.runnable_avg * divider;
/* Update parent cfs_rq runnable */ add_positive(&cfs_rq->avg.runnable_avg, delta); cfs_rq->avg.runnable_sum = cfs_rq->avg.runnable_avg * divider; } |
11.6 update_tg_cfs_load
runnable_{sum|avg}的传播更新与util_{sum|avg}基本一致,而cfs_rq的load_{sum|avg}均乘以了权重weight,所以需要使用cfs_rq->prop_runnable_sum成员进行传播与更新,见update_tg_cfs_load()函数:
注意:一个group在每个cpu上都对应一个gse个cfs_rq结构
|
static inline void update_tg_cfs_load( struct cfs_rq *cfs_rq, //这个group的gse结构被挂在那个cfs_rq上 struct sched_entity *se, //这个group在某个cpu上的gse结构 struct cfs_rq *gcfs_rq) //这个group在这个cpu上的cfs_rq结构 { //获取gcfs_rq的prop_runnable_sum值 long delta, running_sum, runnable_sum = gcfs_rq->prop_runnable_sum; unsigned long load_avg; u64 load_sum = 0; u32 divider;
//无变化则直接返回 if (!runnable_sum) return; gcfs_rq->prop_runnable_sum = 0;
/* * cfs_rq->avg.period_contrib can be used for both cfs_rq and se. * See ___update_load_avg() for details. */ divider = get_pelt_divider(&cfs_rq->avg);
if (runnable_sum >= 0) { /* * Add runnable; clip at LOAD_AVG_MAX. Reflects that until * the CPU is saturated running == runnable. */ //se->avg.load_sum:更新前的group se的负载值 //此处加上新增的runnable_sum,最大值不能超过divider runnable_sum += se->avg.load_sum; runnable_sum = min_t(long, runnable_sum, divider); } else { /* * Estimate the new unweighted runnable_sum of the gcfs_rq by * assuming all tasks are equally runnable. */ //假设gcfs_rq下所有se都处于runnable状态,计算去除权重的load_sum值 //见2.2.2小节公式,cfs_rq的load_sum包含了weight if (scale_load_down(gcfs_rq->load.weight)) { load_sum = div_s64(gcfs_rq->avg.load_sum, scale_load_down(gcfs_rq->load.weight)); }
/* But make sure to not inflate se's runnable */ //与此前的se->avg.load_sum比较,取最小值 runnable_sum = min(se->avg.load_sum, load_sum); }
/* * runnable_sum can't be lower than running_sum * Rescale running sum to be in the same range as runnable sum * running_sum is in [0 : LOAD_AVG_MAX << SCHED_CAPACITY_SHIFT] * runnable_sum is in [0 : LOAD_AVG_MAX] */ //保证runnable_sum大于等于running_sum running_sum = se->avg.util_sum >> SCHED_CAPACITY_SHIFT; runnable_sum = max(runnable_sum, running_sum);
//基于修正过后的runnable_sum值重新计算load_{sum|avg} load_sum = (s64)se_weight(se) * runnable_sum; load_avg = div_s64(load_sum, divider);
//计算差值 delta = load_avg - se->avg.load_avg;
//更新group se的load_{sum|avg} se->avg.load_sum = runnable_sum; se->avg.load_avg = load_avg;
//更新group se所在cfs_rq的load_{sum|avg} add_positive(&cfs_rq->avg.load_avg, delta); cfs_rq->avg.load_sum = cfs_rq->avg.load_avg * divider; } |
十二、负载更新流程
负载更新的接口是update_load_avg,下面我们就来分析一下update_load_avg的实现
12.1 update_load_avg - 更新se的cfs_rq的负载信息
|
#ifdef CONFIG_SMP /* Update task and its cfs_rq load average */ static inline void update_load_avg( struct cfs_rq *cfs_rq, //要更新哪个cfs_rq的负载信息 struct sched_entity *se, //要更新哪个se的负载信息 int flags) //flags可取值如下 // a) UPDATE_TG: 是否更新task group的负载 // b) DO_ATTACH: 标记表示se被添加进队列 // c) SKIP_AGE_LOAD: 标记是否跳过本次负载统计 { //1.时间取clock_pelt,该时钟来源于clock_task, // 并且已经向最大核的最高频做归一化处理 u64 now = cfs_rq_clock_pelt(cfs_rq); int decayed;
/* * Track task load average for carrying it to new CPU after migrated, and * track group sched_entity load average for task_h_load calc in migration */ //2.更新se的负载信息 // 第一个条件:只有当进程刚被创建或进程迁移的时候,se->avg.last_update_time // 的值才为0,也就是这个tse是刚刚被加到这个cfs_rq队列上的,因 // 其还没有得到运行,所以现在不需要对他的负载进行更新 // 第二个条件:表示本次跳过对这个task的负载更新 if (se->avg.last_update_time && !(flags & SKIP_AGE_LOAD)) __update_load_avg_se(now, cfs_rq, se);
//3.更新cfs_rq的负载信息 // cfs_rq队列的负载({load|runnable}_avg)就是该cfs_rq队列下所有的se负载总和 // 返回值decayed表示cfs_rq队列的负载已经更新,后面需要进行调频了 decayed = update_cfs_rq_load_avg(now, cfs_rq);
//4.沿组调度层级传播负载变化,暂时不分析 decayed |= propagate_entity_load_avg(se);
//5.由下面注释也可知,该条件表示这是一个新创建或者刚迁移过来的线程, // 也就是说是刚被加到这个cfs_rq上的se // 第一个条件:为0表示这是一个刚创建或者刚迁移过来的线程 // 第二个条件:只有在enqueue_entity中才会传入DO_ATTACH标志 if (!se->avg.last_update_time && (flags & DO_ATTACH)) {
