关注公众号不迷路:DumpStack
扫码加关注

目录
- 一、前言
- 二、数据结构中关键成员解释
- 三、支持组调度时,各个数据结构之间的拓扑关系
- 四、组调度策略
- 五、group的权重:shares - 被所有gse瓜分
- 六、附:组调度时的组织架构
- 6.1 entity_is_task - 判断这个se结构是不是一个task
- 6.2 group_cfs_rq - 返回gse对应的grq结构
- 6.3 is_same_group - 判断两个se是否在同一个group中
- 6.4 cfs_rq_of - 得到这个se被挂在哪个cfs_rq运行队列上
- 6.5 task_cfs_rq - 得到这个任务p被挂在哪个cfs_rq队列上
- 6.6 task_of - 由se返回对应的task_struct结构
- 6.7 rq_of - 已知运行队列cfs_rq,返回其所属的rq结构
- 6.8 parent_entity - 返回se的父节点
- 6.9 for_each_sched_entity - 支持组调度的时候,逐层遍历祖先的gse结构
- 6.10 find_matching_se - 层层向上,直到这两个se在同一个cfs_rq树中,也就是说在同一个组中
- 关注公众号不迷路:DumpStack
术语约定:
gse: group se
grq: group cfs_rq
tg: task_group
一、前言
1.1 为什么要引入组调度
Linux调度器的粒度是一个进程,这样的粒度在很多场景是不合适的,比如,希望达到用户粒度,也就是希望每个用户占有相同的cpu时间。但是,在各个用户拥有的进程数量不同的情况下,显然调度器会将cpu更多地分配给进程数量多的用户。组调度的引入,正是解决此问题的
linux的cgroup(control group)支持将进程分组,然后按组来划分各种资源,例如group1拥有30%的CPU和50%的磁盘IO,group2拥有10%的CPU和20%的磁盘IO等等
组调度就是通过cgroup子系统实现的,cgroup支持很多种资源的划分,CPU资源就是其中之一,可以将进程进行分组,按组来分配CPU资源等
例如A和B两个用户使用同一台机器,A用户16个进程,B用户2个进程,如果按照进程的个数来分配CPU资源,显然A用户会占据大量的CPU时间,这对于B用户是不公平的。组调度就可以解决这个问题,分别将A、B用户进程划分成两个组,调度器先从两个组中选择一个组,再从选中的组中选择一个进程来执行,如果两个组被选中的机率相当,即两个组的权重相同,那么用户A和B将各占有约50%的CPU。
下面举个例子,如下图,系统中共有5个线程,如果没有组调度的话,则5个线程均分cpu时间,每个占用20%。如果对这5个线程进程分组,其中task1~4归属groupA,task5归属于groupB,并且两个组的权重是不一样的,shares值分别是1024和4096,那么各个任务分到的时间如下:
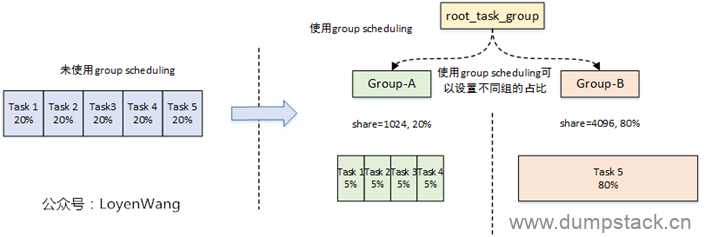
总结:引入组调度,是为了实现将进程分组,按分组来进行CPU资源分配
1.2 为什么Linux中调度的单位是sched_entity而不是task_struct?
Linux使用task_struct结构体描述一个进程,但是调度的单位却是调度实体sched_entity,并不是task_struct,为什么呢?
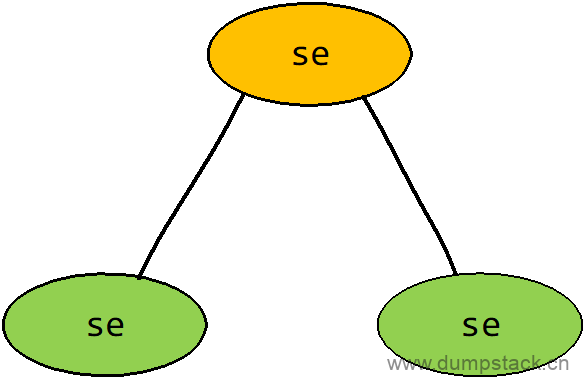
这主要是为了方便支持组调度扩展,如果不支持组调度的话,确实可以使用task_struct作为调度的单位。当支持组调度的时候,是按组来分配运行时间的。在支持组调度的时候,一个组也会抽象成一个调度实体,如下图所示,黄色的圈表示group,只有se结构,没有task_struct结构,而绿色的每个圈即对应一个se结构,也对应一个task_struct结构
CFS调度器管理的是sched_entity调度实体,task_struct(代表线程)和task_group(代表线程组,即进程)中都包含sched_entity,进而来参与调度;
二、数据结构中关键成员解释
下面这个图是相当生动了
参考文档:https://blog.csdn.net/ctthuangcheng/article/details/8914825
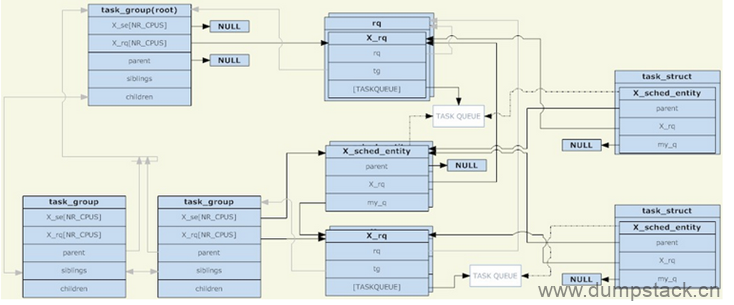
2.1 task_group中的X_se[]和X_rq[]
一个task_group可以包含具有任意类别的进程(实际目前只支持对cfs和rt两种进程进行分组,这一点从"task_group数据结构中只包含cfs和rt的调度实体和就绪队列"可以看出),于是task_group需要为每一种进程提供一组"调度相关的结构",这里所说的一组"调度相关的结构"主要包括两个部分:调度实体和运行队列,也就是task_group数据结构中的X_se[]和X_rq[],两者都是per-cpu的。在cpuN上这个组中的所有任务对应的调度实体会被添加到运行队列X_rq[N]中,而在第N个cpu上,task_group自身也有一个调度实体X_se[N],它的调度实体会被添加到其父task_group的运行队列,(实际上这个group对应的调度实体se是一个数组,即X_se[],当要把这个group对应的se挂到指定的cpu对应的队列中时,是把对应的X_se[N]结构挂入cpuN对应的链表中;而当在cpuN上,在这个组内pick任务时,实际上是在X_rq[N]中pick任务)
2.2 se中的my_q和X_rq成员
这里说的调度实体se包括sched_entity和sched_rt_entity
my_q成员,表示这个se对应的cfs_rq和rt_rq结构
-
如果调度实体代表group,则my_q字段指向这个组对应的运行队列,也就是task_group结构中的X_rq[N]结构,用于挂载这个组在这个cpu上所有等待调度的任务
-
如果调度实体代表task时,则my_q字段为NULL
entity_is_task就是根据my_q来判断entity是表示task还是group的
X_rq成员,表示这个se所属的cfs_rq或rq_rq
-
如果调度实体代表group,则X_rq表示这个组对应的se会被挂在哪个运行队列被调度
-
如果调度实体代表task,则X_rq表示这个tase对应的se应该被挂在哪个运行队列被调度
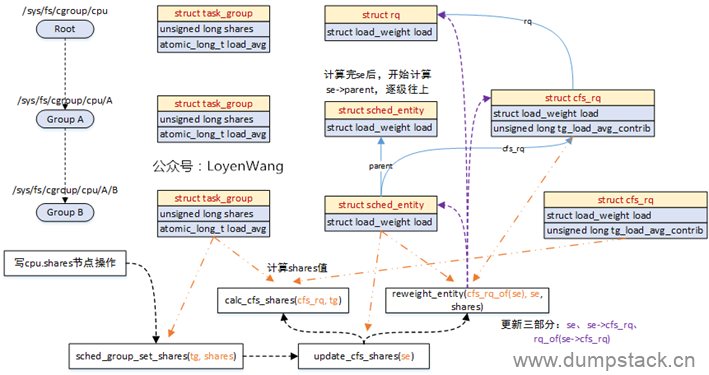
三、支持组调度时,各个数据结构之间的拓扑关系
3.1 拓扑结构图
a) 各数据结构之间的拓扑关系
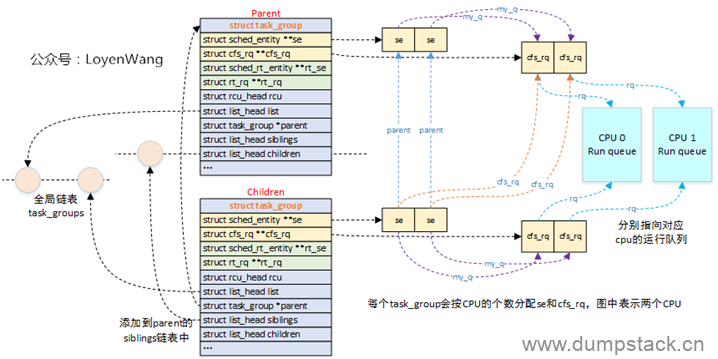
支持组调度时,各数据结构之间的拓扑结构如下:
从上面图中,我们主要关注以下几点:
-
内核维护了一个全局链表task_groups,系统中的所有task_group都会被添加到这个链表中;
-
内核还定义了一个root_task_group全局变量,作为系统的根组,也是系统中所有task_group树形结构的根;
-
task_group数据结构的子节点,会加入到父节点的siblings链表中;
-
每个task_group会分配就绪队列数组和调度实体数组,其中数组的个数为系统CPU的个数,也就是为每个CPU都分配了运行队列和调度实体;
b) 各数据结构之间的拓扑关系
假设系统包含4个CPU,组调度的打开的情况下,各种结构体之间的关系如下图。
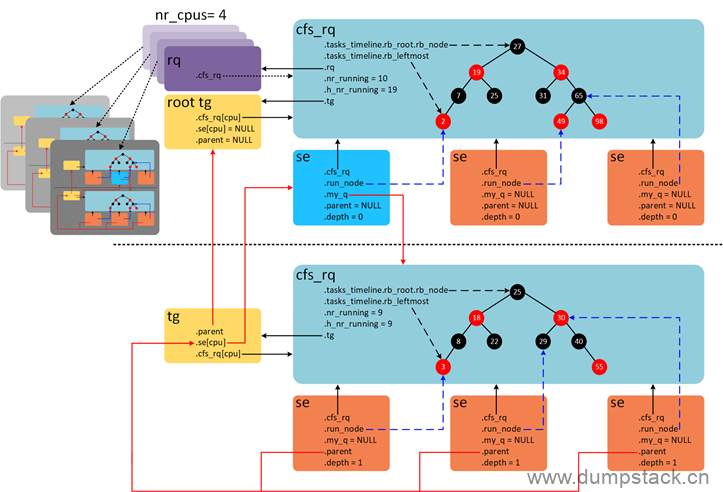
通过上面的示意图,可以获取以下信息
-
系统中的所有task_group结构会形成一个树形结构,该树形结构的根为root_task_group,对应上图黄色的root tg,注意到root tg的se和parent都是NULL,root tg的cfs_rq[cpu_id]指向这个cpu对应的rq.cfs_rq
-
一个组只对应一个task_group结构,但是这个组在每个cpu上都有一个group se结构,记录在task_group.se[cpu_id]中
-
在每个CPU上都有一个全局的就绪队列struct rq结构,对应上图的紫色rq,有多少个CPU就有多少个全局就绪队列rq,rq->cfs_rq指向这个cpu上的根cfs_rq就绪队列
-
每个cpu都有自己的根cfs_rq就绪队列,有多少个cpu就有多少个这样的根cfs_rq就绪队列,根cfs_rq就绪队列中维护一棵红黑树,上图中红黑树上一共10个就绪态调度实体,其中9个是task se(上图橘色se),1个group se(上图蓝色se)
-