/* * DO_ATTACH means we're here from enqueue_entity(). * !last_update_time means we've passed through * migrate_task_rq_fair() indicating we migrated. * * IOW we're enqueueing a task on a new CPU. */ //5.1 不管是新创建的线程被加到cfs_rq,还是从别的cpu上刚迁移过来的一个 // 线程,总而言之,这个se是刚被挂到这个cfs_rq上的,此时需要将se的负 // 载信息{load|runnable|util}_{avg|sum}加到其所attach的cfs_rq中 attach_entity_load_avg(cfs_rq, se);
//5.2更新cfs_rq所在的task_group的负载 update_tg_load_avg(cfs_rq);
} else if (decayed) { //5.当cfs_rq负载发生变化时,decayed为true,则触发调频 cfs_rq_util_change(cfs_rq, 0);
if (flags & UPDATE_TG) update_tg_load_avg(cfs_rq); } } #else static inline void update_load_avg( struct cfs_rq *cfs_rq, struct sched_entity *se, int not_used1) { //cfs_rq的util发生变化,触发调频 cfs_rq_util_change(cfs_rq, 0); } #endif |
十三、负载更新时机
由上面分析可知,负载更新的接口为update_load_avg,那么调用update_load_avg的时机就是负载更新的时机了,具体如下,总结一下就是下面两种情况会触发对负载的更新
-
se的状态发生变化,例如从进入阻塞状态、从阻塞状态唤醒、从running变为runnable、从runnable变为running
-
周期性的更新,即当一个task长时间处于某个状态时,(例如长时间处于running状态),就不会有状态的变化,上面的更新时机就进不去,此时可以在tick中更新负载信息
下面具体分析:
13.1 dequeue时:进入睡眠状态
一个task从cfs_rq上摘除时,需要完成下面工作:
-
将这个task的预估负载util_est从cfs_rq上移除
-
将这个task对应的权重从cfs_rq上移除
-
但是这个task对应的{load|runnable|uitl}_{sum|avg}这几个负载贡献是不会被移除的,为啥呢?为啥要区别对待呢?有知道的大牛麻烦回复我一下!
实际上,当一个task进入D状态时,也会对cfs_rq的负载带来贡献,除非这个task被迁移到其他cpu上,这个task对应的load_avg信息才会从cfs_rq上扣除,具体参见detach_entity_load_avg的实现
注意:当se从cfs_rq上删除时,并不会将se的{load|util}_{avg|sum}负载从cfs_rq中移除,只是将se的runnable_load_{avg|sum}和权重信息从cfs_rq队列的权重中移除。这是为什么呢????
没有将{load|util}_{avg|sum}从cfs_rq中移除,这是考虑到:即使一个task以后不再这个cfs_rq上了,但是只要他曾经在过这个cfs_rq上跑过,他曾经的辉煌依然会对这个cfs_rq队列的负载产生贡献
但是将runnable_load_{avg|sum}从cfs_rq中移除,是因为runnable_load_{avg|sum}只统计哪些真正在这个cfs_rq上的se进行统计
还有一个角度可以解释为什么不把{load|util}_{avg|sum}负载从cfs_rq中移除,如果移除了,那么在下次唤醒的时候,负载的计算从最低开始,这样的话会很慢,导致提频慢
13.1.1 dequeue_task_fair
|
/* * The dequeue_task method is called before nr_running is * decreased. We remove the task from the rbtree and * update the fair scheduling stats: */ static void dequeue_task_fair( struct rq *rq, struct task_struct *p, //要从队列上移除的task int flags) { struct cfs_rq *cfs_rq; struct sched_entity *se = &p->se; int task_sleep = flags & DEQUEUE_SLEEP; int idle_h_nr_running = task_has_idle_policy(p); bool was_sched_idle = sched_idle_rq(rq);
//1.将这个task的预估负载util_est从cfs_rq上移除 util_est_dequeue(&rq->cfs, p);
//2.第一步:摘除哪些只有一个tse的gse,并更新一些统计变量, // 如果这个task进D状态后,gse上就没有任务了,则需要同时摘除gse for_each_sched_entity(se) { //2.1 执行摘蛋动作 cfs_rq = cfs_rq_of(se); dequeue_entity(cfs_rq, se, flags);
//2.2 更新统计变量 // 该变量用于统计这个cfs_rq上还剩下多少task等待调度 cfs_rq->h_nr_running--; cfs_rq->idle_h_nr_running -= idle_h_nr_running;
/* end evaluation on encountering a throttled cfs_rq */ if (cfs_rq_throttled(cfs_rq)) goto dequeue_throttle;
/* Don't dequeue parent if it has other entities besides us */ //2.3 如果遇到一个gse下,处理当前tse外还有其他task,(此时权重不为0) // 此时将挑出本循环体,进入下面的循环体 if (cfs_rq->load.weight) { /* Avoid re-evaluating load for this entity: */ se = parent_entity(se); /* * Bias pick_next to pick a task from this cfs_rq, as * p is sleeping when it is within its sched_slice. */ if (task_sleep && se && !throttled_hierarchy(cfs_rq)) set_next_buddy(se); break; } //2.4 摘蛋时打上睡眠标记 flags |= DEQUEUE_SLEEP; }
//3.对于那些有多个task的gse来说,即使这个tse被摘除,还有其 // 他任务等待调度,此时只需要更新统计变量,不需要执行摘蛋动作 for_each_sched_entity(se) { cfs_rq = cfs_rq_of(se);
//3.1 更新task和cfs_rq的负载贡献信息 update_load_avg(cfs_rq, se, UPDATE_TG); se_update_runnable(se); update_cfs_group(se);
//3.2 更新统计变量 cfs_rq->h_nr_running--; cfs_rq->idle_h_nr_running -= idle_h_nr_running;
/* end evaluation on encountering a throttled cfs_rq */ if (cfs_rq_throttled(cfs_rq)) goto dequeue_throttle;
}
/* At this point se is NULL and we are at root level*/ sub_nr_running(rq, 1);
/* balance early to pull high priority tasks */ if (unlikely(!was_sched_idle && sched_idle_rq(rq))) rq->next_balance = jiffies;
dequeue_throttle: //4.如果这个task是要进入睡眠状态,则更新这个task的预估负载 util_est_update(&rq->cfs, p, task_sleep); hrtick_update(rq); } |
13.1.2 dequeue_entity - 将se移出红黑树
由下面的注释可知,当一个se被移除cfs_rq时,需要执行下面的操作:
-
更新se和cfs_rq的负载信息
-
将这个se的负载信息从cfs_rq中移除
-
将这个se的权重从cfs_rq中移除
-
对于一个gse来说,需要更新其权重和各个cpu上分得的shares值
|
static void dequeue_entity( struct cfs_rq *cfs_rq, struct sched_entity *se, int flags) { ...