蓝色group se的my_q成员指向这个group自己对应的csf_rq就绪队列,该csf_rq就绪队列上也有一个红黑树,该红黑树上共9个task se,这9个task se的parent成员的指向和task_group.se[cpu_id](即下面这个黄色的tg)的指向一致,即都是指向group se(对应上图蓝色的group se),用于标记自己所属的组;
-
每个group se(蓝色se)都有自己的group cfs_rq,有多少个CPU就会有多少个group se和group cfs_rq,分别存储在task_group.se[]和task_group.cfs_rq[]中
-
task se的depth成员记录se嵌套深度,最顶层cfs_rq就绪队列下的se的深度为0,group se往下一层层递增
-
cfs_rq->nr_runing成员记录当前cfs_rq就绪队列所有调度实体个数,不包含子就绪队列
-
cfs_rq->h_nr_running成员记录就绪队列层级上所有调度实体的个数,包含group se对应group cfs_rq上的调度实体。例如,图中上半部,nr_runing和h_nr_running的值分别等于10和19,多出的9是group cfs_rq的h_nr_running。group cfs_rq中由于没有group se,因此nr_runing和h_nr_running的值都等于9
c) 组调度时,se的拓扑关系
对应到实际的运行中,如下:
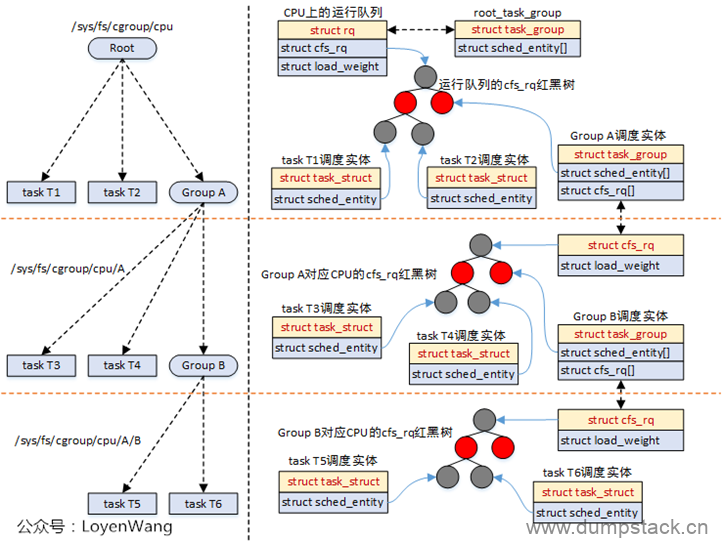
-
struct cfs_rq包含了红黑树结构,sched_entity调度实体参与调度时,都会挂入到红黑树中,task_struct和task_group都属于被调度对象;
-
task_group会为每个CPU再维护一个cfs_rq,这个cfs_rq用于组织挂在这个任务组上的任务以及子任务组,参考图中的Group A;
-
调度器在调度的时候,比如调用pick_next_task_fair时,会从遍历队列,选择sched_entity,如果发现sched_entity对应的是task_group,则会继续往下选择;
-
由于sched_entity结构中存在parent指针,指向它的父结构,因此,系统的运行也能从下而上的进行遍历操作,通常使用函数walk_tg_tree_from进行遍历;
3.1 root_task_group - 根组
根组就是一个静态定义的task_group数据结构
文件位置:W:\opensource\linux-5.10.61\kernel\sched\core.c
|
/* * Default task group. * Every task in system belongs to this group at bootup. */ struct task_group root_task_group; |
3.2 task_groups - 全局链表,系统中所有group都挂在该链表上
文件位置:W:\opensource\linux-5.10.61\kernel\sched\core.c
|
LIST_HEAD(task_groups); |
3.5 sched_create_group - 创建一个新的group
|
/* allocate runqueue etc for a new task group */ struct task_group *sched_create_group( struct task_group *parent) //指定新创建的group的parent { struct task_group *tg;
//1.动态申请group结构,注意根组是静态定义的 tg = kmem_cache_alloc(task_group_cache, GFP_KERNEL | __GFP_ZERO); if (!tg) return ERR_PTR(-ENOMEM);
//2.cfs相关处理 if (!alloc_fair_sched_group(tg, parent)) goto err;
//3.rt相关处理 if (!alloc_rt_sched_group(tg, parent)) goto err;
//4.uclamp相关初始化 alloc_uclamp_sched_group(tg, parent);
return tg;
err: sched_free_group(tg); return ERR_PTR(-ENOMEM); } |
3.6 alloc_fair_sched_group - cfs组调度相关初始化
文件位置:W:\opensource\linux-5.10.61\kernel\sched\fair.c
|
int alloc_fair_sched_group(struct task_group *tg, struct task_group *parent) { struct sched_entity *se; struct cfs_rq *cfs_rq; int i;
//1.为group中的X_se[]和X_rq[]申请空间 // 注意: // a) X_se[]和X_rq[]中存放的是地址,并不是真正的cfs_rq和sched_entity空间 // b) 这个group在每个cpu上都有自己的X_se和X_rq结构 tg->cfs_rq = kcalloc(nr_cpu_ids, sizeof(cfs_rq), GFP_KERNEL); if (!tg->cfs_rq) goto err; tg->se = kcalloc(nr_cpu_ids, sizeof(se), GFP_KERNEL); if (!tg->se) goto err;
//2.新创建的group的shares值默认为1024 tg->shares = NICE_0_LOAD;
//3.带宽初始化,暂不分析 init_cfs_bandwidth(tg_cfs_bandwidth(tg));
//4.初始化这个组在每个cpu上的se结构 for_each_possible_cpu(i) { //4.1 为这个组在每个cpu上申请一个cfs_rq和sched_entity结构 cfs_rq = kzalloc_node(sizeof(struct cfs_rq), GFP_KERNEL, cpu_to_node(i)); if (!cfs_rq) goto err;
se = kzalloc_node(sizeof(struct sched_entity), GFP_KERNEL, cpu_to_node(i)); if (!se) goto err_free_rq;
//4.2 对cfs_rq结构进行简单的初始化 init_cfs_rq(cfs_rq);
//4.3 指定这个group在这个cpu上的cfs_rq和se结构,并指定parent init_tg_cfs_entry(tg, cfs_rq, se, i, parent->se[i]); init_entity_runnable_average(se); }
return 1;
err_free_rq: kfree(cfs_rq); err: return 0; } |
3.6.1 init_cfs_rq - 初始化cfs_rq结构
|
void init_cfs_rq(struct cfs_rq *cfs_rq) { cfs_rq->tasks_timeline = RB_ROOT_CACHED; cfs_rq->min_vruntime = (u64)(-(1LL << 20)); #ifndef CONFIG_64BIT cfs_rq->min_vruntime_copy = cfs_rq->min_vruntime; #endif #ifdef CONFIG_SMP raw_spin_lock_init(&cfs_rq->removed.lock); #endif } |
3.3.1 init_tg_cfs_entry
下面的代码实现结合上面的拓扑结构图一起看
注意:根组传入的se和parent为NULL
|
void init_tg_cfs_entry( struct task_group *tg, //要初始化的group struct cfs_rq *cfs_rq, //这个组在这个cpu上对应的grq结构 struct sched_entity *se, //这个组在这个cpu上对应的gse结构,根组没有se结构 int cpu, //哪个cpu struct sched_entity *parent) //parent在这个cpu上对应的gse结构,根组为空 { struct rq *rq = cpu_rq(cpu);
cfs_rq->tg = tg; cfs_rq->rq = rq; init_cfs_rq_runtime(cfs_rq);