/* * When dequeuing a sched_entity, we must: * - Update loads to have both entity and cfs_rq synced with now. * - Subtract its load from the cfs_rq->runnable_avg. * - Subtract its previous weight from cfs_rq->load.weight. * - For group entity, update its weight to reflect the new share * of its group cfs_rq. */ //1.task对应的se即将从cfs_rq上摘除 // 更新task和cfs_rq的负载贡献信息 update_load_avg(cfs_rq, se, UPDATE_TG); se_update_runnable(se);
update_stats_dequeue(cfs_rq, se, flags);
clear_buddies(cfs_rq, se);
//2.从红黑树上摘除 // 如果这个se是当前正在运行的cfs_rq->curr,则其已经从红黑树 // 上被移除了(set_next_entity中会将其从红黑树上摘除),则不 // 需要执行下面从红黑树上摘除的动作 if (se != cfs_rq->curr) __dequeue_entity(cfs_rq, se);
//3.设置on_rq,标记其已经不在运行队列上(红黑树和curr) se->on_rq = 0;
//4.将se的权重从cfs_rq上移除 account_entity_dequeue(cfs_rq, se);
... } |
13.2 enqueue时:从睡眠状态唤醒
13.2.1 enqueue_task_fair
|
/* * The enqueue_task method is called before nr_running is * increased. Here we update the fair scheduling stats and * then put the task into the rbtree: */ static void enqueue_task_fair( struct rq *rq, struct task_struct *p, int flags) { struct cfs_rq *cfs_rq; struct sched_entity *se = &p->se; int idle_h_nr_running = task_has_idle_policy(p); int task_new = !(flags & ENQUEUE_WAKEUP);
/* * The code below (indirectly) updates schedutil which looks at * the cfs_rq utilization to select a frequency. * Let's add the task's estimated utilization to the cfs_rq's * estimated utilization, before we update schedutil. */ //1.当一个task被唤醒,他的预估负载会重新加回cfs_rq中 util_est_enqueue(&rq->cfs, p);
/* * If in_iowait is set, the code below may not trigger any cpufreq * utilization updates, so do it here explicitly with the IOWAIT flag * passed. */ //2.如果这个task刚刚是在等io,则触发调频 if (p->in_iowait) cpufreq_update_util(rq, SCHED_CPUFREQ_IOWAIT);
//3.这里将task重新插回队列依然是分两步 // 第一步,对于之前哪些,只剩一个tse的gse,重新插回队列中去 // 并更新相应的统计信息 for_each_sched_entity(se) { //3.1 如果正在遍历的gse已经在队列中,则不需要再遍历了 if (se->on_rq) break;
//3.2 对于哪些不在队列上的gse,将其重新挂回队列 cfs_rq = cfs_rq_of(se); enqueue_entity(cfs_rq, se, flags);
//3.3 更新统计信息,记录这个cfs_rq上的线程个数 cfs_rq->h_nr_running++; cfs_rq->idle_h_nr_running += idle_h_nr_running;
/* end evaluation on encountering a throttled cfs_rq */ if (cfs_rq_throttled(cfs_rq)) goto enqueue_throttle;
//3.4 新唤醒的tse和gse的标记 flags = ENQUEUE_WAKEUP; }
//4.对于哪些已经在队列上的tse,只需要更新其统计信息即可 for_each_sched_entity(se) { cfs_rq = cfs_rq_of(se);
//4.1 更新se和cfs_rq的负载信息 update_load_avg(cfs_rq, se, UPDATE_TG); se_update_runnable(se); update_cfs_group(se);
//4.2 更新统计信息 cfs_rq->h_nr_running++; cfs_rq->idle_h_nr_running += idle_h_nr_running;
/* end evaluation on encountering a throttled cfs_rq */ if (cfs_rq_throttled(cfs_rq)) goto enqueue_throttle;
/* * One parent has been throttled and cfs_rq removed from the * list. Add it back to not break the leaf list. */ if (throttled_hierarchy(cfs_rq)) list_add_leaf_cfs_rq(cfs_rq); }
/* At this point se is NULL and we are at root level*/ add_nr_running(rq, 1);
/* * Since new tasks are assigned an initial util_avg equal to * half of the spare capacity of their CPU, tiny tasks have the * ability to cross the overutilized threshold, which will * result in the load balancer ruining all the task placement * done by EAS. As a way to mitigate that effect, do not account * for the first enqueue operation of new tasks during the * overutilized flag detection. * * A better way of solving this problem would be to wait for * the PELT signals of tasks to converge before taking them * into account, but that is not straightforward to implement, * and the following generally works well enough in practice. */ if (!task_new) update_overutilized_status(rq);
enqueue_throttle: if (cfs_bandwidth_used()) { /* * When bandwidth control is enabled; the cfs_rq_throttled() * breaks in the above iteration can result in incomplete * leaf list maintenance, resulting in triggering the assertion * below. */ for_each_sched_entity(se) { cfs_rq = cfs_rq_of(se);
if (list_add_leaf_cfs_rq(cfs_rq)) break; } }
assert_list_leaf_cfs_rq(rq);
hrtick_update(rq); } |
13.2.2 enqueue_entity - 将se挂入红黑树
由下面的注释可知,当enqueue一个se时,需要执行下面工作
-
更新se和cfs_rq的负载信息
-
将se的负载信息累加进cfs_rq中
-
对于gse来说,需要调整gse的权重和各个cpu上的shares值
-
将se的权重信息累加进cfs_rq中
|
static void enqueue_entity( struct cfs_rq *cfs_rq, struct sched_entity *se, int flags) { bool curr = cfs_rq->curr == se; ...