//1.每个group在每个cpu上都有自己的cfs_rq和se结构 tg->cfs_rq[cpu] = cfs_rq; tg->se[cpu] = se;
/* se could be NULL for root_task_group */ //2.为NULL说明初始化的是根组 if (!se) return;
//3.代码走到这里,说明初始化的不是根组,根组没有se结构,无需进行下面的初始化
//4.下面初始化se所属的cfs_rq // 若entity表示group,cfs_rq表示"这个group在第N个cpu // 上的se结构"被挂在哪个cfs_rq队列中, // 若entity表示task,cfs_rq表示这个se所属的cfs_rq if (!parent) { //这个分支难道表示和根组并列的组吗??? se->cfs_rq = &rq->cfs; se->depth = 0; } else { se->cfs_rq = parent->my_q; se->depth = parent->depth + 1; }
//5.下面初始化这个gse对应的cfs_rq结构 //若entity表示一个task,则my_q为NULL //若entity表示一个group,则my_q指向这个组对应的task_group // 结构中的cfs_rq[N]成员,N表示cpu编号 //entity_is_task就是根据这个变量来判断entity是表示task还是group的 se->my_q = cfs_rq;
/* guarantee group entities always have weight */ //6.权重初始化为1024 update_load_set(&se->load, NICE_0_LOAD);
//7.指定parent se->parent = parent; } |
3.7 alloc_rt_sched_group - rt组调度相关初始化
|
int alloc_rt_sched_group(struct task_group *tg, struct task_group *parent) { struct rt_rq *rt_rq; struct sched_rt_entity *rt_se; int i;
//1.为group中的X_se[]和X_rq[]申请空间 // 注意: // a) X_se[]和X_rq[]中存放的是地址,并不是真正的rt_rq和sched_rt_entity空间 // b) 这个group在每个cpu上都有自己的X_se和X_rq结构 tg->rt_rq = kcalloc(nr_cpu_ids, sizeof(rt_rq), GFP_KERNEL); if (!tg->rt_rq) goto err; tg->rt_se = kcalloc(nr_cpu_ids, sizeof(rt_se), GFP_KERNEL); if (!tg->rt_se) goto err;
//2.带宽初始化 init_rt_bandwidth(&tg->rt_bandwidth, ktime_to_ns(def_rt_bandwidth.rt_period), 0);
//3.初始化这个组在每个cpu上的se结构 for_each_possible_cpu(i) { //3.1 为这个组在每个cpu上申请一个rt_rq和sched_rt_entity结构 rt_rq = kzalloc_node(sizeof(struct rt_rq), GFP_KERNEL, cpu_to_node(i)); if (!rt_rq) goto err;
rt_se = kzalloc_node(sizeof(struct sched_rt_entity), GFP_KERNEL, cpu_to_node(i)); if (!rt_se) goto err_free_rq;
//3.2 对rt_rq结构完成简单的初始化 init_rt_rq(rt_rq); rt_rq->rt_runtime = tg->rt_bandwidth.rt_runtime;
//3.3 指定这个group在这个cpu上的rt_rq和se结构,并指定parent init_tg_rt_entry(tg, rt_rq, rt_se, i, parent->rt_se[i]); }
return 1;
err_free_rq: kfree(rt_rq); err: return 0; } |
3.3.2 init_rt_rq - 初始化rt_rq结构
|
void init_rt_rq(struct rt_rq *rt_rq) { struct rt_prio_array *array; int i;
array = &rt_rq->active; for (i = 0; i < MAX_RT_PRIO; i++) { INIT_LIST_HEAD(array->queue + i); __clear_bit(i, array->bitmap); } /* delimiter for bitsearch: */ __set_bit(MAX_RT_PRIO, array->bitmap);
#if defined CONFIG_SMP rt_rq->highest_prio.curr = MAX_RT_PRIO; rt_rq->highest_prio.next = MAX_RT_PRIO; rt_rq->rt_nr_migratory = 0; rt_rq->overloaded = 0; plist_head_init(&rt_rq->pushable_tasks); #endif /* CONFIG_SMP */ /* We start is dequeued state, because no RT tasks are queued */ rt_rq->rt_queued = 0;
rt_rq->rt_time = 0; rt_rq->rt_throttled = 0; rt_rq->rt_runtime = 0; raw_spin_lock_init(&rt_rq->rt_runtime_lock); } |
3.3.2 init_tg_rt_entry
|
void init_tg_rt_entry( struct task_group *tg, //要初始化的group struct rt_rq *rt_rq, //这个组在这个cpu上对应的rt_rq结构 struct sched_rt_entity *rt_se, //这个组在这个cpu上对应的se结构,根组没有se结构 int cpu, //哪个cpu struct sched_rt_entity *parent) //parent在这个cpu上对应的se结构,根组为空 { struct rq *rq = cpu_rq(cpu);
rt_rq->highest_prio.curr = MAX_RT_PRIO; rt_rq->rt_nr_boosted = 0; rt_rq->rq = rq; rt_rq->tg = tg;
//1.每个group在每个cpu上都有自己的rt_rq和se结构 tg->rt_rq[cpu] = rt_rq; tg->rt_se[cpu] = rt_se;
//2.为NULL说明初始化的是根组 if (!rt_se) return;
//3.代码走到这里,说明初始化的不是根组,根组没有se结构,无需进行下面的初始化
//4.下面初始化se所属的运行队列 //若entity表示group,rt_rq表示"这个group在第N个cpu // 上的se结构"被挂在哪个运行队列中 //若entity表示task,rt_rq表示这个se应该被放入的运行队列 if (!parent) rt_se->rt_rq = &rq->rt; else rt_se->rt_rq = parent->my_q;
//5.这个se对应的rt_rq结构 //若entity表示一个task,则my_q为NULL //若entity表示一个group,则my_q指向这个组对应的task_group // 结构中的rt_rq[N]成员,N表示cpu编号 //entity_is_task就是根据这个变量来判断entity是表示task还是group的 rt_se->my_q = rt_rq;
//6.指定parent rt_se->parent = parent; INIT_LIST_HEAD(&rt_se->run_list); } |
3.3 sched_init - 对根组的初始化
这里我们只关注组调度相关的操作,其他部分暂时忽略
|
void __init sched_init(void) { unsigned long ptr = 0; ...
//1.为根组task_group结构中的X_se[]和X_rq[]结构申请空间 // 注意:一个组,在每个cpu上都有自己的X_se和X_rq结构,所以要使用数组来描述 #ifdef CONFIG_FAIR_GROUP_SCHED ptr += 2 * nr_cpu_ids * sizeof(void **); #endif #ifdef CONFIG_RT_GROUP_SCHED ptr += 2 * nr_cpu_ids * sizeof(void **); #endif if (ptr) { ptr = (unsigned long)kzalloc(ptr, GFP_NOWAIT);
#ifdef CONFIG_FAIR_GROUP_SCHED root_task_group.se = (struct sched_entity **)ptr; ptr += nr_cpu_ids * sizeof(void **);
root_task_group.cfs_rq = (struct cfs_rq **)ptr; ptr += nr_cpu_ids * sizeof(void **);
root_task_group.shares = ROOT_TASK_GROUP_LOAD; //默认值为1024 init_cfs_bandwidth(&root_task_group.cfs_bandwidth); #endif #ifdef CONFIG_RT_GROUP_SCHED root_task_group.rt_se = (struct sched_rt_entity **)ptr; ptr += nr_cpu_ids * sizeof(void **);
root_task_group.rt_rq = (struct rt_rq **)ptr; ptr += nr_cpu_ids * sizeof(void **); #endif } ...
//2.带宽控制相关,暂不分析 #ifdef CONFIG_RT_GROUP_SCHED init_rt_bandwidth(&root_task_group.rt_bandwidth, global_rt_period(), global_rt_runtime()); #endif
//3.将根组对应的task_group结构加入全局链表task_groups中 #ifdef CONFIG_CGROUP_SCHED list_add(&root_task_group.list, &task_groups); INIT_LIST_HEAD(&root_task_group.children); INIT_LIST_HEAD(&root_task_group.siblings); #endif /* CONFIG_CGROUP_SCHED */
//4.对每个cpu的rq for_each_possible_cpu(i) { struct rq *rq; rq = cpu_rq(i);
... #ifdef CONFIG_FAIR_GROUP_SCHED /* * How much CPU bandwidth does root_task_group get? * * In case of task-groups formed thr' the cgroup filesystem, it * gets 100% of the CPU resources in the system. This overall * system CPU resource is divided among the tasks of * root_task_group and its child task-groups in a fair manner, * based on each entity's (task or task-group's) weight * (se->load.weight). * * In other words, if root_task_group has 10 tasks of weight * 1024) and two child groups A0 and A1 (of weight 1024 each), * then A0's share of the CPU resource is: * * A0's bandwidth = 1024 / (10*1024 + 1024 + 1024) = 8.33% * * We achieve this by letting root_task_group's tasks sit * directly in rq->cfs (i.e root_task_group->se[] = NULL). */ init_tg_cfs_entry(&root_task_group, &rq->cfs, NULL, i, NULL); #endif /* CONFIG_FAIR_GROUP_SCHED */
#ifdef CONFIG_RT_GROUP_SCHED init_tg_rt_entry(&root_task_group, &rq->rt, NULL, i, NULL); #endif ... }
... } |
3.4 sched_online_group - 新增一个组
|
void sched_online_group( struct task_group *tg, //新增的task_group结构 struct task_group *parent) //指定parent { unsigned long flags;
spin_lock_irqsave(&task_group_lock, flags);
//1.系统中所有的group都挂在全局链表task_group上 list_add_rcu(&tg->list, &task_groups);
/* Root should already exist: */ WARN_ON(!parent);
//2.形成拓扑结构,这里参见上面的图 tg->parent = parent; INIT_LIST_HEAD(&tg->children); list_add_rcu(&tg->siblings, &parent->children); spin_unlock_irqrestore(&task_group_lock, flags);
online_fair_sched_group(tg); } |
3.5 sched_offline_group
|
void sched_offline_group(struct task_group *tg) { unsigned long flags;
/* End participation in shares distribution: */ unregister_fair_sched_group(tg);
spin_lock_irqsave(&task_group_lock, flags); list_del_rcu(&tg->list); list_del_rcu(&tg->siblings); spin_unlock_irqrestore(&task_group_lock, flags); } |
四、组调度策略
组调度的主要数据结构已经理清了,这里还有一个很重要的问题。我们知道task拥有其对应的优先级(静态优先级 or 动态优先级),调度程序根据优先级来选择运行队列中的进程。那么,既然task_group和task一样,都被抽象成调度实体,接受同样的调度,task_group的优先级又该如何定义呢?这个问题需要具体到调度类别来解答(因为不同的调度类别,其优先级定义方式不一样),具体来说就是rt和cfs两种类别
4.1 rt进程的组调度
rt线程的优先级是跟具体任务相关的,完全由用户来定义的,调度器总是会选择优先级最高的实时进程来运行。
发展到组调度,组的优先级就被定义为"组内最高优先级的进程所拥有的优先级"。比如组内有三个优先级分别为10、20、30的进程,则组的优先级就是10(数值越小优先级越大)。
组的优先级如此定义,引出了一个有趣的现象。当task入队或者出队时,要把它的所有祖先节点都先出队,然后再重新由底向上依次入队。因为组节点的优先级是依赖于它的子节点的,task的入队和出队将影响它的每一个祖先节点。
于是,当调度程序从根节点的task_group出发选择调度实体时,总是能沿着正确的路径,找到所有TASK_RUNNING状态的实时进程中优先级最高的那一个。这个实现似乎理所当然,但是仔细想想,这样一来,将实时进程分组还有什么意义呢?无论分组与否,调度程序要做的事情都是"在所有TASK_RUNNING状态的实时进程中选择优先级最高的那一个"。这里似乎还缺了些什么……
现在需要先介绍一下linux系统中的两个proc文件:/proc/sys/kernel/sched_rt_period_us和/proc/sys/kernel/sched_rt_runtime_us。这两个文件规定了,在以sched_rt_period_us为一个周期的时间内,所有实时进程的运行时间之和不超过sched_rt_runtime_us。这两个文件的默认值是1s和0.95s,表示每秒种为一个周期,在这个周期中,所有实时进程运行的总时间不超过0.95秒,剩下的至少0.05秒会留给普通进程。也就是说,实时进程占有不超过95%的CPU。而在这两个文件出现之前,实时进程的运行时间是没有限制的(就像《linux进程调度浅析》里面描述的那样),如果一直有处于TASK_RUNNING状态的实时进程,则普通进程会一直不能得到运行。相当于sched_rt_runtime_us等于sched_rt_period_us。