/* * When enqueuing a sched_entity, we must: * - Update loads to have both entity and cfs_rq synced with now. * - Add its load to cfs_rq->runnable_avg * - For group_entity, update its weight to reflect the new share of its group cfs_rq * - Add its new weight to cfs_rq->load.weight */ //1.更新se和cfs_rq的负载信息 update_load_avg(cfs_rq, se, UPDATE_TG | DO_ATTACH); se_update_runnable(se); update_cfs_group(se);
//2.将se的权重重新加回到cfs_rq上 account_entity_enqueue(cfs_rq, se);
//3.对刚唤醒的task的虚拟运行时间进行补偿 if (flags & ENQUEUE_WAKEUP) place_entity(cfs_rq, se, 0);
check_schedstat_required(); update_stats_enqueue(cfs_rq, se, flags); check_spread(cfs_rq, se);
//4.如果这个刚唤醒的task不是被立刻拿来做curr // 运行,则需要将其重新插入红黑树中 if (!curr) __enqueue_entity(cfs_rq, se);
//5.设置on_rq标记,标记其已经在队列上了 se->on_rq = 1;
... } |
13.3 set_next_entity - 从状态runnable -> running
线程从红黑树中被pick出来作为curr
|
static void set_next_entity( struct cfs_rq *cfs_rq, struct sched_entity *se) { /* 'current' is not kept within the tree. */ //1.on_rq为1表示这个se是在红黑树中,而不是curr // 此时需要将其从红黑树中摘除 if (se->on_rq) { /* * Any task has to be enqueued before it get to execute on * a CPU. So account for the time it spent waiting on the * runqueue. */ update_stats_wait_end(cfs_rq, se);
//1.1 将其从红黑树中摘除 __dequeue_entity(cfs_rq, se);
//1.2 更新se的负载信息 update_load_avg(cfs_rq, se, UPDATE_TG); }
update_stats_curr_start(cfs_rq, se);
//2.将这个se作为curr cfs_rq->curr = se;
/* * Track our maximum slice length, if the CPU's load is at * least twice that of our own weight (i.e. dont track it * when there are only lesser-weight tasks around): */ if (schedstat_enabled() && rq_of(cfs_rq)->cfs.load.weight >= 2*se->load.weight) { schedstat_set(se->statistics.slice_max, max((u64)schedstat_val(se->statistics.slice_max), se->sum_exec_runtime - se->prev_sum_exec_runtime)); }
se->prev_sum_exec_runtime = se->sum_exec_runtime; } |
13.4 put_prev_entity - 从状态running -> runnable
prev线程作为curr运行,时间片耗完后,现在需要将其重新插回红黑树中
|
static void put_prev_entity( struct cfs_rq *cfs_rq, struct sched_entity *prev) //要将谁重新放回队列 { /* * If still on the runqueue then deactivate_task() * was not called and update_curr() has to be done: */ if (prev->on_rq) update_curr(cfs_rq);
/* throttle cfs_rqs exceeding runtime */ check_cfs_rq_runtime(cfs_rq);
check_spread(cfs_rq, prev);
if (prev->on_rq) { update_stats_wait_start(cfs_rq, prev);
/* Put 'current' back into the tree. */ //1.将其从红黑树中摘除 __enqueue_entity(cfs_rq, prev);
/* in !on_rq case, update occurred at dequeue */ //2.更新负载信息 update_load_avg(cfs_rq, prev, 0); }
//3.临时清空,会在set_next_entity中重新设置 cfs_rq->curr = NULL; } |
13.5 周期性的更新
如果一个task长时间运行,没有发生状态切换,则也会在tick中完成负载的更新
13.5.1 scheduler_tick
|
void scheduler_tick(void) { int cpu = smp_processor_id(); struct rq *rq = cpu_rq(cpu); struct task_struct *curr = rq->curr;
... curr->sched_class->task_tick(rq, curr, 0); ... } |
13.5.2 task_tick_fair
|
/* * scheduler tick hitting a task of our scheduling class. * * NOTE: This function can be called remotely by the tick offload that * goes along full dynticks. Therefore no local assumption can be made * and everything must be accessed through the @rq and @curr passed in * parameters. */ static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued) { struct cfs_rq *cfs_rq; struct sched_entity *se = &curr->se;
for_each_sched_entity(se) { cfs_rq = cfs_rq_of(se); entity_tick(cfs_rq, se, queued); }
... } |
13.5.3 entity_tick
|
static void entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued) { ... /* * Ensure that runnable average is periodically updated. */ update_load_avg(cfs_rq, curr, UPDATE_TG); ... } |
十四、se的负载信息和cfs_rq的关系
14.1 仅仅是进入睡眠的task,其负载信息不会从cfs_rq中移除
cfs_rq的{load|runnable|util}_{sum|avg}等于其下所有se对应值之和,包含blocked和running+runnable状态的,通过attach_entity_load_avg和detach_entity_load_avg将一个se的负载贡献添加到cfs_rq或从cfs_rq中移除;从这两个函数可以清晰的看出cfs_rq负载与其下se负载的关系
下面这个结论很重要,因此我们写在最前面
注意:仅仅是进入睡眠状态的se,并不会将se的负载信息{load|runnable|util}_{avg|sum}从cfs_rq的中删除。因此,cfs_rq的负载信息中包含了所有调度实体的可运行状态以及阻塞状态(block, running, runnable三种状态)的负载信息,即cfs_rq的负载信息科看做是block, running, runnable三种状态的se的负载的和
那么什么时候会将se的负载信息从cfs_rq中移除呢?下面我们详细分析
14.2 将se的负载信息从cfs_rq中移除
下面3种情况需要移除:
-
task从cfs调度类切换到其他调度类时,例如用户空间将一个cfs线程修改为rt线程时
-
task从一个group切换到另一个group时,例如一个task从前台推到后台时
-
task从一个cpu迁移到另一个cpu上运行时
14.2.1 detach_entity_cfs_rq - 将se从cfs_rq上摘下来
|
static void detach_entity_cfs_rq(struct sched_entity *se) { struct cfs_rq *cfs_rq = cfs_rq_of(se);