为什么要有sched_rt_runtime_us和sched_rt_period_us两个变量呢?直接使用一个表示CPU占有百分比的变量不可以么?我想这应该是由于很多实时进程实际上都是周期性地在干某件事情,比如某语音程序每20ms发送一个语音包、某视频程序每40ms刷新一帧、等等。周期是很重要的,仅仅使用一个宏观的CPU占有比无法准确描述实时进程需求。
而实时进程的分组就把sched_rt_runtime_us和sched_rt_period_us的概念扩展了,每个task_group都有自己的sched_rt_runtime_us和sched_rt_period_us,(使用的变量依然是那两个全局变量),保证自己组内的进程在以sched_rt_period_us为周期的时间内,最多只能运行sched_rt_runtime_us这么多时间。CPU占有比为sched_rt_runtime_us/sched_rt_period_us。
对于根节点的task_group,它的sched_rt_runtime_us和sched_rt_period_us就等于上面两个proc文件中的值。而对于一个task_group节点来说,假设它下面有n个调度子组和m个TASK_RUNNING状态的进程,这个组的CPU占有比为A、这n个子组的CPU占有比为B,则B必须小于等于A,而A-B剩下的CPU时间将分给那m个TASK_RUNNING状态的进程。(这里讨论的是CPU占有比,因为每个调度组可能有着不同的周期值。)
为了实现sched_rt_runtime_us和sched_rt_period_us的逻辑,内核在更新进程的运行时间的时候(比如由周期性的时钟中断触发的时间更新)会给当前进程的调度实体及其所有祖先节点都增加相应的runtime。如果一个调度实体达到了sched_rt_runtime_us所限定的时间,则将其从对应的运行队列中剔除,并将对应的rt_rq置throttled状态。在这个状态下,这个rt_rq对应的调度实体不会再次进入运行队列。而每个rt_rq都会维护一个周期性的定时器,定时周期为sched_rt_period_us。每次定时器触发,其对应的回调函数就会将rt_rq的runtime减去一个sched_rt_period_us单位的值(但要保持runtime不小于0),然后将rt_rq从throttled状态中恢复回来。
还有一个问题,前面说到,默认情况下,系统中每秒钟内实时进程的运行时间不超过0.95秒。如果实时进程实际对CPU的需求不足0.95秒(大于等于0秒、小于0.95秒),则剩下的时间都会分配给普通进程。而如果实时进程的对CPU的需求大于0.95秒,它也只能够运行0.95秒,剩下的0.05秒会分给其他普通进程。但是,如果这0.05秒内没有任何普通进程需要使用CPU(一直没有TASK_RUNNING状态的普通进程)呢?这种情况下既然普通进程对CPU没有需求,实时进程是否可以运行超过0.95秒呢?不能。在剩下的0.05秒中内核宁可让CPU一直闲着,也不让实时进程使用。可见sched_rt_runtime_us和sched_rt_period_us是很有强制性的。
最后还有多CPU的问题,前面也提到,对于每一个task_group,它的调度实体和运行队列是percpu的。而sched_rt_runtime_us和sched_rt_period_us是作用在调度实体上的,所以如果系统中有N个CPU,实时进程实际占有CPU的上限N*sched_rt_runtime_us/sched_rt_period_us。也就是说,尽管默认情况下限制了每秒钟之内,实时进程只能运行0.95秒。但是对于某个实时进程来说,如果CPU有两个核,也还是能满足它100%占有CPU的需求的(比如执行死循环)。然后,按道理说,这个实时进程占有的100%的CPU应该是由两部分组成的(每个CPU占有一部分,但都不超过95%)。但是实际上,为了避免进程在CPU间的迁移导致上下文切换、缓存失效等一系列问题,一个CPU上的调度实体可以向另一个CPU上对应的调度实体借用时间。其结果就是,宏观上既满足了sched_rt_runtime_us的限制,又避免了进程的迁移
4.2 cfs进程的组调度
文章一开头提到了希望A、B两个用户在进程数不相同的情况下也能平分CPU的需求,但是上面关于实时进程的组调度策略好像与此不太相干,其实这就是普通进程的组调度所要干的事。
相比实时进程,普通进程的组调度就没有这么多讲究。组被看作是跟进程几乎完全相同的实体,它拥有自己的静态优先级、调度程序也动态地调整它的优先级。对于一个组来说,组内进程的优先级并不影响组的优先级,只有这个组被调度程序选中时,这些进程的优先级才被考虑。
为了设置组的优先级,每个task_group都有一个shares参数(跟前面提到的sched_rt_runtime_us和sched_rt_period_us两个参数并列)。shares并不是优先级,而是调度实体的权重(这是CFS调度器的玩法),这个权重和优先级是有一一对应的关系的。普通进程的优先级也会被转换成其对应调度实体的权重,所以可以说shares就代表了优先级。
shares的默认值跟普通进程默认优先级对应的权重是一样的。所以在默认情况下,组和进程是平分CPU的。
task和group都有权重的概念,调度器会根据权重来分配cpu的时间,task_group的shares值就是该group的权重。想想cfs中的进程,其权重需要从优先级转化而来,而task_group就简单了:直接指定即可。用户可以通过sysfs中的接口指定该group的shares值,kernel会按照一定的规则将这个shares瓜分到各个cpu的gse上
所以:与其说"shares是所有group se的权重之和",倒不如说"shares被该group下的所有gse所瓜分"
关键字:
-
直接指定group的shares值;
-
将shares值瓜分到各个cpu的gse上;
PS:
group的默认shares是1024,也就是相当于一个1024优先级的进程,(nice值为0)
task的优先级(权重)也是由用户自己指定的
组调度的原理,就是每个group都拥有自己的cfs_rq以及融入上级的gse,从而搭建出一颗se/cfs_rq树,通过tg的shares或者task的权重将所有节点(tg或task)管理起来。关键是,引入了平行于task的调度实体:tg。
5.1.1 怎样找到挂在的节点位置
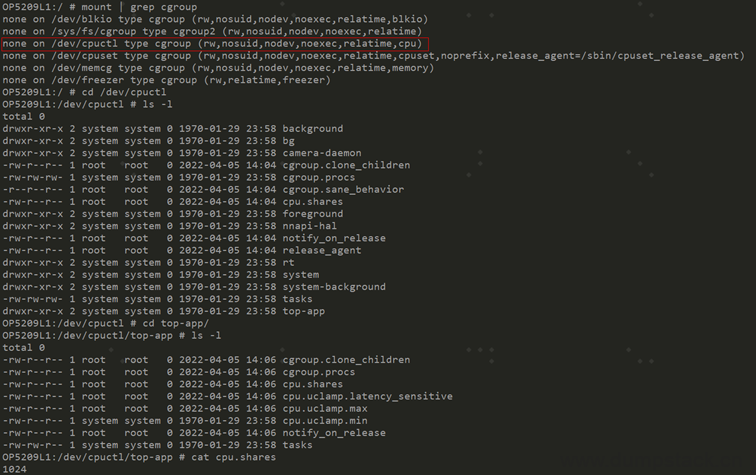
因为组调度的实现依赖于cgroup,所以可以通过下面命令找出导出的节点
注意:执行mount挂载时传入的参数为cpu
|
OP5209L1:/ # mount | grep cgroup none on /dev/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio) none on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime) none on /dev/cpuctl type cgroup (rw,nosuid,nodev,noexec,relatime,cpu) none on /dev/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset,noprefix,release_agent=/sbin/cpuset_release_agent) none on /dev/memcg type cgroup (rw,nosuid,nodev,noexec,relatime,memory) none on /dev/freezer type cgroup (rw,relatime,freezer) |
命令执行截图如下:
5.1.2 方法实现
对节点的操作如下:
文件位置:U:\linux-5.10.61\kernel\sched\core.c
|
static struct cftype cpu_legacy_files[] = { #ifdef CONFIG_FAIR_GROUP_SCHED { .name = "shares", .read_u64 = cpu_shares_read_u64, .write_u64 = cpu_shares_write_u64, }, ... } |
实现如下:
|
static int cpu_shares_write_u64( struct cgroup_subsys_state *css, struct cftype *cftype, u64 shareval) { if (shareval > scale_load_down(ULONG_MAX)) shareval = MAX_SHARES;
//在下面函数中完成设置和瓜分的操作 return sched_group_set_shares(css_tg(css), scale_load(shareval)); }
static u64 cpu_shares_read_u64( struct cgroup_subsys_state *css, struct cftype *cft) { struct task_group *tg = css_tg(css);
return (u64) scale_load_down(tg->shares); } |
5.2.1 计算原理
task_group结构中的shares是这个group的权重,被这个组的在所有cpu上的gse所瓜分
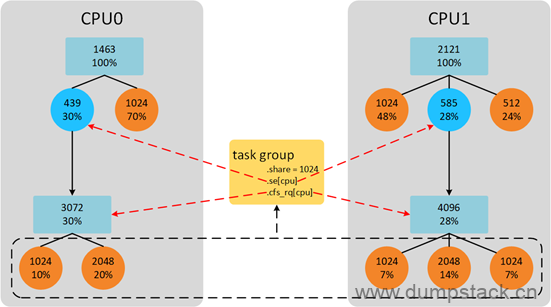
下面我们通过一个示例来说明gse是怎么瓜分shares的,如下图所示,已知group的shares值被指定为1024, cpu0上gse下有2个task se,权重之和是3072,cpu1上group se下有3个task se,权重之和是4096,此时shares将会按照下面规则被瓜分
|
cpu0上group se权重 = 1024*3072/(3072+4096) = 439 cpu1上group se权重 = 1024*4096/(3072+4096) = 585 |
group的权重(shares)可以通过/sys/fs/cgoup/cpu/<group>/cpu.shares节点设置,对该节点的操作如下,需要注意的是:每个cpu上都有一个gse结构,当前gse设置更新完后,会逐层向上对parent组的gse完成更新,直到根节点(根组没有gse结构);
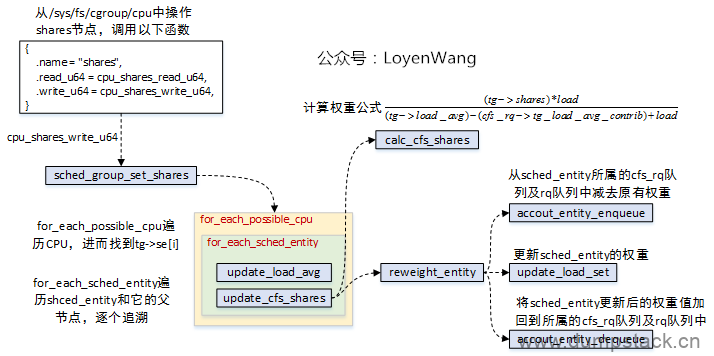
下面场景,在根组下面有一个GroupA,在GroupA下面又有一个GroupB,下面我们通过下面命令修改GroupB的shares值,看看执行流程是什么样的
|
echo XXX > /sys/fs/cgroup/cpu/A/B/cpu.shares |
下图中:
橙色的线代表传入参数指向的对象;
紫色的线代表每次更新涉及到的对象,包括三个部分;
处理完当前gse后,继续按同样的流程处理parent的gse;
下面我们来看看函数实现
|
int sched_group_set_shares( struct task_group *tg, //要对哪个组设置shares unsigned long shares) //要设置的shares的值 { int i; unsigned long flags;
/* * We can't change the weight of the root cgroup. */ //1.根组的group->se结构为NULL,根组的shares是不能修改的 if (!tg->se[0]) return -EINVAL;
//2.uclamp相关,限制shares值不能超过一定的范围 shares = clamp(shares, scale_load(MIN_SHARES), scale_load(MAX_SHARES));
mutex_lock(&shares_mutex); //3.如果shares值没有变化,则不需要重新设置 if (tg->shares == shares) goto done; tg->shares = shares;
//4.因为一个group在所有的cpu上都对应一个group se, // 下面遍历所有的cpu上的group se,完成对shares的瓜分工作 for_each_possible_cpu(i) { struct rq *rq = cpu_rq(i); struct sched_entity *se;
//4.1 获取group在这个cpu上的group se se = tg->se[i]; /* Propagate contribution to hierarchy */ raw_spin_lock_irqsave(&rq->lock, flags);
/* Possible calls to update_curr() need rq clock */ update_rq_clock(rq);
//4.2 从当前group se开始,逐层向上遍历,对所有父group se重新设置shares for_each_sched_entity(se) update_cfs_shares(group_cfs_rq(se)); raw_spin_unlock_irqrestore(&rq->lock, flags); }
done: mutex_unlock(&shares_mutex); return 0; } |
当我们dequeue task、enqueue task以及task tick的时候会通过update_cfs_shargs函数更新group se的权重信息
|
#ifdef CONFIG_FAIR_GROUP_SCHED static void update_cfs_shares( struct cfs_rq *cfs_rq) //这里传入的cfs_rq为group在某个cpu上的cfs_rq结构 { //用于挂载这个group在这个cpu上的所有任务 struct task_group *tg; struct sched_entity *se; long shares;
//1.获取这个grq所属的group tg = cfs_rq->tg;
//2.获取这个grq所属的group的gse se = tg->se[cpu_of(rq_of(cfs_rq))];
//3.下面的和带宽控制相关,暂不分析 if (!se || throttled_hierarchy(cfs_rq)) return;
#ifndef CONFIG_SMP //4.如果这两个值相等的话,则说明这个group下的所有进程,都放在这个grq上了, // 也就是说这个group中的所有进程都在一个cpu上,这时候当然就不需要瓜分了, // 因为所有的线程都在一个cpu上跑,别的cpu上的gse完全不需要cpu运行时间 if (likely(se->load.weight == tg->shares)) return; #endif //5.重新计算这个cfs_rq从tg中瓜分到的shares shares = calc_cfs_shares(cfs_rq, tg);
//6.更新gse的权重 reweight_entity(cfs_rq_of(se), se, shares); } #else static inline void update_cfs_shares(struct cfs_rq *cfs_rq) { } #endif |
5.2.4.1 公式推导原理
由之前我们对group的理解,一个group对应的shares,被这个group在所有cpu上的cfs_rq所瓜分,某一个具体的grq所瓜分到的shares计算方法如下:
|
grq->load.weight shares = tg->shares * ------------------------- (1) \Sum grq->load.weight |
这里插一句,对于上面公式(1),我们考虑到下面两种特殊情况:
-
单核时,即系统中只有一个cpu时,(此时group只有一个grq)
-
多核时,当空闲group刚开始运行一个进程的时候,此时这个group内只有一个线程,并且只有一个cpu上的grq上有线程
此时
|
\Sum grq->load.weight = grq->load.weight |
此时上面的公式(1)转变为如下:
|
grq->load.weight shares = tg->shares * ------------------- = tg->shares grq->load.weight |
下面继续,对于上面公式(1),由于计算\Sum grq->load.weight这个总和开销太大,(因为要遍历每个cpu上的grq下的所有task当cpu和task的数量比较大时,一方面访问其他cpu上的grq造成数据访问竞争激烈,另一方面遍历所有task带来的消耗也是庞大的)。因此我们使用平均负载来做近似处理,如下
|
grq->load.weight ~= grq->avg.load_avg (2) |
将上面公式(2)带入公式(1)得到:
|
grq->load.weight shares = tg->shares * ------------------------- \Sum grq->avg.load_avg
=> grq->load.weight shares = tg->shares * ------------------------- (3) tg->load_avg
Where: tg->load_avg ~= \Sum grq->avg.load_avg |
注意:在继续下面分析时,我们首先要知道如下事实
-
tg->load_avg: 指这个group在所有的cpu上的grq的负载之和
-
grq->tg_load_avg_contrib: 指当前这个grq已经向tg->load_avg贡献的负载。因为tg是一个全局共享变量,多个CPU可能同时访问,为了避免严重的资源抢占,grq负载贡献更新的值并不会立刻加到tg->load_avg上,而是等到负载贡献大于tg_load_avg_contrib一定差值后,再加到tg->load_avg上。例如,2个cpu的系统中,cpu0上的grq初始值tg_load_avg_contrib为0,当grq每次定时器更新负载的时候并不会访问tg变量,而是等到grq的负载grp->avg.load_avg大于tg_load_avg_contrib很多的时候,这个差值达到一个数值(假设是2000),才会更新tg->load_avg为2000。然后,tg_load_avg_contrib的值赋值2000。又经过很多个周期后,grp->avg.load_avg和tg_load_avg_contrib的差值又等于2000,那么再一次更新tg->load_avg的值为4000,这样就避免了频繁访问tg变量。因此,tg->load_avg为这个group在所有cpu上的grq的grq->tg_load_avg_contrib之和