/* Catch up with the cfs_rq and remove our load when we leave */ //1.更新se和cfs_rq的负载信息 // 注意这里传入的flags为0,表示只对se和cfs_rq的负载信息进行更新, // 暂不考虑是否需要将se的负载信息累加到cfs_rq上 update_load_avg(cfs_rq, se, 0);
//2.将se的负载信息从cfs_rq中扣除 detach_entity_load_avg(cfs_rq, se);
//3.group相关 update_tg_load_avg(cfs_rq); propagate_entity_cfs_rq(se); } |
14.2.2 detach_entity_load_avg - 将se的负载信息累加进cfs_rq中去
|
/** * detach_entity_load_avg - detach this entity from its cfs_rq load avg * @cfs_rq: cfs_rq to detach from * @se: sched_entity to detach * * Must call update_cfs_rq_load_avg() before this, since we rely on * cfs_rq->avg.last_update_time being current. */ static void detach_entity_load_avg( struct cfs_rq *cfs_rq, struct sched_entity *se) { /* * cfs_rq->avg.period_contrib can be used for both cfs_rq and se. * See ___update_load_avg() for details. */ u32 divider = get_pelt_divider(&cfs_rq->avg);
//1.将se的负载信息{load|runnable|util}_avg从rq中删除 dequeue_load_avg(cfs_rq, se); sub_positive(&cfs_rq->avg.util_avg, se->avg.util_avg); cfs_rq->avg.util_sum = cfs_rq->avg.util_avg * divider; sub_positive(&cfs_rq->avg.runnable_avg, se->avg.runnable_avg); cfs_rq->avg.runnable_sum = cfs_rq->avg.runnable_avg * divider;
add_tg_cfs_propagate(cfs_rq, -se->avg.load_sum);
//2.cfs_rq的负载已经发生变化,触发调频 cfs_rq_util_change(cfs_rq, 0);
trace_pelt_cfs_tp(cfs_rq); } |
14.2.3 dequeue_load_avg - 将se的load_avg从cfs_rq中移除
|
#ifdef CONFIG_SMP static inline void dequeue_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se) { sub_positive(&cfs_rq->avg.load_avg, se->avg.load_avg); sub_positive(&cfs_rq->avg.load_sum, se_weight(se) * se->avg.load_sum); } #else static inline void dequeue_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se) { } #endif |
14.2.4 detach_entity_cfs_rq在哪调用
调用关系如下:
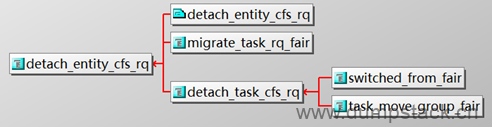
14.2.4.1 switched_from_fair - 切换task的调度类时
当一个task从cfs调度类切换到其他调度类的时候,(一般是指用户空间通过系统调用的方式修改了一个task的属性,例如从cfs切到rt),执行完dequeue操作后,会调用下面的switched_from_fair操作,将se的负载信息{load|runnable|util}_{avg|sum}从cfs_rq中刨除
|
static void switched_from_fair(struct rq *rq, struct task_struct *p) { detach_task_cfs_rq(p); } |
14.2.4.2 task_move_group_fair - 切换task所属group时
当一个task从一个group切换到另一个group的时候,(例如一个task从前台推到后台时),执行完dequeue操作后,会调用到下面的task_move_group_fair操作,将se的负载信息{load|runnable|util}_{avg|sum}从cfs_rq中刨除
|
static void task_move_group_fair(struct task_struct *p) { //1.先将se的负载信息从旧的cfs_rq中摘除 detach_task_cfs_rq(p);
//2.修改cpu set_task_rq(p, task_cpu(p));
#ifdef CONFIG_SMP /* Tell se's cfs_rq has been changed -- migrated */ p->se.avg.last_update_time = 0; #endif //3.再将se的负载信息加入到新的cfs_rq中去 attach_task_cfs_rq(p); } |
14.2.4.3 migrate_task_rq_fair - task迁核时
|
/* * Called immediately before a task is migrated to a new CPU; task_cpu(p) and * cfs_rq_of(p) references at time of call are still valid and identify the * previous CPU. The caller guarantees p->pi_lock or task_rq(p)->lock is held. */ static void migrate_task_rq_fair( struct task_struct *p, int new_cpu) //迁移到的新的cpu { /* * As blocked tasks retain absolute vruntime the migration needs to * deal with this by subtracting the old and adding the new * min_vruntime -- the latter is done by enqueue_entity() when placing * the task on the new runqueue. */ //1.在迁核之前,se的虚拟运行时间需要先减去原有cfs_rq的虚拟运行时间 if (p->state == TASK_WAKING) { struct sched_entity *se = &p->se; struct cfs_rq *cfs_rq = cfs_rq_of(se); u64 min_vruntime;
#ifndef CONFIG_64BIT u64 min_vruntime_copy;
do { min_vruntime_copy = cfs_rq->min_vruntime_copy; smp_rmb(); min_vruntime = cfs_rq->min_vruntime; } while (min_vruntime != min_vruntime_copy); #else min_vruntime = cfs_rq->min_vruntime; #endif
se->vruntime -= min_vruntime; }
if (p->on_rq == TASK_ON_RQ_MIGRATING) { /* * In case of TASK_ON_RQ_MIGRATING we in fact hold the 'old' * rq->lock and can modify state directly. */ //2.如果这个task正在迁移,则需要将这个se的负载信息从cfs_rq上扣除 lockdep_assert_held(&task_rq(p)->lock); detach_entity_cfs_rq(&p->se);
} else { /* * We are supposed to update the task to "current" time, then * its up to date and ready to go to new CPU/cfs_rq. But we * have difficulty in getting what current time is, so simply * throw away the out-of-date time. This will result in the * wakee task is less decayed, but giving the wakee more load * sounds not bad. */ //3.将这个se的负载信息先累加进removed成员,等到更新cfs_rq // 负载时,将这部分负载从cfs_rq中扣除 remove_entity_load_avg(&p->se); }
/* Tell new CPU we are migrated */ //4.注意:迁核后,这里的时间戳会被清零 p->se.avg.last_update_time = 0;