所以上面公式(3)我们可以继续转化为
|
grq->load.weight shares = tg->shares * ------------------------------------------------------------- (4) tg->load_avg + (grq->load.weight - grq->tg_load_avg_contrib) |
PS: 从上面加上的(grq->load.weight - grq->tg_load_avg_contrib)可以看出,这里值考虑了当前cpu上的grq,没有考虑到其他cpu上的grq,实际上也是一个近似值,但是这一句足够了
5.2.4.2 函数实现
|
# ifdef CONFIG_SMP static long calc_cfs_shares( struct cfs_rq *cfs_rq, //这个group在某个cpu上的grq结构 struct task_group *tg) //指向该group { long tg_weight, load, shares;
/* * This really should be: cfs_rq->avg.load_avg, but instead we use * cfs_rq->load.weight, which is its upper bound. This helps ramp up * the shares for small weight interactive tasks. */ load = scale_load_down(cfs_rq->load.weight);
tg_weight = atomic_long_read(&tg->load_avg);
/* Ensure tg_weight >= load */ tg_weight -= cfs_rq->tg_load_avg_contrib; tg_weight += load;
shares = (tg->shares * load); if (tg_weight) shares /= tg_weight;
if (shares < MIN_SHARES) shares = MIN_SHARES; if (shares > tg->shares) shares = tg->shares;
return shares; } # else /* CONFIG_SMP */ static inline long calc_cfs_shares( struct cfs_rq *cfs_rq, struct task_group *tg) { //当只有一个cpu的时候,这个group中的所有task肯定是在一个cfs_rq中 return tg->shares; } # endif /* CONFIG_SMP */ |
5.2.5 reweight_entity - 更新gse的权重
|
static void reweight_entity( struct cfs_rq *cfs_rq, //下面这个gse被挂在那个cfs_rq上 struct sched_entity *se, //要对哪个gse重新设置权重 unsigned long weight) //要设置的新的权重的值 { //1.如果这个gse现在已经被挂在运行队列上, // 则首先需要将这个gse的权重和负载从cfs_rq中移除 if (se->on_rq) { /* commit outstanding execution time */ //1.1 如果这个se是cfs_rq上正在运行的进程,那么他已经不在红黑树中 // 在移除之前需要先更新这个cfs_rq的运行时间信息 if (cfs_rq->curr == se) update_curr(cfs_rq);
//1.2 将gse的权重weight从cfs_rq中删除 account_entity_dequeue(cfs_rq, se); }
//2.重新设置gse的权重信息 update_load_set(&se->load, weight);
//6.因为权重改了,所以这里需要重新将新的权重加到 // cfs_rq->load.weight和cfs_rq->runnable_weight中去 if (se->on_rq) account_entity_enqueue(cfs_rq, se); } |
六、附:组调度时的组织架构
6.1 entity_is_task - 判断这个se结构是不是一个task
如果一个se是gse,则gse->my_q指向对应的grq结构,一定不为空
|
#ifdef CONFIG_FAIR_GROUP_SCHED //当支持组调度的时候,se结构可以表示一个task,也可以表示一个group的节点 //当这个se表示一个task时,se->mq结构为NULL //当这个se表示一个用户组时,se->mq指向gse对应的grq,一定不为空 /* An entity is a task if it doesn't "own" a runqueue */ #define entity_is_task(se) (!se->my_q) #else //当不支持组调度的时候,se结构始终对应着一个task结构 #define entity_is_task(se) 1 #endif |
6.2 group_cfs_rq - 返回gse对应的grq结构
|
#ifdef CONFIG_FAIR_GROUP_SCHED /* runqueue "owned" by this group */ static inline struct cfs_rq *group_cfs_rq(struct sched_entity *grp) { //当支持组调度的时候, //若这个se对应一个group,则这个组对应的grq结构直接记录在my_q成员中 //若这个se对应一个task,则此时的my_q成员直接为NULL return grp->my_q; } #else /* runqueue "owned" by this group */ static inline struct cfs_rq *group_cfs_rq(struct sched_entity *grp) { return NULL; } #endif |
6.3 is_same_group - 判断两个se是否在同一个group中
|
/* Do the two (enqueued) entities belong to the same group ? */ static inline struct cfs_rq * is_same_group( struct sched_entity *se, struct sched_entity *pse) { //如果两个se在同一个group中,则他们对应的grq一定一样 //返回grq结构 if (se->cfs_rq == pse->cfs_rq) return se->cfs_rq;
//不在一个greop时返回NULL return NULL; } |
6.4 cfs_rq_of - 得到这个se被挂在哪个cfs_rq运行队列上
|
#ifdef CONFIG_FAIR_GROUP_SCHED /* runqueue on which this entity is (to be) queued */ //当支持组调度的时候,se结构中会有一个cfs_rq结构,该结构用于指向se所属的cfs运行队列 static inline struct cfs_rq *cfs_rq_of(struct sched_entity *se) { return se->cfs_rq; } #else //若不支持组调度,则se是挂载在"对应的task所在的cpu上的rq结构" static inline struct cfs_rq *cfs_rq_of(struct sched_entity *se) { struct task_struct *p = task_of(se); //由se得到对应的task_struct结构 struct rq *rq = task_rq(p); //得到这个task所在cpu的运行队列
return &rq->cfs; } #endif |
6.5 task_cfs_rq - 得到这个任务p被挂在哪个cfs_rq队列上
|
#ifdef CONFIG_FAIR_GROUP_SCHED static inline struct cfs_rq *task_cfs_rq(struct task_struct *p) { //当支持组调度的时候,虽然每个cpu只包含一个rq,但每个group都会对应 //N个gse和grq结构,(N为cpu的个数,可通过gse->my_q找到对应的grq //结构),这个时候task_rq(p)->cfs指向最顶端的cfs_rq结构,并不是p所 //在的cfs_rq结构,因为p有可能被挂在grq上,为了解决这个问题,在支持组 //调度的时候,内核在se中新增一个cfs_rq成员,用于记录当前这个se所属的cfs_rq return p->se.cfs_rq; } #else static inline struct cfs_rq *task_cfs_rq(struct task_struct *p) { //当不支持组调度的时候,一个cpu上只有一个rq,在这个rq中只有一个cfs_rq, //此时,直接获取当前cpu上的运行队列runqueues,并从中提取出cfs_rq队列, //这就是任务p所在的cfs队列 return &task_rq(p)->cfs; } #endif |