/* We have migrated, no longer consider this task hot */ p->se.exec_start = 0;
update_scan_period(p, new_cpu); } |
14.3 将se的负载信息累加进cfs_rq
14.3.1 attach_entity_cfs_rq - 将se从从其他rq添加到cfs_rq上
|
static void attach_entity_cfs_rq(struct sched_entity *se) { struct cfs_rq *cfs_rq = cfs_rq_of(se);
#ifdef CONFIG_FAIR_GROUP_SCHED /* * Since the real-depth could have been changed (only FAIR * class maintain depth value), reset depth properly. */ se->depth = se->parent ? se->parent->depth + 1 : 0; #endif
/* Synchronize entity with its cfs_rq */ //1.更新se和cfs_rq的负载信息 update_load_avg(cfs_rq, se, sched_feat(ATTACH_AGE_LOAD) ? 0 : SKIP_AGE_LOAD);
//2.将se的负载信息累加进cfs_rq中去 attach_entity_load_avg(cfs_rq, se); update_tg_load_avg(cfs_rq); propagate_entity_cfs_rq(se); } |
14.3.2 attach_entity_load_avg - 将se的负载信息累加进cfs_rq中去
|
/** * attach_entity_load_avg - attach this entity to its cfs_rq load avg * @cfs_rq: cfs_rq to attach to * @se: sched_entity to attach * * Must call update_cfs_rq_load_avg() before this, since we rely on * cfs_rq->avg.last_update_time being current. */ static void attach_entity_load_avg( struct cfs_rq *cfs_rq, struct sched_entity *se) { /* * cfs_rq->avg.period_contrib can be used for both cfs_rq and se. * See ___update_load_avg() for details. */ u32 divider = get_pelt_divider(&cfs_rq->avg);
/* * When we attach the @se to the @cfs_rq, we must align the decay * window because without that, really weird and wonderful things can * happen. * * XXX illustrate */ //1.由上面的注释可知,当一个se切换cfs_rq时,必须保证衰减的窗口是对齐的 se->avg.last_update_time = cfs_rq->avg.last_update_time; se->avg.period_contrib = cfs_rq->avg.period_contrib;
/* * Hell(o) Nasty stuff.. we need to recompute _sum based on the new * period_contrib. This isn't strictly correct, but since we're * entirely outside of the PELT hierarchy, nobody cares if we truncate * _sum a little. */ //2.上面衰减窗口对齐后,还需要重新计算sum se->avg.util_sum = se->avg.util_avg * divider; se->avg.runnable_sum = se->avg.runnable_avg * divider; se->avg.load_sum = divider; if (se_weight(se)) { se->avg.load_sum = div_u64(se->avg.load_avg * se->avg.load_sum, se_weight(se)); }
//3.将se的负载信息{load|runnable|util}_avg累加进cfs_rq enqueue_load_avg(cfs_rq, se); cfs_rq->avg.util_avg += se->avg.util_avg; cfs_rq->avg.util_sum += se->avg.util_sum; cfs_rq->avg.runnable_avg += se->avg.runnable_avg; cfs_rq->avg.runnable_sum += se->avg.runnable_sum;
add_tg_cfs_propagate(cfs_rq, se->avg.load_sum);
//4.触发调频 cfs_rq_util_change(cfs_rq, 0);
trace_pelt_cfs_tp(cfs_rq); } |
14.3.3 enqueue_load_avg - 将se的load_avg累加进cfs_rq
|
#ifdef CONFIG_SMP static inline void enqueue_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se) { cfs_rq->avg.load_avg += se->avg.load_avg; cfs_rq->avg.load_sum += se_weight(se) * se->avg.load_sum; } #else static inline void enqueue_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se) { } #endif |
14.3.4 attach_entity_cfs_rq在哪被调用
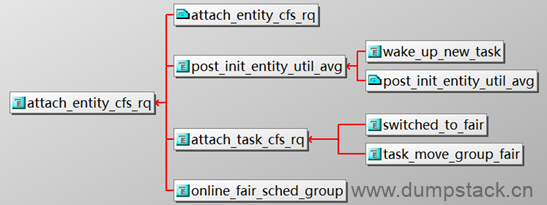
14.3.4.1 switched_to_fair - 切换task调度类时
当一个task从其他调度类切换至cfs调度类时,(一般是指用户空间通过系统调用的方式修改了一个task的属性,例如从rt切到cfs),执行完dequeue操作后,会调用下面的switched_to_fair操作,将se的负载信息{load|runnable|util}_{avg|sum}重新加入cfs_rq中
|
static void switched_to_fair(struct rq *rq, struct task_struct *p) { //1.将task的调度信息加进cfs_rq中 attach_task_cfs_rq(p);
if (task_on_rq_queued(p)) { /* * We were most likely switched from sched_rt, so * kick off the schedule if running, otherwise just see * if we can still preempt the current task. */ if (rq->curr == p) resched_curr(rq); else check_preempt_curr(rq, p, 0); } } |
14.3.4.2 task_move_group_fair - 切换task所属组时
当一个task从一个group切换到另一个group的时候,(例如一个task从前台推到后台时),执行完dequeue操作后,会调用到下面的task_move_group_fair操作,将se的负载信息{load|runnable|util}_{avg|sum}从cfs_rq中刨除
|
static void task_move_group_fair(struct task_struct *p) { //1.先将se的负载信息从旧的cfs_rq中摘除 detach_task_cfs_rq(p);
//2.修改cpu set_task_rq(p, task_cpu(p));
#ifdef CONFIG_SMP /* Tell se's cfs_rq has been changed -- migrated */ p->se.avg.last_update_time = 0; #endif //3.再将se的负载信息加入到新的cfs_rq中去 attach_task_cfs_rq(p); } |
14.3.4.3 task新创建,或者刚从其他cpu上迁移过来时
详细参见update_load_avg的实现
|
/* Update task and its cfs_rq load average */ static inline void update_load_avg( struct cfs_rq *cfs_rq, //要更新哪个cfs_rq的负载信息 struct sched_entity *se, //要更新哪个se的负载信息 int flags) //flags可取值如下 // a) UPDATE_TG: 是否更新task group的负载 // b) DO_ATTACH: 标记表示se被添加进队列 // c) SKIP_AGE_LOAD: 标记是否跳过本次负载统计 { ...