6.6 task_of - 由se返回对应的task_struct结构
|
#ifdef CONFIG_FAIR_GROUP_SCHED //当支持组调度的时候,需要判断这个se到底表示啥玩意 static inline struct task_struct *task_of(struct sched_entity *se) { //首先判断这个se结构到底是表示一个task,还是表示一个group的节点 //如果是一个group节点,则会产生一个警告,如果表示一个task,则返回这个task对应的task_struct SCHED_WARN_ON(!entity_is_task(se)); return container_of(se, struct task_struct, se); } #else //当不支持组调度的时候,直接返回se所属的task_struct结构 static inline struct task_struct *task_of(struct sched_entity *se) { return container_of(se, struct task_struct, se); } #endif |
6.7 rq_of - 已知运行队列cfs_rq,返回其所属的rq结构
|
#ifdef CONFIG_FAIR_GROUP_SCHED /* cpu runqueue to which this cfs_rq is attached */ //当支持组调度的时候,因为cfs_rq可能包含在rq结构,也可能包含在se结构中 //所以不能通过container_of获取最外层的rq结构 //幸运的是,当开启组调度的时候,cfs_rq结构中会存在一个rq成员, //这个成员就是用于标记这个cfs_rq属于哪一个运行队列rq static inline struct rq *rq_of(struct cfs_rq *cfs_rq) { return cfs_rq->rq; } #else //当不支持组调度的时候,cfs_rq直接包含着rq结构中 static inline struct rq *rq_of(struct cfs_rq *cfs_rq) { return container_of(cfs_rq, struct rq, cfs); } #endif |
6.8 parent_entity - 返回se的父节点
|
#ifdef CONFIG_FAIR_GROUP_SCHED //当支持组调度的时候,se是有层级关系的,此时返回父节点对应的se static inline struct sched_entity *parent_entity(struct sched_entity *se) { return se->parent; } #else //不支持组调度的时候,se全部挂载运行队列上,没有层级关系,此时直接返回NULL static inline struct sched_entity *parent_entity(struct sched_entity *se) { return NULL; } #endif |
6.9 for_each_sched_entity - 支持组调度的时候,逐层遍历祖先的gse结构
支持组调度时,调度实体是有层次结构的,例如当我们将进程加入的时候,同时要更新其父调度实体的调度信息
而非组调度情况下,就不需要调度实体的层次结构
|
#ifdef CONFIG_FAIR_GROUP_SCHED /* Walk up scheduling entities hierarchy */ //当支持组调度的时候,se结构中会存在一个parent变量, //这个变量指向"这个用户组在这个cpu上的节点对应的se结构" //当只有两层的时候,这时的遍历实际就遍历了两个se结构,即当前se和group在当前cpu上的节点对应的se //当有多层的时候,会层层向上遍历 #define for_each_sched_entity(se) \ for (; se; se = se->parent) #else //当不支持组调度的时候,这个时候的遍历实际就遍历了一个se结构,即se本身 #define for_each_sched_entity(se) \ for (; se; se = NULL) #endif |
6.10 find_matching_se - 层层向上,直到这两个se在同一个cfs_rq树中,也就是说在同一个组中
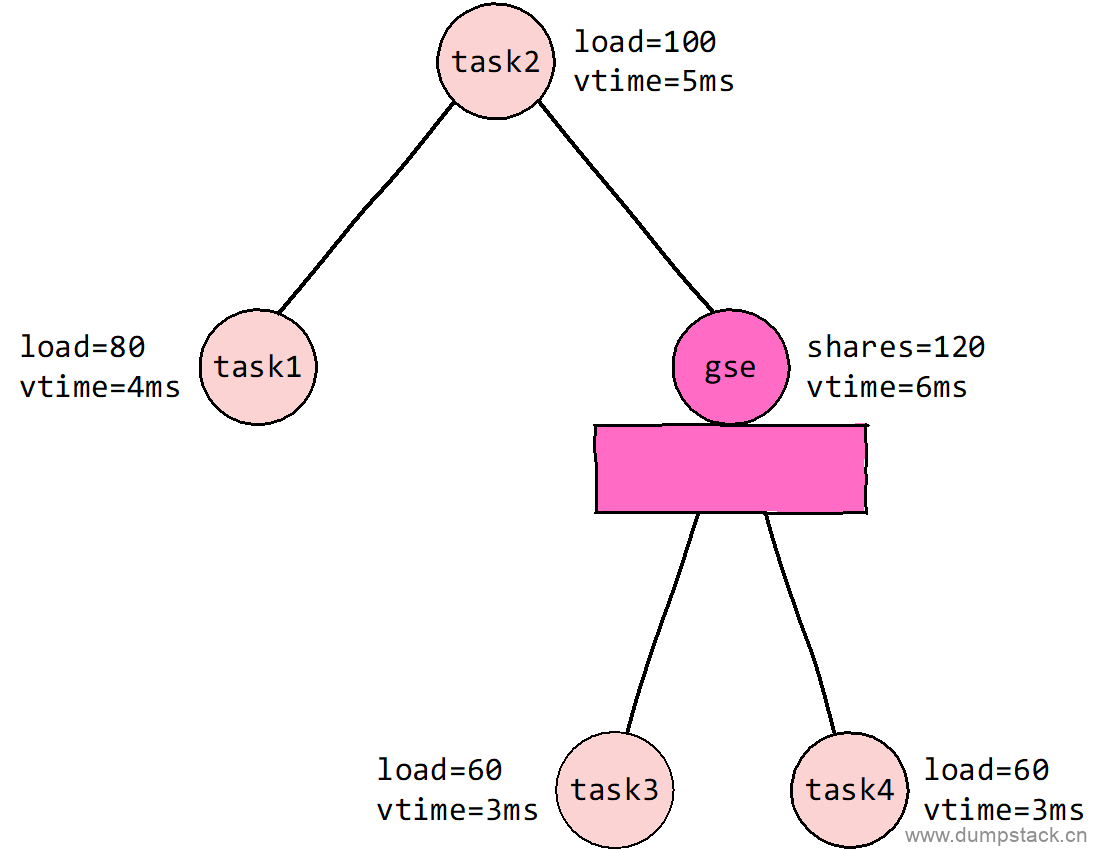
find_matching_se将两个se对齐到同一颗cfs_rq红黑树下,为什么要这么做呢?下面通过一个示例来分析,如下图所示,已知系统中共有4个task,其中task3和task4属于一个group,我们已知如下信息:
-
各个task se/group se的load/shares值;
-
一个调度周期为15ms;
则在经过一个调度周期之后,各个se的虚拟运行时间可经过运算得到具体的值,如下图所标记。
此时如果要对比task1和task3之间的虚拟运行时间,难道只直接对比吗?如果那样的话,因为task3_vtime < task1_vtime,所以task3将是最先运行的。
实际上并不是这样,在对比之前,首先task3要向上遍历到gse,然后对比task1_vtime和gse_vtime的时间,此时显然task1_vtime < gse_vtime,因此task1要先运行
可见上面两个方法会得到截然不同的结果,我们应该将group当成一个整体来进行调度
一般在对比两个se的虚拟运行时间的时候之前会执行该操作,因为当两个se不在同一个cfs_rq中的时候,也就是说不在同一颗红黑树的时候,对比着两个se的虚拟运行时间时没有任何意义的,因此在对比其虚拟运行时间之前,一定要将他俩搞到同一颗树上
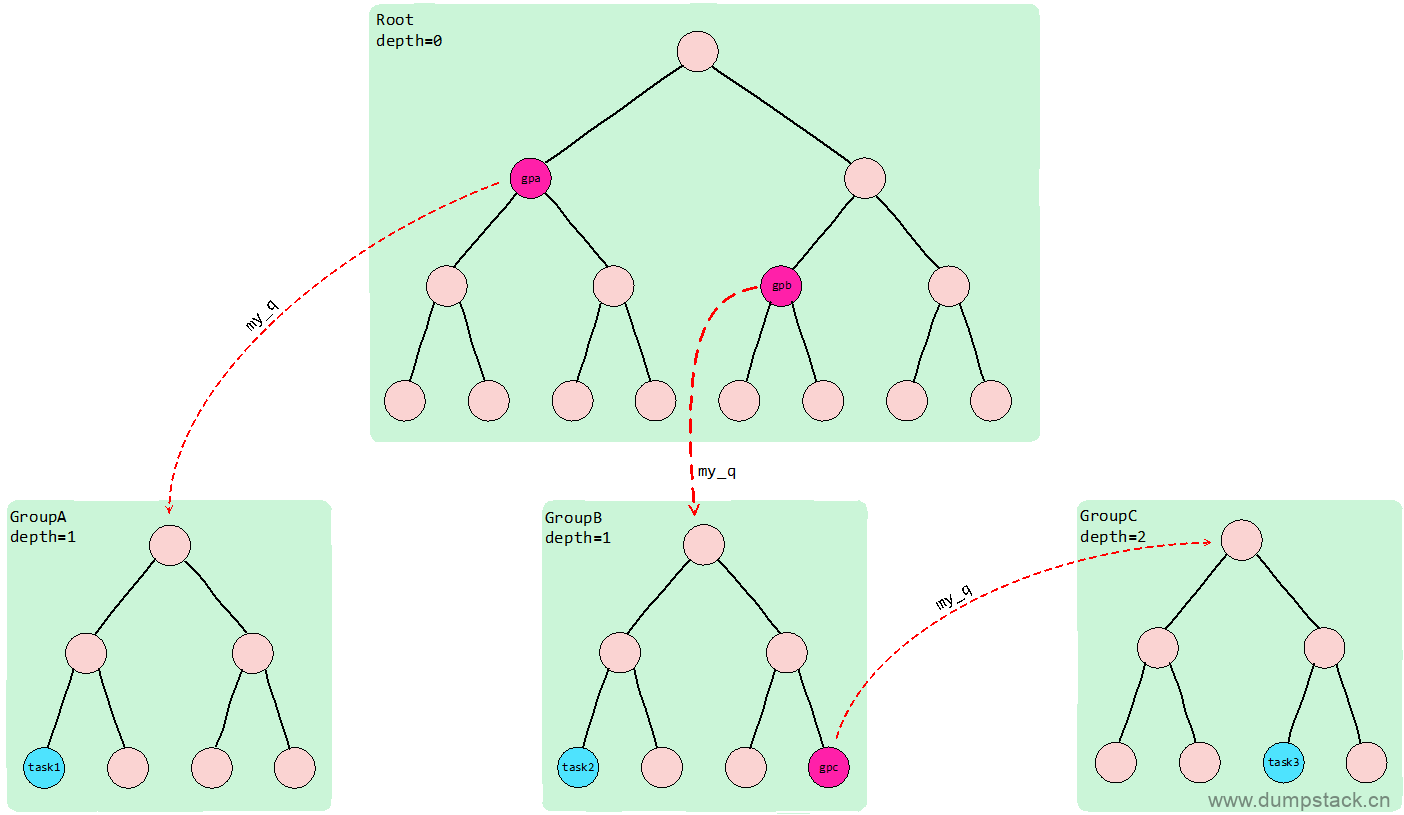
当支持组调度的时候,se之间的拓扑关系如下图所示,由下面函数中的注释可知,该函数的作用是层层向上遍历,直到这两个se在同一个cfs_rq树中
-
若该函数传入的se和pse分别对应下面图中的task1和task2结构,则经过find_matching_se后,se为gpa,pse对应gpb
-
若该函数传入的se和pse分别对应下面图中的task1和task3结构,则经过find_matching_se后,se为gpa,pse对应gpb
-
若该函数传入的se和pse分别对应下面图中的task2和task3结构,则经过find_matching_se后,se为task2,pse对应gpc
|
#ifdef CONFIG_FAIR_GROUP_SCHED //当支持组调度的时候,se是有层级关系的,此时两个se可能会存在共同的祖先 static void find_matching_se( struct sched_entity **se, struct sched_entity **pse) { int se_depth, pse_depth;
/* * preemption test can be made between sibling entities who are in the * same cfs_rq i.e who have a common parent. Walk up the hierarchy of * both tasks until we find their ancestors who are siblings of common * parent. */
/* First walk up until both entities are at same depth */ //1.首先结果下面的两个while循环,使得两个se在"同一层" se_depth = (*se)->depth; pse_depth = (*pse)->depth;
while (se_depth > pse_depth) { se_depth--; *se = parent_entity(*se); }
while (pse_depth > se_depth) { pse_depth--; *pse = parent_entity(*pse); }
//2.层层向上,直到这两个se在同一个group,变成了兄弟 while (!is_same_group(*se, *pse)) { *se = parent_entity(*se); *pse = parent_entity(*pse); } } #else //不支持组调度的时候,se全部挂载运行队列上,没有层级关系,此时也不会存在共同的祖先 static inline void find_matching_se(struct sched_entity **se, struct sched_entity **pse) { } #endif |

文章评论