//1.该条件表示这是一个新创建或者刚迁移过来的线程 if (!se->avg.last_update_time && (flags & DO_ATTACH)) {
/* * DO_ATTACH means we're here from enqueue_entity(). * !last_update_time means we've passed through * migrate_task_rq_fair() indicating we migrated. * * IOW we're enqueueing a task on a new CPU. */ //2.不管是新创建的线程被加到cfs_rq,还是从别的cpu上刚迁移过来的一个 // 线程,总而言之,这个se是刚被挂到这个cfs_rq上的,此时需要将se的负 // 载信息{load|runnable|util}_{avg|sum}加到其所attach的cfs_rq中 attach_entity_load_avg(cfs_rq, se);
... } ... } |
14.4 reweight_entity - 权重发生变化时
|
static void reweight_entity( struct cfs_rq *cfs_rq, struct sched_entity *se, unsigned long weight) { //1.如果这个se现在还挂在cfs_rq队列上,则首先需要 // 将这个se的权重和负载从cfs_rq中移除 if (se->on_rq) { /* commit outstanding execution time */ //1.1 如果这个se是cfs_rq上正在运行的进程,那么他已经不在红黑树中 // 在移除之前需要先更新这个cfs_rq的运行时间信息 if (cfs_rq->curr == se) update_curr(cfs_rq);
//1.2 将se的权重weight从cfs_rq中删除 update_load_sub(&cfs_rq->load, se->load.weight); } //2.将se的负载load_{avg|sum}从cfs_rq中删除 dequeue_load_avg(cfs_rq, se);
//3.重新设置权重 update_load_set(&se->load, weight);
#ifdef CONFIG_SMP //4.使用新的权重,重新计算平均负载信息load_avg do { u32 divider = get_pelt_divider(&se->avg);
se->avg.load_avg = div_u64(se_weight(se) * se->avg.load_sum, divider); } while (0); #endif
//5.将se的负载load_{avg|sum}累加进cfs_rq enqueue_load_avg(cfs_rq, se);
//6.因为权重改了,所以这里需要重新将新的权重加到cfs_rq if (se->on_rq) update_load_add(&cfs_rq->load, se->load.weight);
} |
十五、cpu负载发生变化时触发调频
根组的cfs_rq的负载发生变化时,触发调频
15.1 cfs_rq_util_change - util发生变化,触发调频
调用cpufreq子系统的的回调函数
|
static inline void cfs_rq_util_change( struct cfs_rq *cfs_rq, int flags) //该标记有governor负责解析,目前内核中全部传入0 { struct rq *rq = rq_of(cfs_rq);
//因为在使能组调度时,每个group在每个cpu上都有自己的cfs_rq //而是否需要调整cpu的频率,我们只关注根组的cfs_rq上的负载信息的变化 //也就是说只有根组的cfs_rq的负载信息发生变化,才会触发cpu调频 if (&rq->cfs == cfs_rq) { /* * There are a few boundary cases this might miss but it should * get called often enough that that should (hopefully) not be * a real problem. * * It will not get called when we go idle, because the idle * thread is a different class (!fair), nor will the utilization * number include things like RT tasks. * * As is, the util number is not freq-invariant (we'd have to * implement arch_scale_freq_capacity() for that). * * See cpu_util(). */ cpufreq_update_util(rq, flags); } } |
15.2 cpufreq_update_util - 调用governor设置的回调函数,完成调频工作
|
#ifdef CONFIG_CPU_FREQ DECLARE_PER_CPU(struct update_util_data __rcu *, cpufreq_update_util_data); /** * cpufreq_update_util - Take a note about CPU utilization changes. * @rq: Runqueue to carry out the update for. * @flags: Update reason flags. * * This function is called by the scheduler on the CPU whose utilization is * being updated. * * It can only be called from RCU-sched read-side critical sections. * * The way cpufreq is currently arranged requires it to evaluate the CPU * performance state (frequency/voltage) on a regular basis to prevent it from * being stuck in a completely inadequate performance level for too long. * That is not guaranteed to happen if the updates are only triggered from CFS * and DL, though, because they may not be coming in if only RT tasks are * active all the time (or there are RT tasks only). * * As a workaround for that issue, this function is called periodically by the * RT sched class to trigger extra cpufreq updates to prevent it from stalling, * but that really is a band-aid. Going forward it should be replaced with * solutions targeted more specifically at RT tasks. */ static inline void cpufreq_update_util(struct rq *rq, unsigned int flags) { struct update_util_data *data;
//调用回调函数 data = rcu_dereference_sched(*per_cpu_ptr(&cpufreq_update_util_data, cpu_of(rq))); if (data) data->func(data, rq_clock(rq), flags); } #else static inline void cpufreq_update_util(struct rq *rq, unsigned int flags) {} #endif /* CONFIG_CPU_FREQ */ |
15.3 cpufreq_add_update_util_hook - 设置调频回调函数
cpufreq_update_util_data是一个全局变量,该值由各个cpufreq_governor自己来设置
|
/** * cpufreq_add_update_util_hook - Populate the CPU's update_util_data pointer. * @cpu: The CPU to set the pointer for. * @data: New pointer value. * @func: Callback function to set for the CPU. * * Set and publish the update_util_data pointer for the given CPU. * * The update_util_data pointer of @cpu is set to @data and the callback * function pointer in the target struct update_util_data is set to @func. * That function will be called by cpufreq_update_util() from RCU-sched * read-side critical sections, so it must not sleep. @data will always be * passed to it as the first argument which allows the function to get to the * target update_util_data structure and its container. * * The update_util_data pointer of @cpu must be NULL when this function is * called or it will WARN() and return with no effect. */ void cpufreq_add_update_util_hook(int cpu, struct update_util_data *data, void (*func)(struct update_util_data *data, u64 time, unsigned int flags)) { if (WARN_ON(!data || !func)) return;
if (WARN_ON(per_cpu(cpufreq_update_util_data, cpu))) return;
data->func = func; rcu_assign_pointer(per_cpu(cpufreq_update_util_data, cpu), data); } |
15.4 sugov_start - schedutil设置调频回调函数
|
static int sugov_start(struct cpufreq_policy *policy) { ...
for_each_cpu(cpu, policy->cpus) { struct sugov_cpu *sg_cpu = &per_cpu(sugov_cpu, cpu);
cpufreq_add_update_util_hook(cpu, &sg_cpu->update_util, policy_is_shared(policy) ? sugov_update_shared : sugov_update_single); } return 0; } |
十六、本章涉及函数
16.1 mul_u64_u32_shr - 计算(a*mul)>>shift
|
static inline u64 mul_u64_u32_shr(u64 a, u32 mul, unsigned int shift) { return (u64)(((unsigned __int128)a * mul) >> shift); } |
16.2 scale_load/scale_load_down - 为了在64位平台上增加nice值的分辨率
下面的函数实现主要是为了,在64位平台上为了增加nice值的分辨率,详细请看一下下面的注释
32位平台上直接返回权重
|
/* * Increase resolution of nice-level calculations for 64-bit architectures. * The extra resolution improves shares distribution and load balancing of * low-weight task groups (eg. nice +19 on an autogroup), deeper taskgroup * hierarchies, especially on larger systems. This is not a user-visible change * and does not change the user-interface for setting shares/weights. * * We increase resolution only if we have enough bits to allow this increased * resolution (i.e. 64-bit). The costs for increasing resolution when 32-bit * are pretty high and the returns do not justify the increased costs. * * Really only required when CONFIG_FAIR_GROUP_SCHED=y is also set, but to * increase coverage and consistency always enable it on 64-bit platforms. */ #ifdef CONFIG_64BIT # define NICE_0_LOAD_SHIFT (SCHED_FIXEDPOINT_SHIFT + SCHED_FIXEDPOINT_SHIFT) # define scale_load(w) ((w) << SCHED_FIXEDPOINT_SHIFT) # define scale_load_down(w) ((w) >> SCHED_FIXEDPOINT_SHIFT) #else # define NICE_0_LOAD_SHIFT (SCHED_FIXEDPOINT_SHIFT) # define scale_load(w) (w) # define scale_load_down(w) (w) #endif
/* * Task weight (visible to users) and its load (invisible to users) have * independent resolution, but they should be well calibrated. We use * scale_load() and scale_load_down(w) to convert between them. The * following must be true: * * scale_load(sched_prio_to_weight[USER_PRIO(NICE_TO_PRIO(0))]) == NICE_0_LOAD * */ //注意,在32位系统上NICE_0_LOAD为32, //但是在64位系统,NICE_0_LOAD为1<<20 = 1048576 #define NICE_0_LOAD (1L << NICE_0_LOAD_SHIFT)
其中: /* * Integer metrics need fixed point arithmetic, e.g., sched/fair * has a few: load, load_avg, util_avg, freq, and capacity. * * We define a basic fixed point arithmetic range, and then formalize * all these metrics based on that basic range. */ # define SCHED_FIXEDPOINT_SHIFT 10 # define SCHED_FIXEDPOINT_SCALE (1L << SCHED_FIXEDPOINT_SHIFT) |
16.3 sub_positive - 减,防止溢出
|
/* * Unsigned subtract and clamp on underflow. * * Explicitly do a load-store to ensure the intermediate value never hits * memory. This allows lockless observations without ever seeing the negative * values. */ #define sub_positive(_ptr, _val) do { \ typeof(_ptr) ptr = (_ptr); \ typeof(*ptr) val = (_val); \ typeof(*ptr) res, var = READ_ONCE(*ptr); \ res = var - val; \ if (res > var) \ res = 0; \ WRITE_ONCE(*ptr, res); \ } while (0) |
十七、参考文档
https://zhuanlan.zhihu.com/p/158185705
http://www.wowotech.net/process_management/450.html
https://blog.csdn.net/wukongmingjing/article/details/82531950
http://www.wowotech.net/process_management/pelt.html

文章评论
非常不错的文章,写的通俗易通,看的很明白,非常感谢分享